






关于spark的textFile在读文件的时候究竟会产生多少个分区,有人认为就是按照block块来划分,如果文件大小不够128M,就按文件个数去划分,其实不是的这样的,如果有这种想法说明是Hadoop的MR没有学好,因为textFile底层调用的就是Hadoop的FileInputFormat来进行切片分区的。下面从源码来分析下textFile在读取数据的时候会产生多少个分区。
#首先 我们先调用textFile方法 然后按住ctrl 点击textFile,进入到方法体内部
val words = sc.textFile("hdfs://node1:8020/word.txt")
#可以看出来 这里有一个默认的最小分区数,点进去会发现是2.并且这里使用了TextInputFormat,我们继续往里边点。
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
#点进来以后发现这个类继承自FileInputFormat,可以看到TextInputFormat里好多方法都没有进行重写,
#所以我们直接点进父类,查看有没有什么切片的方法
public class TextInputFormat extends FileInputFormat<LongWritable, Text>
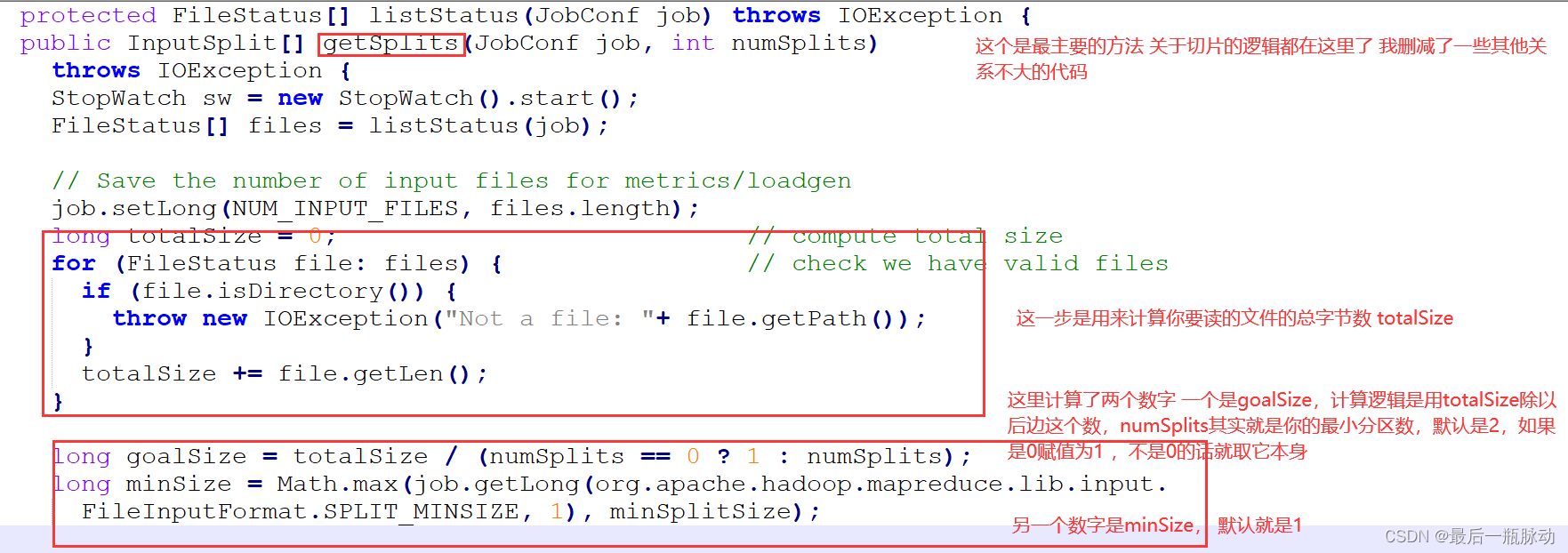
#这里的代码比较多 我直接截图放到下边并说明每一块的作用https://img-blog.csdnimg.cn/direct/9e82bc1590ae4c82b425de14602f6d9c.png https://img-blog.csdnimg.cn/direct/47c4c4b5b8014095a585d3f1ee606972.png 这两个图片放进来不显示 不知道为啥 我把图片链接放这里。 根据这两段代码我们可以举例子来加深理解,比如我们现在有5个文件,其中4个100字节,另外1个500字节,在计算的时候我们需要先计算一个goalSize,就是把这些文件大小加一起除以最小分区数,这个最小分区数默认是2,假设我们现在设置成3,那就是900/3=300字节。
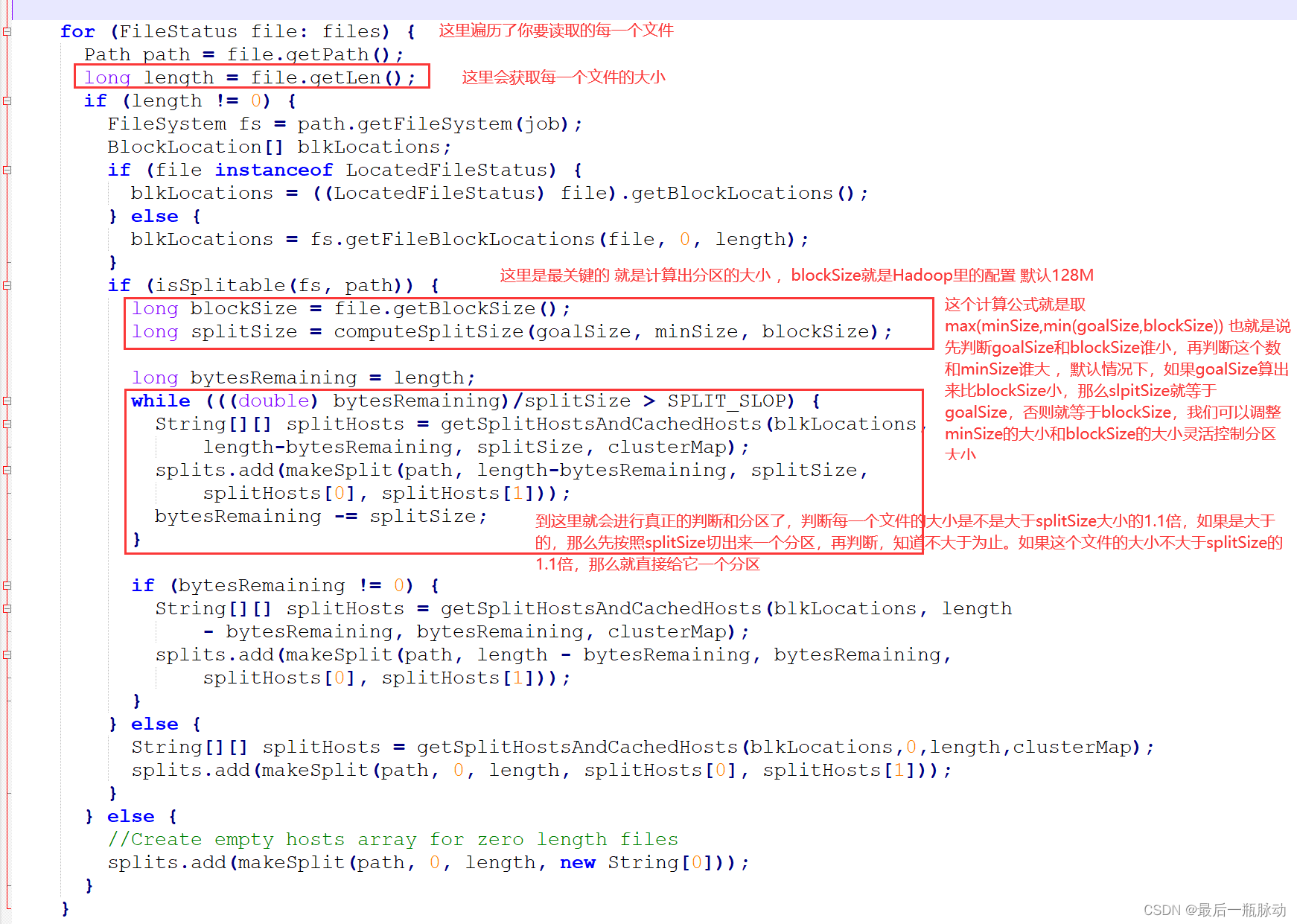
ok,得到goalSize以后我们还需要计算一个splitSize,也就是真正的分区切片大小,这个公式是splitSize=max(minSize,max(goalSize,blockSize)),这里的话minSize默认为1,blockSize默认就是Hadoop的切块大小(所以我们可以调整minSize和blockSize灵活调整splitSize的大小,想调大,就把minSize调大,想调小,就把blockSize调小)。那么这里计算出来splitSize就等于goalSize,也就是300字节。
接下来就是遍历每个文件了,遍历前4个文件的时候都是100字节,那么每个文件给一个分区进行处理,遍历到最后一个文件的时候,500>300*1.1 这个1.1是默认的设置 ,就是为了缓解出现一个文件被切成两个分区,一个超大一个超小的情况 。这时候会先按照300切一个分区,剩下的200再和300*1.1比较,是小于的,那么再给它一个分区处理,最后的分区数量就是4+2=6。注意我这里说的切一个分区是按照逻辑切片,而不是真的对文件物理切分。
















 3592
3592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}