






MR模型编程概述
MR编程模型是hadoop中提供的计算框架,在hadoop1和hadoop2中基本类似,没有进行大的架构改动。适合场景:任务可以被分解成为相互独立的子问题。MR框架将问题分解为下列5个步骤来解决问题:
1. 迭代(iterator)。遍历输入数据,并将之解析为key/value对。
2. 将输入的key/value对映射(map)为另外一些的key/value对。
3. 依据key对中间数据进行分组(grouping)和排序(sorting)
4. 以组为单位对数据进行归约(reduce)操作
5. 迭代。将最终产生的key/value对进行输出操作,保存到文件中。
MR编程模型图
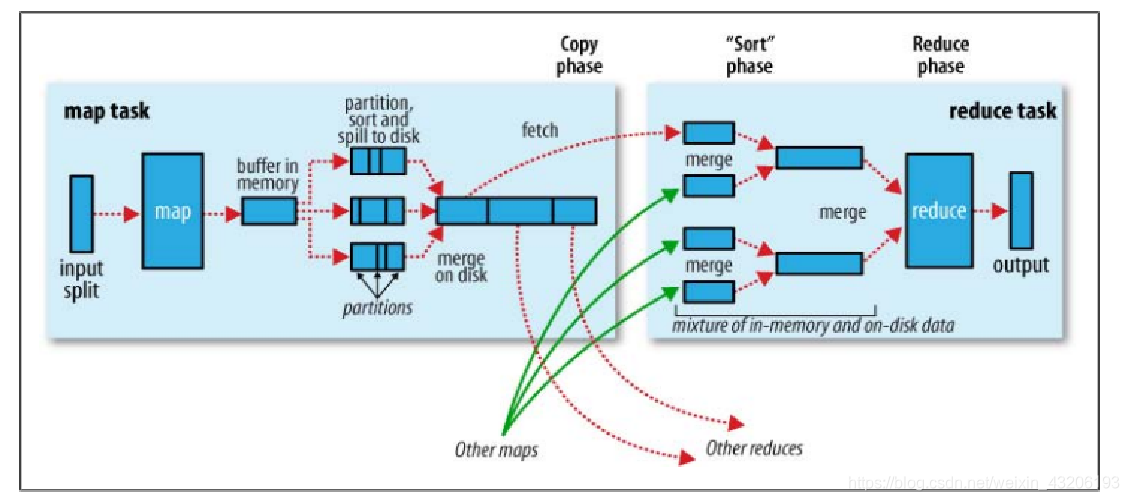
MR任务根据InputFormat来决定Map Task的个数,并将数据传递给用户定义的map方法中,Map Task执行完成后,将中间结果写出到Map Task运行机器的本地文件系统中,并通知ApplicationMaster该Map Task已经完成,当Map Task的完成比率达到5%的时候,Reduce Task开始拉取完成的Map Task节点的数据,在拉取完所有的Map Task数据后,进入用户定义的reduce方法进行数据处理,将处理完的<key,value>键值对进行输出操作。
默认情况下,Map Task的个数就是InputFormat来决定;Reduce Task的个数由用户来决定,默认为1个。
shuffle介绍
MR编程模型中的shuffle阶段主要包括map阶段的数据输出以及reduce阶段的数据输入这两个部分,包括shuffle数据map端写出策略、数据merge策略、reduce端数据拉取策略等。MR编程模型中shuffle机制的主要功能作用是将数据进行排序、分组、分区,让不同的reduce task处理属于该task的数据。类似于Java API中的Collections.shuffle(list)方法,其作用都是讲数据混淆。由于shuffle过程中涉及到从reduce task节点通过http拉取map task的执行结果,那么必然就需要一部分正常的网络开销和磁盘IO开销。那么我们对于shuffle阶段的主要期望就是:降低网络开销、减少磁盘IO对其他task的影响、获取完整的结果数据。
Map端shuffle介绍
Map端的shuffle主要功能是将map方法输出的<key,value>键值对最终输出到map task节点的本地文件系统的一个文件中,让reduce task获取。主要涉及到write to memory buffer(写出到内存缓存)、combin(合并/归并<可选>)、partition(分区)、sort(排序)、write to disk file(写出到磁盘文件)以及merge disk file(合并磁盘文件)。将这些动作进行合并后,主要包括三个步骤:
1. 写出到内存缓存
2. 内存数据溢出到磁盘文件
3. 合并溢出的磁盘文件到一个磁盘文件
map端shuffle过程
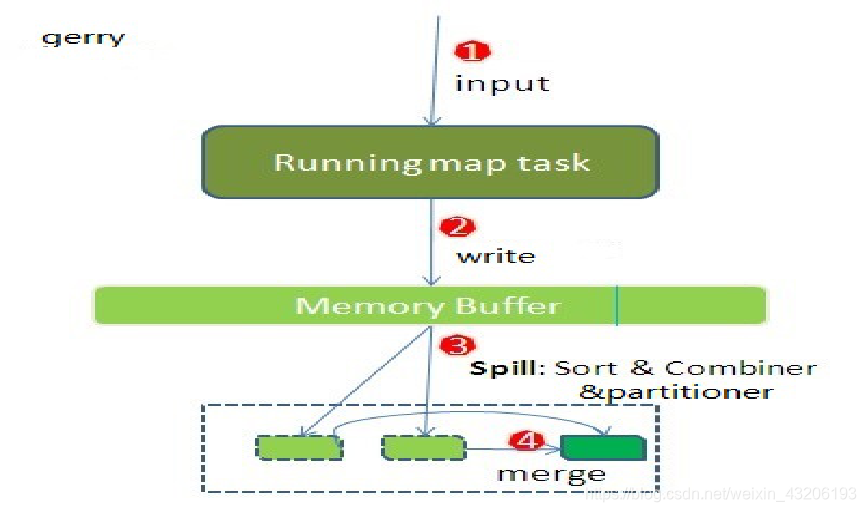
map端shuffle–写出到内存缓存
Map端内存中有个环形的内存缓存结构体,该结构体的内存大小由参数mapreduce.task.io.sort.mb控制,默认大小为100MB,当map输出数据的时候,第一步就是将数据添加到memory buffer中,该memory buffer是一个环形的内存缓存区,当写入容量达到80%(默认)的时候,会触发溢出操作,触发溢出操作的时候会将已经写入的缓存区锁住,同时map task允许往剩下的缓存区中写入数据。也就是说当触发溢出操作的时候,不会阻塞map task的继续写出操作。其中控制阀值的是参数mapreduce.map.sort.spill.percent,默认值0.8。
map端shuffle–溢出到磁盘文件
当map端的内存缓存区达到阀值的时候,会触发溢出操作,每次溢出操作都会在磁盘中生成一个磁盘文件。在触发溢出操作的时候,会同时触发<key,value>键值对的combiner、partitioner以及sort三种操作,也就是说写出到磁盘的文件是进行合并后的,排序好的,按照reduce分区好的数据文件。在这个过程中,可能会触发多次combiner操作。当执行完Spill操作后,磁盘中会多一个数据文件,同时会将环形内存缓存写出数据部分进行清空操作,允许map task往这部分填写数据。
##map端shuffle–归并溢出文件
当map task执行完成后,会执行溢出文件归并操作,通过combiner、partitioner以及sort操作,最终将多个溢出文件以及内存中没有溢出的数据写出到一个本地磁盘文件中,这个磁盘文件就包含了该map task输出的所有结果,也就是说包含了到所有reducer节点的数据。就是指将输出到多个reducer节点的数据保存到同一个文件中,同时保存一个reducer节点到文件内容的偏移量的一个索引文件,只所以不采用一个reducer对应一个文件的方式,是因为如果一个大的集群有很多个reducer task节点,那么最终每个map task执行完成后,都会产生多个本地文件,不好维护。
map端shuffle–通知am
当map task节点完成数据写出操作后(最终产生一个磁盘文件后),map task正式完成,同时通知ApplicationMaster服务,完成map task,并告诉application master服务,最终数据保存文件地址信息。当完成的map task数量达到百分之五的时候,会启动reducer task任务。控制参数为mapreduce.job.reduce.slowstart.completedmaps,默认值0.05。
reduce端shuffle介绍
Reduce端的shuffle主要功能是将该reduce task节点需要处理的所有map端输出数据拉取过来,然后通过排序和合并操作,形成输入到reduce方法的<key,Iterator<value>>的键值对形式的数据。主要包括以下三个步骤:
1. copy
2. spill & merge & sort
3. group
Reduce端的shuffle操作指定类由参数指定,默认为Shuffle.class类。可以通过参数mapreduce.job.reduce.shuffle.consumer.plugin.class指定。
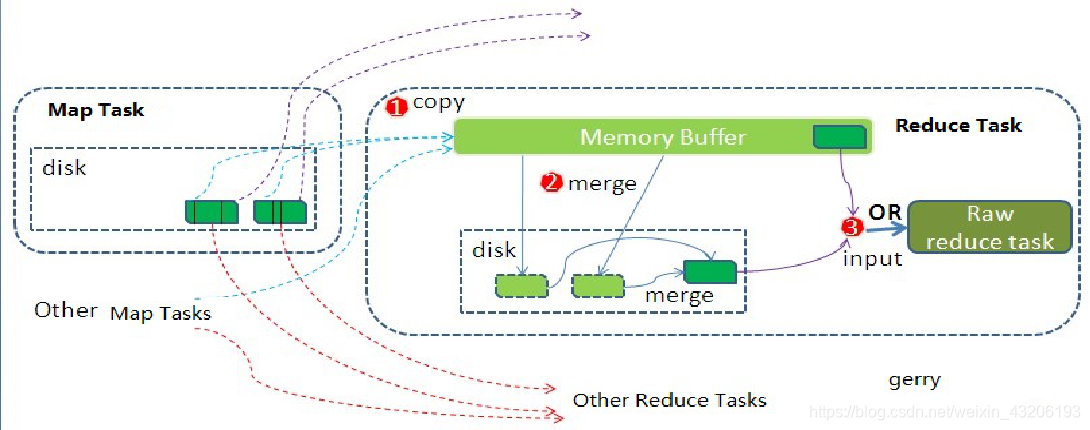
reduce端shuffle–copy
根据已经完成的map信息生成Fetcher线程组,Fetcher线程组的数量由参数mapreduce.reduce.shuffle.parallelcopies控制,默认为5个。启动好Fetcher线程后,就开始从远程map task节点通过HttpURLConnection获取流来读取数据,并将数据先写到内存中,内存不够(75%)的时候再溢出到磁盘中,内存大小是reduce task当前堆大小。不受用户参数控制,只所以选择使用当前堆大小作为内存大小,是因为此时reduce task不会进行任何任何其他操作,不需要额外的内存空间。
**
reduce端shuffle–spill&merge&sort
**
和map端的溢出操作类型,reduce端在进行copy的时候由于内存不够,会进行溢出操作,在这个过程中会触发sort和merge操作,最终会产生一个磁盘文件(可能存在于内存中)。reduce端的merge操作有三种方式:内存到内存、内存到磁盘、磁盘到磁盘。默认情况下第一种方式是没有开启的,当内存容量不够的时候,会启动第二种方式,然后一直处于运行状态,直到map端数据全部拉取完成,最后会启动第三种方式进行归并操作。
**
reduce端shuffle–group
当reduce进行完merge操作后,会有一个数据文件存放到本地磁盘系统中或者内存中,为下一步reduce方法的执行提供数据,在提供数据的时候,每次获取数据的时候,会判断下一个key是否和当前key一直,通过group comparable来进行比较,如果一致,认为属于同一组key,那么在同一组中进行处理,否则直接结束当前组的处理,新起一个组来进行reduce方法的调用。














 1292
1292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









