







 文章详细介绍了使用Stata进行计量分析的步骤,包括数据准备、描述性统计、可视化、单变量和多变量分析、模型诊断及结果解释。同时,作者分享了在数据导入、模型选择和共线性诊断等方面遇到的问题及解决方案,强调了Stata在社会科学、经济学等领域的应用价值。
文章详细介绍了使用Stata进行计量分析的步骤,包括数据准备、描述性统计、可视化、单变量和多变量分析、模型诊断及结果解释。同时,作者分享了在数据导入、模型选择和共线性诊断等方面遇到的问题及解决方案,强调了Stata在社会科学、经济学等领域的应用价值。
我以为我能逃过stata的“魔爪”,但这工具整的好用,入手也简单
文章目录
前言
Stata是一种统计分析软件,它在社会科学、医学、公共卫生、经济学、金融等领域广泛应用。作为一名研究生,你需要使用Stata来进行数据分析、建模和预测等工作。Stata具有易于使用的界面、强大的数据管理和分析功能、广泛的统计方法和模型、丰富的图形展示等优点,使得它成为研究生进行数据分析的重要工具之一。此外,Stata也是学术论文中常用的统计分析软件之一,因此熟练掌握Stata对于研究生的学术研究和未来的职业发展都非常重要。
stata做计量分析的步骤
-
数据准备:将数据导入Stata,检查数据的质量和完整性,进行数据清洗和转换。
-
描述性统计分析:使用Stata进行描述性统计分析,包括变量的分布、频率、均值、标准差等。
-
可视化分析:使用Stata进行可视化分析,包括绘制直方图、散点图、箱线图等,以便更好地理解数据。
-
单变量分析:使用Stata进行单变量分析,包括t检验、ANOVA、卡方检验等,以检验变量的差异性和相关性。
-
多变量分析:使用Stata进行多变量分析,包括回归分析、方差分析等,以探究变量之间的因果关系和影响因素。
-
模型诊断:使用Stata进行模型诊断,包括残差分析、多重共线性检验、异方差性检验等,以评估模型的拟合度和可靠性。
-
结果解释和报告:根据分析结果进行解释和报告,包括表格、图表、文字说明等。
每个步骤对应的代码
1.数据准备
导入数据:使用命令use或import导入数据
- 1.导入数据:使用命令use或import导入数据。
use "C:\data\mydata.dta", clear
- 2.检查数据:使用命令describe或codebook检查数据的变量名、类型、标签等信息。
describe var1 var2 var3
*3.数据清洗:使用命令drop、replace、generate等进行数据清洗和转换。
drop if var1==.
replace var2=0 if var2<0
generate var4=var2+var3
2.描述性统计分析
- 1.变量分布:使用命令histogram、graph box、summ等进行变量分布的统计和可视化。
histogram var1
graph box var2
summ var3
- 2.变量频率:使用命令tabulate或tabstat进行变量频率的统计和分组。
tabulate var4
tabstat var5, by(var6)
- 3.变量描述:使用命令label variable、notes、codebook等为变量添加描述信息。
label variable var7 "年龄"
notes var8: "0代表女性,1代表男性"
codebook var9
3.可视化分析
- 1.直方图:使用命令histogram绘制变量的直方图。
histogram var1
- 2.散点图:使用命令scatter绘制变量之间的散点图。
scatter var2 var3
- 3.箱线图:使用命令graph box绘制变量的箱线图。
graph box var4
4.单变量分析
- 1.t检验:使用命令ttest进行单样本或双样本的t检验。
ttest var1==0
ttest var2, by(var3)
- 2.ANOVA:使用命令anova进行单因素或多因素的ANOVA分析。
anova var4 var5 var6
anova var7 var8, by(var9)
- 3.卡方检验:使用命令tabulate进行卡方检验。
tabulate var10 var11, chi2
5.多变量分析
- 1.回归分析:使用命令regress或xtreg进行线性回归或面板数据回归分析。
regress var1 var2 var3
xtreg var4 var5 var6, fe
- 2.方差分析:使用命令anova或xtmixed进行单因素或多因素的方差分析。
anova var7 var8 var9, by(var10)
xtmixed var11 var12 || var13:, mle
- 3.其他分析:Stata还提供了多种其他的分析命令,如logistic、probit、poisson等。
logistic var14 var15 var16
probit var17 var18 var19, robust
poisson var20 var21 var22, offset(var23)
6.模型诊断
- 1.残差分析:使用命令predict和rvfplot进行残差的预测和可视化。
predict resid, residuals
rvfplot resid
- 2.多重共线性检验:使用命令collin或vif进行多重共线性检验。
collin var1-var5
vif var6-var10
- 3.异方差性检验:使用命令hettest或robust进行异方差性检验。
hettest var11
regress var12 var13 var14, robust
7.结果解释和报告
- 1.表格输出:使用命令tabout、esttab、outreg2等进行表格输出。
tabout var1 var2, c(mean sd) replace
esttab model1 model2, b(a3) se(3) star(.05 .01 .001) title("回归结果")
outreg2 using "regression_results.doc", replace
- 2.图表输出:使用命令graph export、twoway、marginsplot等进行图表输出。
graph export "figure1.png", replace
twoway scatter var3 var4 || lfit var3 var4
marginsplot, at(var5=(0 1)) by(var6)
- 3.文字说明:使用命令notes、putdocx、markdown等进行文字说明。
notes "根据回归结果,可以看出..."
putdocx "在此处插入文字说明" para
markdown "## 结果解释"
所遇到的问题“租个鸡婆”
1.如何导入excel的数据



如果数据导入后,出现红色,那么用destring 红色的变量,replace,将数据变为数值型。
2.报错记录
2.1 迎来的第一个报错
not possible with numeric variable
这表明你的变量已经是数值型了,不用在定义。
2.2 第二个报错
command logout is unrecognized
- 1.因为你logout命令没有下载,你可以在stata命令行输入
ssc install logout - 2.这时候会弹出
Java installation not found - 3.然后看这里,安装java【传送门】
注意,这里的ssc install XXX就相当于python里面的pip install XX哈哈哈
2.3 第三个报错
command pwcorr_a is unrecognized
我是看的这篇文章解决的
【传送门】
2.4 第四个报错
command esttab is unrecognized
执行:ssc install estout, replace
3.up🐖的代码解析
3.1 数据处理
/*数据整理*/
rename 综合税率A x2
rename 净资产收益率ROE y
rename 资产负债率 x1
rename 总资产周转率A x3
rename 资产对数 x4
rename 前十大股东持股比例 x5
3.2 面板数据的时间、个体设置
*xtset 股票代码 截止日期
encode 股票代码 ,gen(id)
encode 截止日期 ,gen(time)
xtset id time
xtset id time 这是 Stata 中的一个命令,用于设置面板数据的索引变量。其中,id 是个体标识变量,time 是时间标识变量。这个命令告诉 Stata,数据集是一个面板数据集,并且 id 和 time 是面板数据的索引变量,它们将被用来区分不同个体和不同时间点的观测值。这个命令在进行面板数据分析之前必须先执行,否则 Stata 不会正确地识别面板数据的结构。
3.3 变量的描述性统计
/*描述性统计*/
logout,save(基本统计描述)word replace:tabstat y x1 x2 x3 x4 x5,s(N mean p50 sd min max) f(%12.3f) c(s)
这里,f(%12.3f)保留小数点个数 ,c(s)是输出表格的形式,不变即可
3.4 相关性分析
/*相关性分析*/
logout,save(相关分析)word replace:pwcorr_a y x1 x2 x3 x4 x5
如果报错,解决方案看上面。
3.5 共线性诊断
/*共线性诊断*/
reg y x1 x2 x3 x4 x5,r
vif
logout,save(共线性诊断)word replace:vif
order y x1 x2 x3 x4 x5
注意,VIF<10即可进行下一步分析。
其次,r代表可选参数,order y x1 x2 x3 x4 x5是用于对数据进行排序。其中,y 是排序的关键字,后面的 x1,x2,x3,x4 和 x5 是需要排序的变量。该命令可以帮助用户快速对数据进行排序,以便更好地进行数据分析和处理。
那么作为面板数据,以上三步都通过的话,我们就需要判断选择固定效应或者随机效应
严格的模型检验而言,首先是从混合的模型开始检验
3.6 模型选择检验
/*模型选择检验*/
reg y x1 x2 x3 x4 x5
est store ols
xtreg y x1 x2 x3 x4 x5,fe
// 检验个体效应 ,表明固定效应优于混合ols模型 ,p<0.05表示个体效应显著,固定效应更好
reg y x1 x2 x3 x4 x5: 这是进行普通最小二乘回归分析的命令,其中 y 是因变量,x1,x2,x3,x4 和 x5 是自变量。
est store ols: 这是将回归结果保存在一个名为 ols 的存储器中,以便之后进行比较或使用。
xtreg y x1 x2 x3 x4 x5,fe: 这是进行固定效应模型(fixed effects model)的命令,其中 y 是因变量,x1,x2,x3,x4 和 x5 是自变量。fe表示使用固定效应模型进行分析,这种模型可以控制个体固定效应的影响。此外,xtreg 命令还可以用于面板数据分析,这时需要指定面板数据的特定变量。

挡住的p=0.0003是显著的,检验个体效应 ,表明固定效应优于混合ols模型 ,p<0.05表示个体效应显著,固定效应更好。
qui xtreg y x1 x2 x3 x4 x5,re
xttest0
//检验时间效应,结果随机效应也优于混合ols模型,p<0.05表示随机效应显著

qui xtreg y x1 x2 x3 x4 x5,re: 这是进行随机效应模型(random effects model)的命令,其中 y 是因变量,x1,x2,x3,x4 和 x5 是自变量,re 表示使用随机效应模型进行分析。
xttest0: 这是对面板数据的时间效应进行假设检验的命令,用于确定是否需要使用固定效应模型。如果检验结果 p 值小于显著性水平(通常为 0.05),则说明时间效应对因变量的影响是显著的,需要使用固定效应模型;否则,可以使用随机效应模型。
在这段代码中,检验结果显示随机效应模型优于混合 OLS 模型,并且时间效应对因变量的影响是显著的(p<0.05),因此使用随机效应模型进行分析是合理的。
qui是 Stata 中的一个命令,表示"quietly",即“安静地”执行命令。使用 qui 命令可以在执行命令时抑制 Stata 输出结果,避免在执行大量命令时过多干扰用户。
3.6.1 hausman检验
xtreg y x1 x2 x3 x4 x5,re
est store re
xtreg y x1 x2 x3 x4 x5,fe
est store fe
hausman fe re //豪斯曼检验,结果拒绝原假设,选用固定效应模型 p<0.05固定效应,大于0.05 随机效应
outreg2 using "豪斯曼检验", word ctitle(FE) adds(Hausman, `r(chi2)',p-value,`r(p)')replace //输出hausman结果
如果检验结果的 p 值小于显著性水平(通常为 0.05),则说明固定效应模型和随机效应模型之间存在显著差异,应该使用固定效应模型。反之,如果 p 值大于显著性水平,则说明两种模型的结果没有显著差异,可以使用随机效应模型。在这段代码中,检验结果拒绝了原假设,即固定效应模型和随机效应模型之间存在显著差异,应该使用固定效应模型,因为 p 值小于 0.05。
简言之:显著选固定,不显著选随机
模型选择到这里就告一段落,基本的分析也就结束。
3.6.2 初步模型整合
/*检验结果,应该选择固定效应回归分析*/
reg y x1 x2 x3 x4 x5
est store ols
xtreg y x1 x2 x3 x4 x5,fe
est store fe
xtreg y x1 x2 x3 x4 x5,re
est store re
esttab ols fe re using 实证结果.rtf, replace b(%12.3f) se(%12.3f) nogap compress s(N r2 r2_a)star(* 0.1 ** 0.05 *** 0.01) //加入了调整R2,r2_
esttab ols fe re using :实证结果.rtf, replace:这是将存储在 ols、fe 和 re 存储器中的回归结果输出到一个名为 实证结果.rtf 的 RTF 文件中的命令。replace 表示如果文件已经存在,则替换原有文件。
b(%12.3f) se(%12.3f):这是将回归系数和标准误的输出格式设置为小数点后三位的浮点数。【格式固定不动】
nogap:这是设置 esttab 命令的输出格式,使之间隔更为紧凑。
compress:这是使用压缩格式来输出 RTF 文件,减小文件大小。
s(N r2 r2_a)star(* 0.1 ** 0.05 *** 0.01):这是在输出结果中添加一些统计信息,如样本大小、拟合优度和调整 R^2。星号表示统计量的显著性水平,例如 * 表示显著性水平为 0.1,** 表示显著性水平为 0.05,*** 表示显著性水平为 0.01。【格式固定不动即可】

注意:
- 1.标红1处,关键变量x1在三个模型都显著,说明我们的模型对x1来说是 稳健的。
- 2.增加了
Prob>chi2=0.0000这是固定效应,hausman检验的结果。需要在论文中说明。
4.滞后检验
没弄出来!
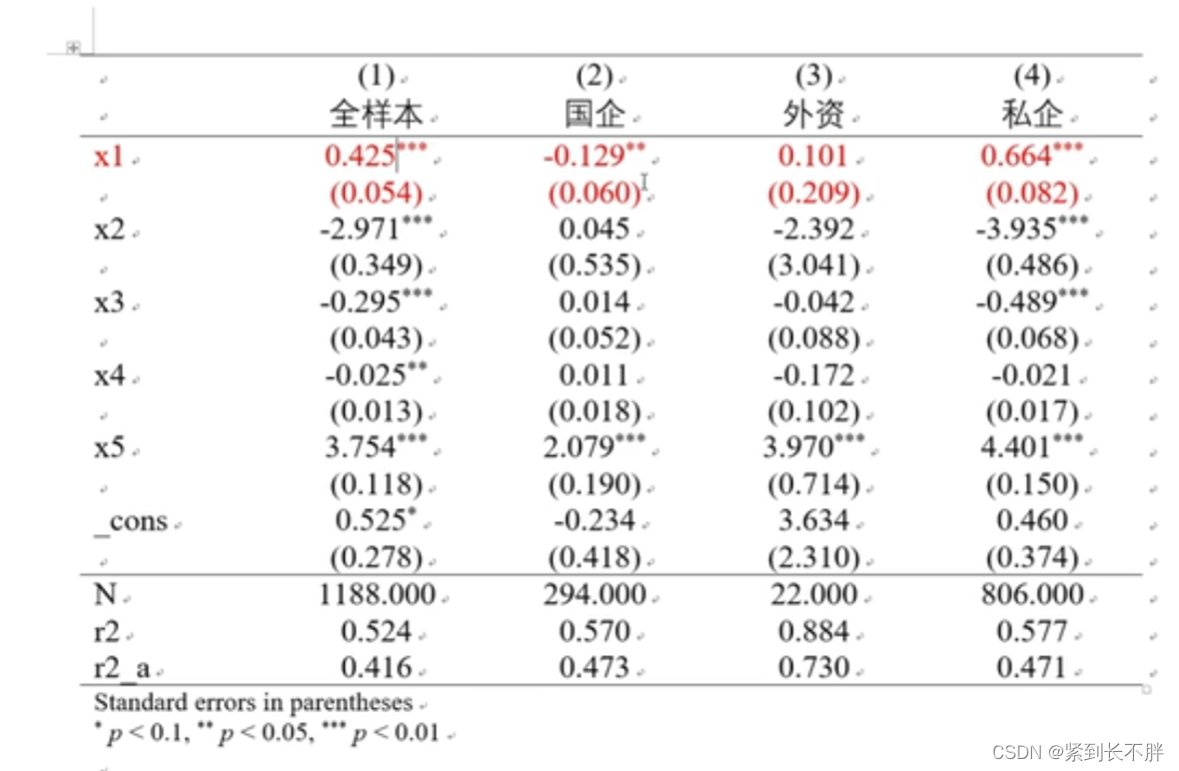
5.分组回归
/**************************分组回归************************/
order y x1 x2 x3 x4 x5 分组1
*encode 股权性质,gen(分组)
order y x1 x2 x3 x4 x5 // 国企 = 2 外资 = 3 私企 = 4
xtreg y x1 x2 x3 x4 x5 if 分组1 == 2 ,fe
est store fe3
xtreg y x1 x2 x3 x4 x5 if 分组1 == 3 ,fe
est store fe4
xtreg y x1 x2 x3 x4 x5 if 分组1 == 4 ,fe
est store fe5
esttab fe fe3 fe4 fe5 using 分组回归.rtf, replace b(%12.3f) se(%12.3f) nogap compress s(N r2 r2_a)star(* 0.1 ** 0.05 *** 0.01) //加入了调整R2,r2_a
注意分组回归的分组变量,需要encode 股权性质,gen(分组)重新编码!不然会type mismatch
结果整理:
6.调节效应
/**************************调节效应************************/
*gen TJ = x4*x5
xtreg y x1 x2 x3 x4 x5 TJ ,fe
est store fe6
esttab fe fe6 using 调节效应.rtf, replace b(%12.3f) se(%12.3f) nogap compress s(N r2 r2_a)star(* 0.1 ** 0.05 *** 0.01) //加入了调整R2,r2_a
需要用gen来产生调节变量
7.中介效应
/**************************中介效应************************/
* rename 托宾Q值TQ ZJ
xtreg y x1 x2 x3 x4 x5 ,fe
est store fe7
xtreg ZJ x1 x2 x3 x4 x5 ,fe
est store fe8
xtreg y x1 ZJ x2 x3 x4 x5 ,fe
est store fe9
esttab fe7 fe8 fe9 using 中介效应.rtf, replace b(%12.3f) se(%12.3f) nogap compress s(N r2 r2_a)star(* 0.1 ** 0.05 *** 0.01) //加入了调整R2
中介效应,这里用的是三步检验法。先看x与y的一般检验是否通过,再看x与中介变量m检验,最后看x、m与y的检验
结果整理如下:
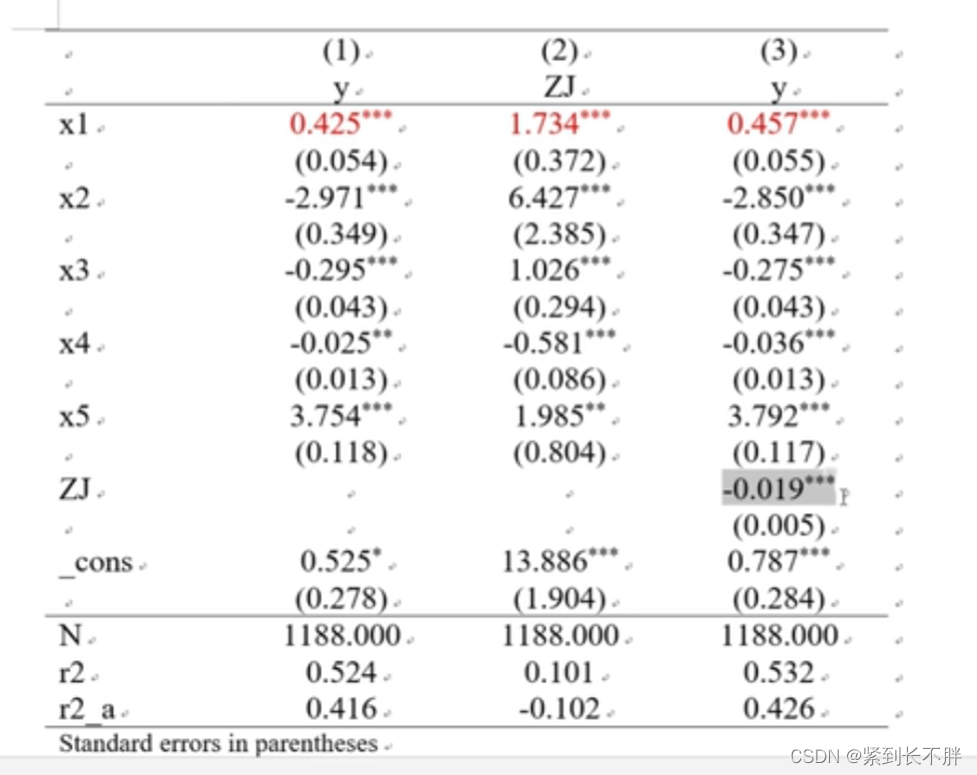
则存在中介效应,如果模型3的x1系数不显著,那么,这存在完全中介效应。
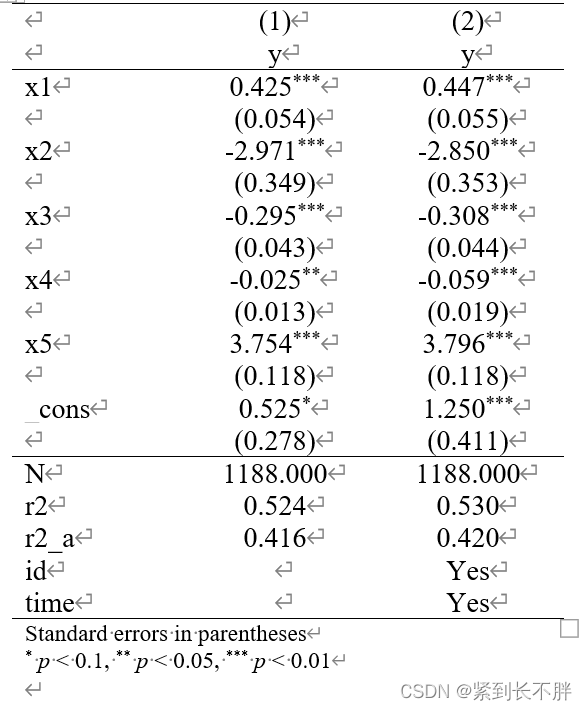
8.控制时间和个体(省份、时间)
/***********************控制时间 个体************************/
xtreg y x1 x2 x3 x4 x5 i.id i.time ,fe
estadd local id "Yes"
estadd local time "Yes"
est sto fe10
esttab fe fe10 using 控制个体时间回归.rtf, replace b(%12.3f) se(%12.3f) nogap compress drop(*.id *.time) s(N r2 r2_a id time)star(* 0.1 ** 0.05 *** 0.01) //加入了调整R2


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











