









目录
1、论文任务:
基于结构化数据生成描述文本,此处论文主要是应用在E2E数据集上。

如上图所示,论文任务为利用键值对数据(二元组)生成描述文本。左边的键值对包括若干个“属性-值”组成对,右边是对应数据记录的描述文本。
2、论文贡献:
- 化整为零,将一段文本分成若干段。逐段进行生成,便于控制输出文本的结构
- 显性的建立了,“文本段”与实体记录之间的联系。可以提高模型结果的“忠实性”
- 分段解码生成文本,模型生成文本时只关注对应的实体记录而不是整个数据。可以减少模型的内存和计算消耗。
- 通过控制分段输出,可以减少生成文本的冗余。
总结:
- 做法:分段进行文本生成,
- 结论:提高了生成文本的准确性,和降低了生成文本的冗余性
3、文本分割:
文本分割指的是:将描述文本进行分割,每一部分与实体数据相对应,由此即可知道每一对实体数据生成了描述数据中哪一部分。利用这种对应关系即可通过指定实体对生成相应描述文本,而无需要关注整体数据。

4、整体思路:
主要利用的是数据独立的特点,每一个实体对数据都需要生成一部分描述数据,而且生成相应描述数据时无需要关注整体数据。

文本分割是本文的核心:通过文本分割,将数据实体与文本描述段进行对应。由于数据的特点,固定的数据对描述固定的内容,由此即可利用指定实体生成指定描述内容,且生成固定描述文本时只需要关注相对于的类型实体数据,提高了准确性减少了计算开支。有多少数据对生成多少描述内容,既保证了生成的描述文本的忠实性也减少了冗余。
5、整体框架:
- X --> 输入数据
- S1 --> 分段文本(由若干个字组成)
- c(s1) --> s1分段对应的数据记录
- y1 --> 对应文本中的一个字

模型整体上,依次利用数据记录生成相应的描述文本,生成相应文本段时只关注相应的数据记录,而与其它数据记录无关。
- generation:生成过程就是一个解码过
- 作用:根据当前待描述的数据记录生成描述文本
- Transition:类似于解码过程,c(so)只与c(so-1)和π(s<o)有关
-
作用:通过前面提及的描述内容,判断接下来将描述哪个记录数据
-
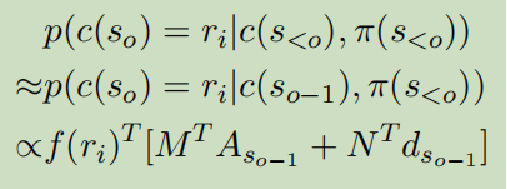
所以其实就是两个解码过程,利用每一个记录来生成一段文本,通过生成的顺序将文本连接起来。
6、输出控制:
在解码时采用三个简单限制来控制文本生成:
- 文本分段不能为空。 ---> (考虑应该在生成文本分段时候添加此限制)
- 相同的数据记录不能被重复使用。 ---> 控制了文本冗余
- 只有当所有数据记录都被使用后,生成过程才会完成。 ---> 控制了文本缺失(miss)
7、实验结果:


区别于传统的注意力模型,论文没有关注记录选择注意力,而是将记录选择从模型中单独分割了出来,即利用已生成的描述文本和上一个描述记录数据来判断下一个记录数据(逐个选择记录数据)。区别于传统:判断需要生成的文本可能关注哪些记录数据,或者先全部选好以及排序后再来生成描述文本。















 2002
2002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









