







 本文介绍了关联规则挖掘的基础知识,包括Apriori算法和FP-Growth算法。关联规则用于发现商品之间的关联性,如沃尔玛的啤酒与尿布案例。Apriori算法通过频繁项集和置信度计算规则,而FP-Growth通过构建FP树减少计算量。文中提供了Python实现示例,展示了如何挖掘数据集中的关联规则,并讨论了不同算法的效率对比。
本文介绍了关联规则挖掘的基础知识,包括Apriori算法和FP-Growth算法。关联规则用于发现商品之间的关联性,如沃尔玛的啤酒与尿布案例。Apriori算法通过频繁项集和置信度计算规则,而FP-Growth通过构建FP树减少计算量。文中提供了Python实现示例,展示了如何挖掘数据集中的关联规则,并讨论了不同算法的效率对比。
前言
关联分析算法,是一种无监督的学习方法,算法的核心思想就是找出一些相关系的物品。如不最著名的啤酒与尿布湿的案例,我就很纳闷,也很疑惑,为什么一上数据挖掘课,老师必讲解啤酒与尿布!

这里有一个题外话!
题外话:但部分人都发现啤酒和尿不湿在沃尔玛超市的神器结合与连摆销售模式,但是对于一个超市来讲,个人认为在摆货架的时候,并非是将啤酒和尿布摆放在一个货架上,原因很简单。因为超市是一个大型购物中心,里面的商品玲琅满目,这其实对决策者来讲应该逆向思维!
逆向思维:怎么说呢?假设我们不将啤酒与尿布摆设在一个架子上,取超市的对角线(因为距离最长)如果购买啤酒+尿布的组合,购买者必然穿过最长的距离,也就是停留在超市的时间更长,浏览到的物品更多!这是否更有利于超市的商品营销?
所以,笔者认为!将尿布设置在啤酒对角线的最远端可能更为可靠!

扯远了拉回来
这篇文章的目的是关联规则,我们只需要通过算法得出商品(物品)之间的关联规则即可。数据挖掘在商业运作中的价值,是需要具备一定的商业运营素养才能达到的。购物篮分析(apriori)算法进已经是很成熟的技术了
算法原理
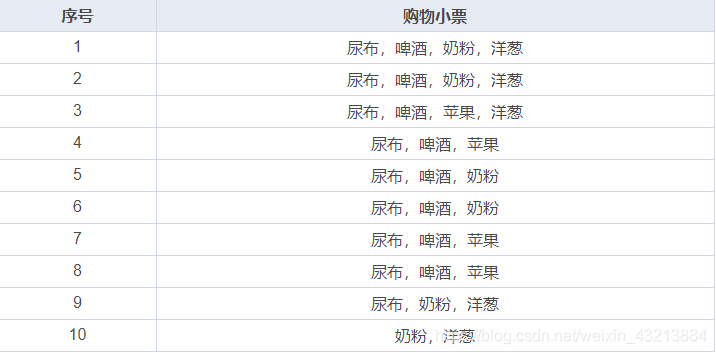
为了更加形象和具体,先构造这么一个数据集
基本概念
-
项集(item set):表示单个的项,或者一系列项目的合集。比如上述的啤酒和尿布就是项目,一张购物小票(横向看)就是一个项集,我们经常说的啤酒和尿布组合就是一个“频繁项集”。
-
关联规则:是最后算法出的结果,比如{尿布}----->{啤酒},前者是先导,后者是后继
-
支持度: 支持度就是一个项集在数据中出现的比例 支 持 度 ( 尿 布 ) = 尿 布 出 现 次 数 / 购 买 小 票 的 数 量 = 0.89 支持度(尿布)=尿布出现次数/购买小票的数量=0.89 支持度(尿布)=尿布出现次数/购买小票的数量=0.89
-
置信度:出现先导也出现后继的比例
置 信 度 ( 尿 布 — > 啤 酒 ) = [ 支 持 度 ( 尿 布 + 啤 酒 ) / 支 持 度 ( 尿 布 ) ∗ 支 持 度 ( 啤 酒 ) ] = 1.1 置信度(尿布—>啤酒)=[支持度(尿布+啤酒)/支持度(尿布)*支持度(啤酒)]=1.1 置信度(尿布—>啤酒)=[支持度(尿布+啤酒)/支持度(尿布)∗支持度(啤酒)]=1.1 -
提升度: 在置信度中,只考虑了规则中的先导与后继同时发生的情况,而对于后继单独发生的情况没有加以考虑。所以又有人提出了一个提升度,用来衡量先导和后继的独立性。比如在前面我们算出“尿布→啤酒”的置信度为 0.89,这说明买了“尿布”的人里有 89% 会买“啤酒”,这看起来已经很高了。但是如果在没有买“尿布”的购物小票中,购买“啤酒”的概率仍然为 0.89,那其实购买“尿布”和购买“啤酒”并没有什么关系。所以,提升度的计算公式如下:

-
确信度:对于一条规则,不发生先导而发生后继的概率与这条规则错误的概率比值

这说明该条规则是真的概率比它只是偶然发生的概率高 82%。
Apriori算法
其目的和思想很简单,核心思想:如果某个项集是频繁项集,那么它的全部子集也都是频繁项集。
第一步:找出频繁项集
第二步:从频繁项集中提取规则
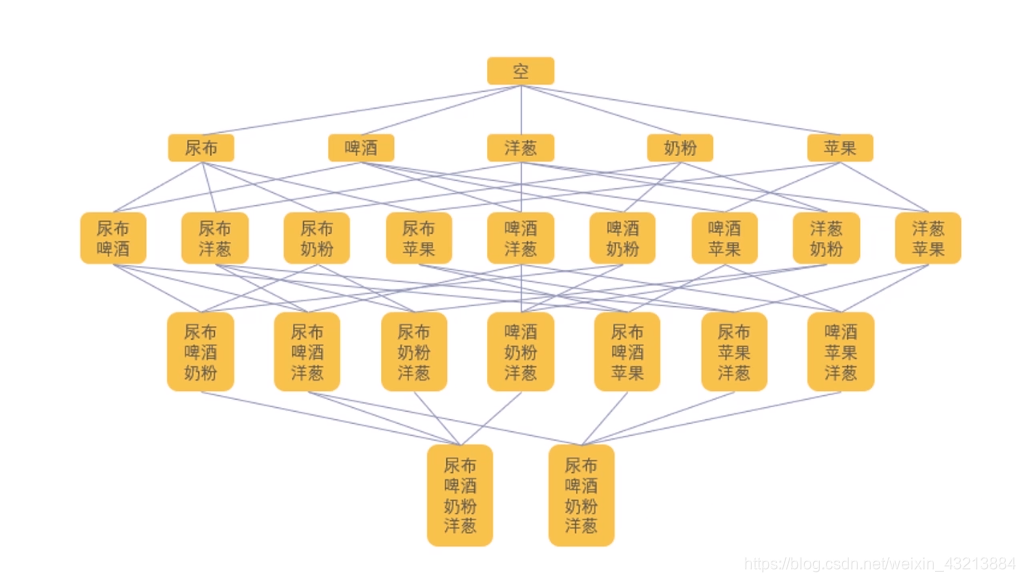
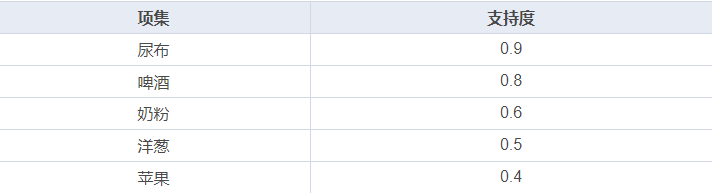
首先,需要设定一个最小支持度阈值,假设我们设定为 0.5,那么高于 0.5 的就认为是频繁项集。然后,我们计算出所有单个商品的支持度,如下表所示:
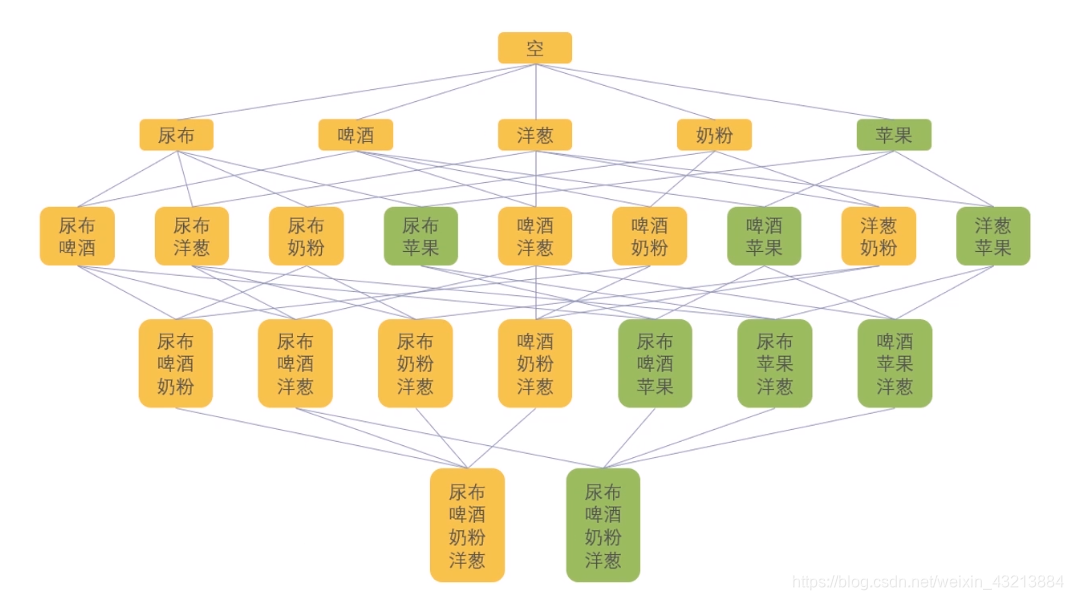
从这里可以看出,“苹果”的支持度达不到阈值,于是把它删掉。因此,所有跟“苹果”相关的父集也都是低频的,在后续的计算也不会涉及了,就是下图标绿色的这些。
接下来我们再计算二阶的项集支持度。
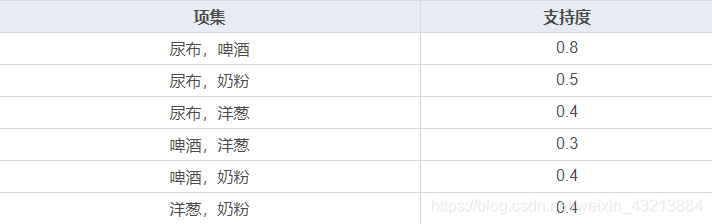
到了这一步,后四个项集的支持度已经达不到我们的阈值 0.5,于是也删掉。
接下来再计算三阶的项集支持度,这个时候发现已经没有可用的三阶项集了,所以算法计算结束。这时候我们得到了三组频繁项集 {尿布,啤酒}、{尿布,洋葱}、{尿布,奶粉}。
接下来从这三个频繁项集,我们可以得到三个关联关系:尿布→啤酒,尿布→洋葱,尿布→奶粉。根据前面的公式,分别计算这三个关系的置信度、提升度和确信度。
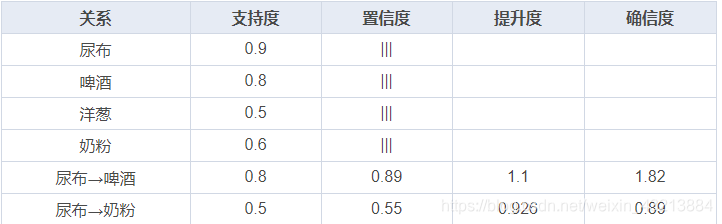
到了这里,再根据我们的需求设定阈值来筛选最终需要留下来的规则。
FP-Growth(Frequent Pattern Growth)
为了克服apriori计算量大的缺点,我们提出更为高效的算法FP-Growth
Apriori 算法一开始需要对所有的规则进行枚举,然后再进行计算,而 FP-Growth 则是首先使用数据生成一棵 FP-Growth 树,然后再根据这棵树来生成频繁项集。下面我们来看一下如何构建 FP 树。
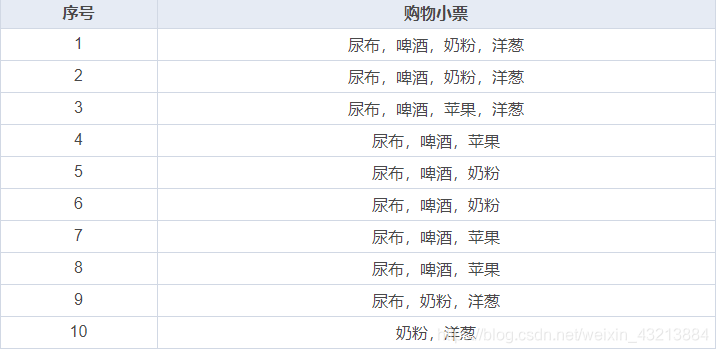
第一步:
将第一个小票数据输入:
得到这样的树
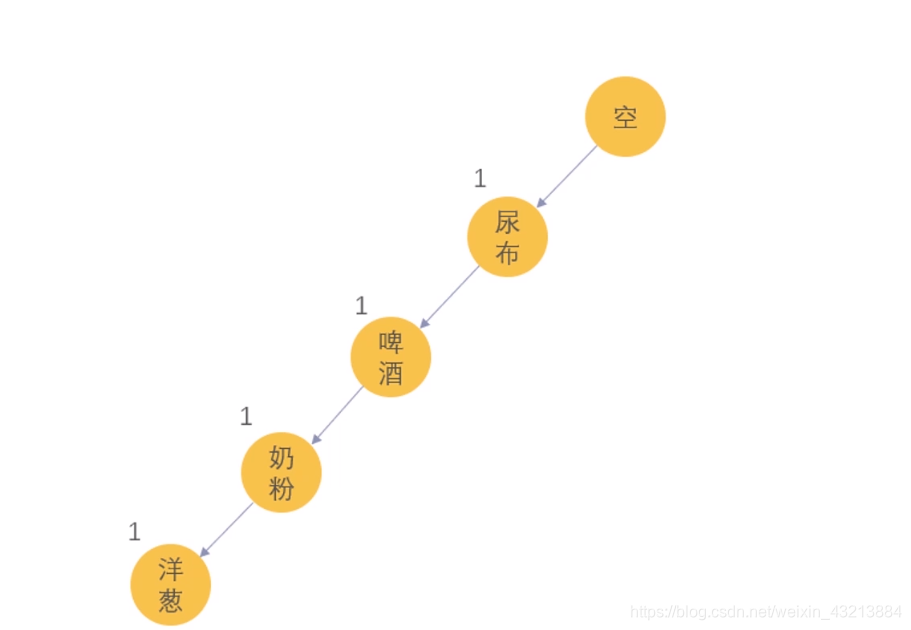
解释:空为根节点,数字1表示小票第一条出现的次数,其次顺序也不能改变。
第二步:输入第二张小票数据和第三张小票数据,第二张小票只是在节点的数字增加1,第三条则从啤酒生成1项的苹果,也由苹果生成了洋葱1
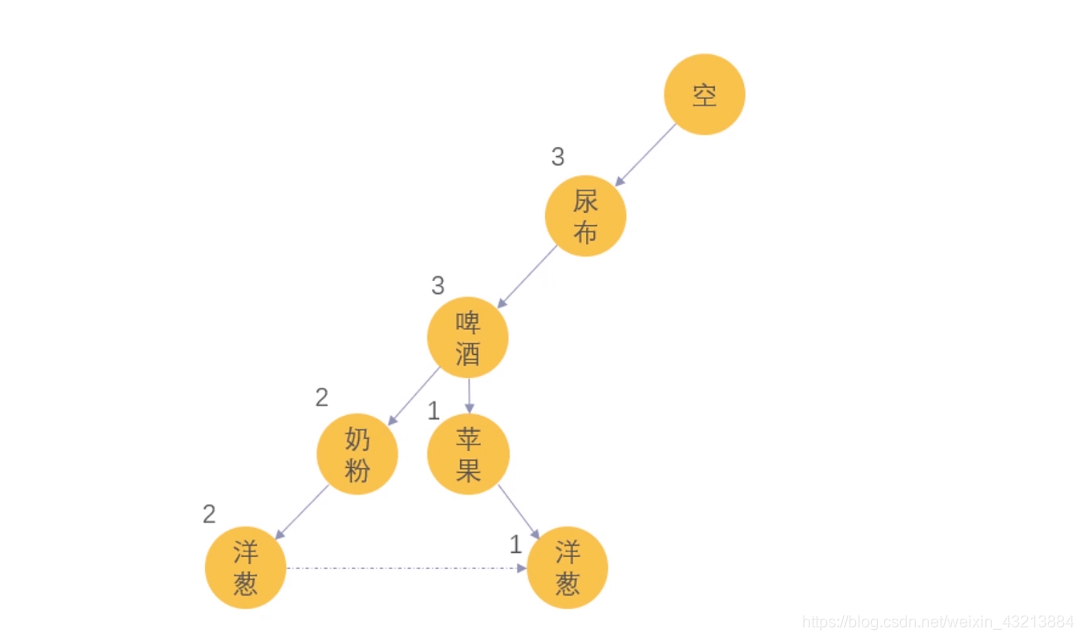
第三步:当把所有的数据输入完毕,得到如下的图
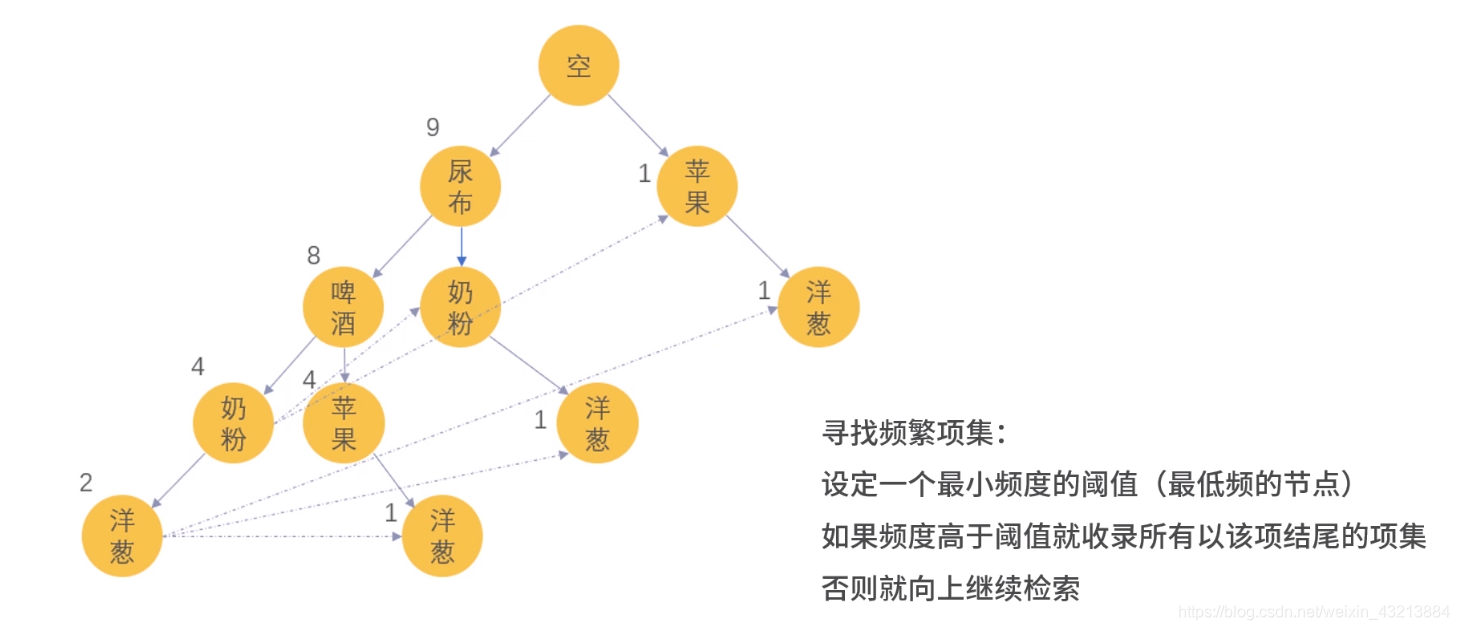
'''记得安装包
pip install efficient-apriori
'''
from efficient_apriori import apriori
# 设置数据集
data = [('尿布', '啤酒', '奶粉','洋葱'),
('尿布', '啤酒', '奶粉','洋葱'),
('尿布', '啤酒', '苹果','洋葱'),
('尿布', '啤酒', '苹果'),
('尿布', '啤酒', '奶粉'),
('尿布', '啤酒', '奶粉'),
('尿布', '啤酒', '苹果'),
('尿布', '啤酒', '苹果'),
('尿布', '奶粉', '洋葱'),
('奶粉', '洋葱')
]
# 挖掘频繁项集和规则
itemsets, rules = apriori(data, min_support=0.4, min_confidence=1)
print(itemsets)
print(rules)
#输出结果
{1: {('奶粉',): 6, ('洋葱',): 5, ('尿布',): 9, ('啤酒',): 8, ('苹果',): 4}, 2: {('啤酒', '奶粉'): 4, ('啤酒', '尿布'): 8, ('奶粉', '尿布'): 5, ('奶粉', '洋葱'): 4, ('尿布', '洋葱'): 4, ('啤酒', '苹果'): 4, ('尿布', '苹果'): 4}, 3: {('啤酒', '奶粉', '尿布'): 4, ('啤酒', '尿布', '苹果'): 4}}
[{啤酒} -> {尿布}, {苹果} -> {啤酒}, {苹果} -> {尿布}, {啤酒, 奶粉} -> {尿布}, {尿布, 苹果} -> {啤酒}, {啤酒, 苹果} -> {尿布}, {苹果} -> {啤酒, 尿布}]
#把min_support设置成0.5输出结果
{1: {('尿布',): 9, ('奶粉',): 6, ('啤酒',): 8, ('洋葱',): 5}, 2: {('啤酒', '尿布'): 8, ('奶粉', '尿布'): 5}}
[{啤酒} -> {尿布}]



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











