






索引的底层原理
索引是帮助mysql高效获取数据的排好序的数据结构
索引数据结构
二叉树
红黑树:本质还是二叉树(二叉平衡)有自我平衡的功能,树太高了,叶子节点,最底层的节点,树的高度太高,索引落在叶子节点的话,查找的效率很低。
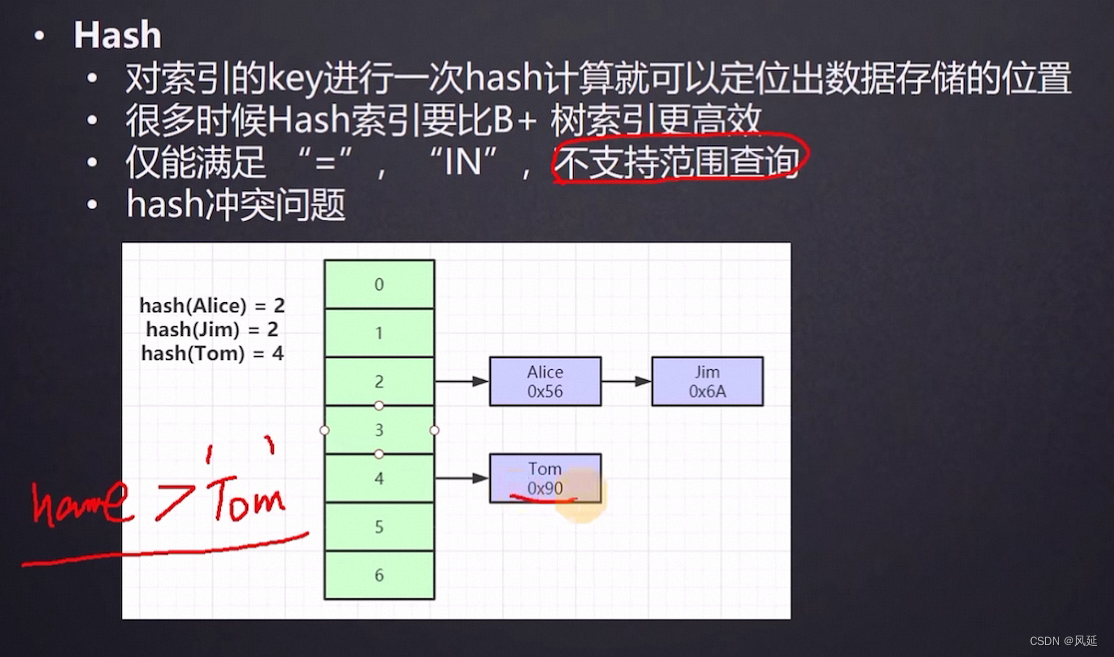
Hash表
B-Tree:要求树高很低。横向的方向扩展存储的索引比较多
叶节点具有相同的深度,叶节点的指针为空
所有索引元素不重复
节点中的数据索引从左到右递增
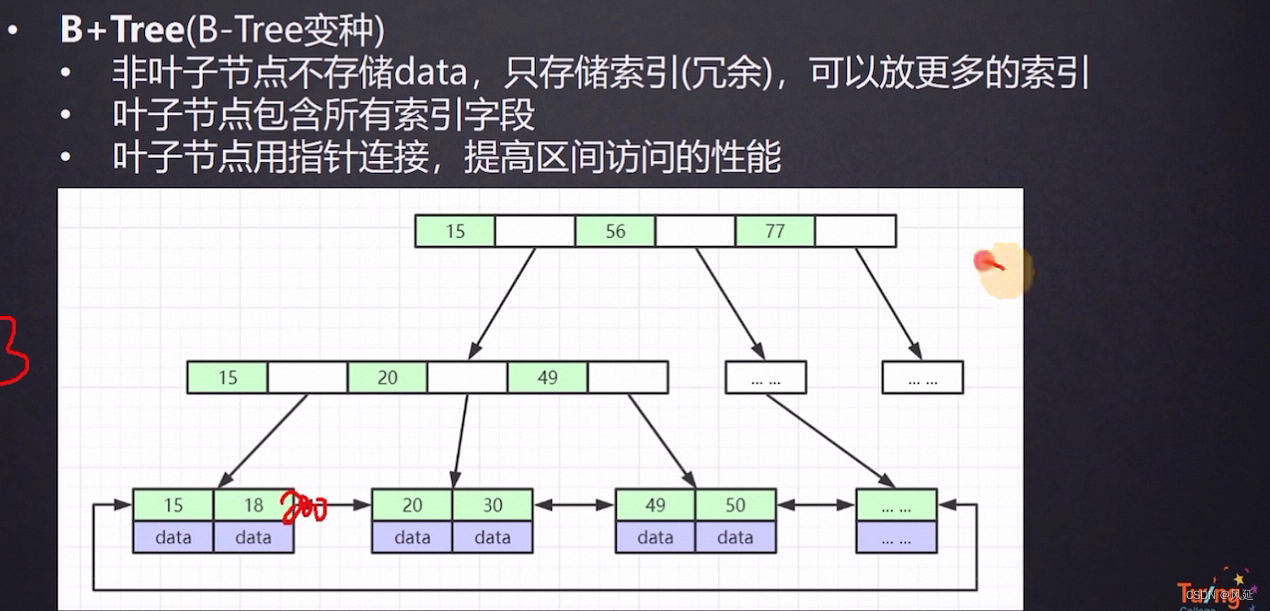
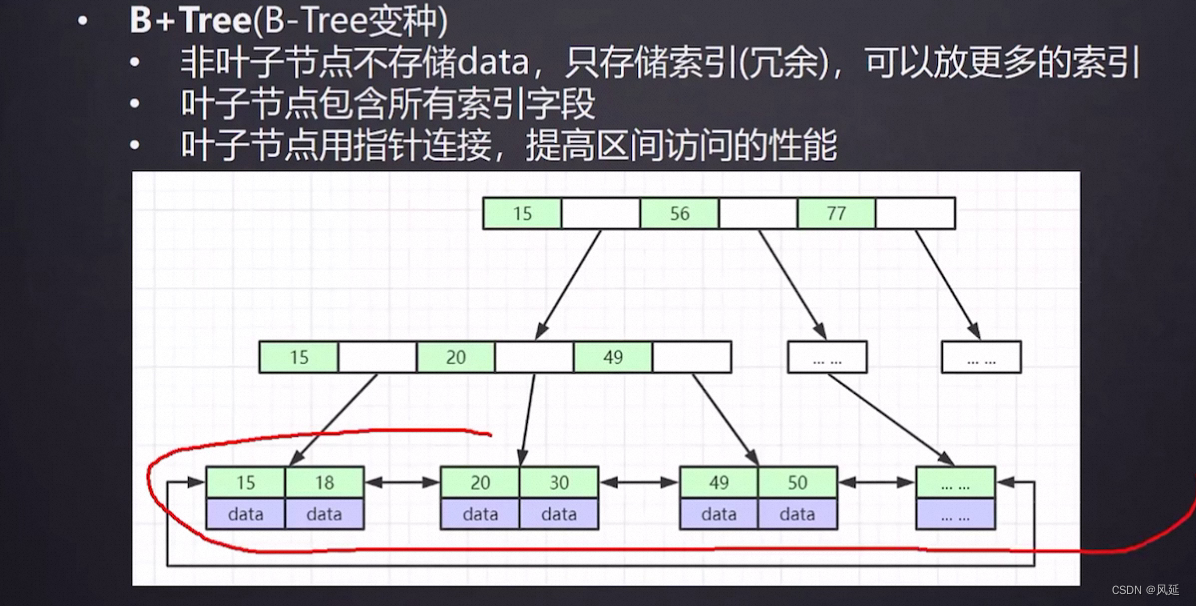
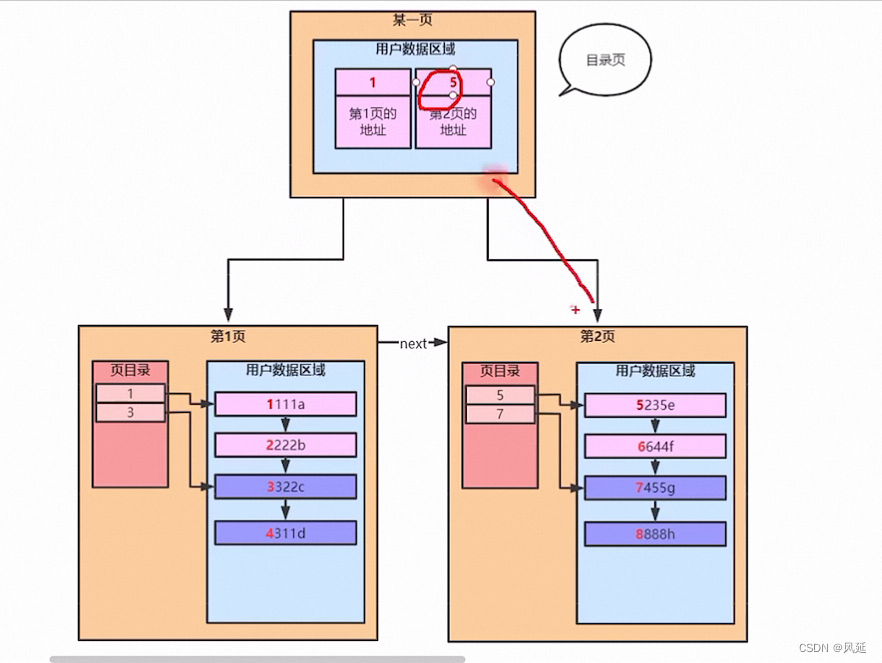
B+树:把整张表的索引放到叶子节点,中间的非叶子节点
1.非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
2.叶子节点包含所有索引字段
3.叶子节点用指针连接,提高区间访问的性能
4.内存里折半查找
show global status like ‘innddb_page_size’; 一个节点16KB
bigint 8B 8个字节
空白地方放置下一级节点磁盘文件地址 6B 6个字节
存储引擎最终形容数据库表,索引表结构数据存储在data目录下
MYI放B+树,MYD放置data,查询顺序先区MYI找索引元素,根节点出发比大小,把数据对应的所在行磁盘文件地址,再去MYD把这行数据
INNODB存储引擎的表,frm存放表结构,ibd存放数据和索引
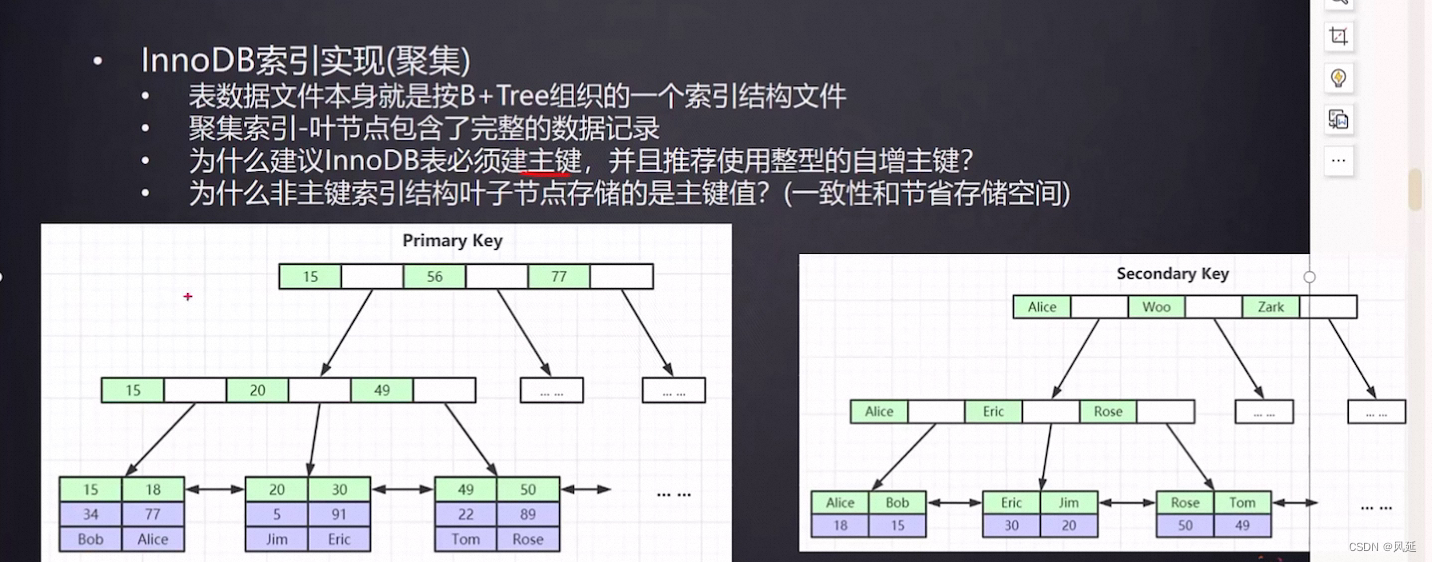
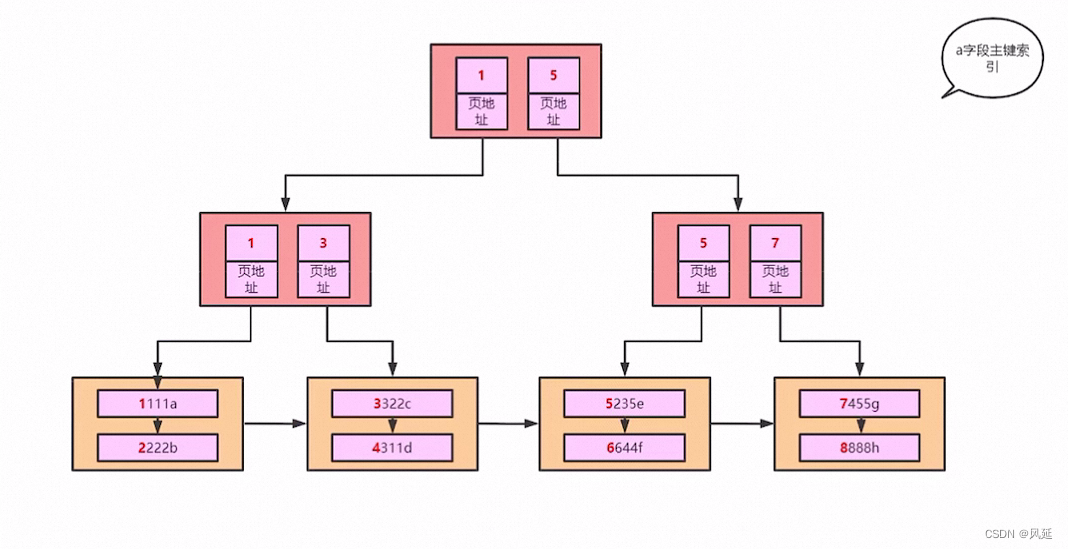
INNODB索引实现(聚集)
表数据文件本身就是按B+Tree组织的一个索引结构文件
聚集索引-叶节点包含了完整的数据记录
为什么建议innodb表必须建主键,并且推荐使用整型的自增主键

图中信息:
InnoDB索引实现(聚集)
1.表数据文件本身就是按B+树组织的一个索引结构文件
2.聚集索引-叶节点包含了完整的数据记录
3.为什么建议InnoDB表必须建主键,并且推荐使用模型的自增主键
4.为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
最早版本用的是二叉树,红黑树,
红圈的每次挪动,就对磁盘做一次IO交互。
二叉树蜕化成了链表
减少I/O查找次数
红黑树大的往右插,【二叉平衡树】比单纯的二叉树(链表)效率提升一倍


树越高,IO交互次数越多,高一层多一次
B树由红黑树演变而来,B+树冗余索引构成支架
一个节点出发,加载到内存内进行折半查找,找到磁盘位置,把下一个节点加载到内存中查找
mysql每个页节点16KB(实践得出比较优秀,不建议修改),bigint 8B 冗余空间占用 6B,正常高度为3的B+树可支持1K的单条数据能支持2000W左右
叶子节点不会放到内存,由内存比对找到叶子节点的磁盘物理位置后去磁盘读取相关数据。
先判断是不是索引查询,如果是的,会从索引文件查询数据的磁盘位置(MYI)叶子节点存放的物理位置,之后再去数据文件查找数据(MYD)
innodb叶子节点,存的是完整的数据记录。
聚集索引:索引把数据聚集在一起。
二级索引,叶子节点存储的是主键索引的值,然后回表到聚集索引回表查询数值
数据和索引是分开存储(非聚集索引,MYISAM)
没有就根据rowid类的来维护,会影响mysql的性能,推荐整型自增,字符串要逐位比较。
a>7先找a=7
联合索引 b=1走索引, b>1 不走索引,系统任务全表扫描比索引快,走索引回表的次数过多,没一次全表扫描来的快。
联合索引 select * 的情况下 b=1走索引, b>1 不走索引,系统任务全表扫描比索引快,走索引回表的次数过多,没一次全表扫描来的快。
但是select b/b,c,d/b,c,d,a from t where b > 1,走索引,不需要回表

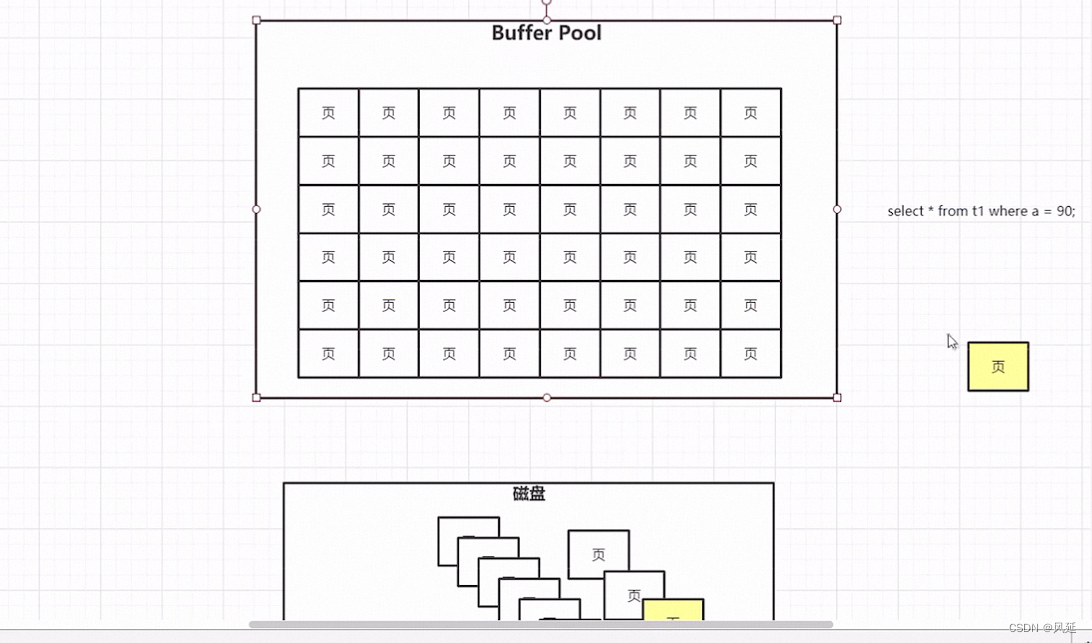
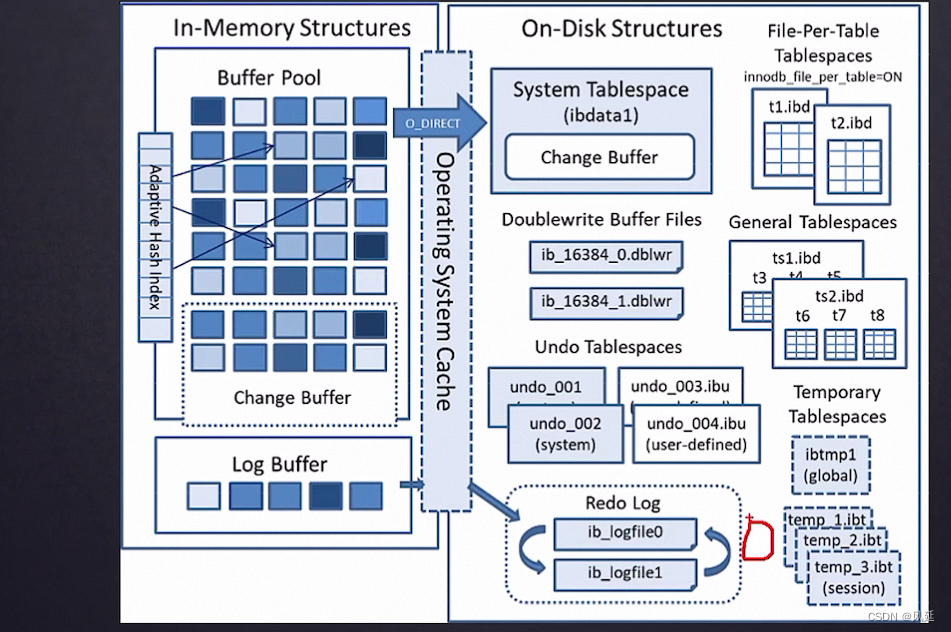
buffer pool 默认 128M,页16KB
查询数据,先把磁盘中的查找的数据copy到bufferpool里,bufferpool里实际是一个数组。空闲区域如何管理,(用free链表管理)
free链表:基节点,
flush链表:每一个控制块就是脏页,把控制块对应的页数据持久化到磁盘上
lru链表(内存淘汰机制):最近用的最少次的数据淘汰,新加入的加到链表的头部,越是链表靠前,越是最近访问的,越是链表靠后,越是不常用的,淘汰链表最后一个控制块对应的数据。
内存一直存的热点数据。突然来执行一下全表扫描,不断地从磁盘取数据到bufferpool中,会把之前热点数据全部淘汰掉。重新执行业务sql会重新加载热点数据。
内存满了的情况,需要淘汰不常用数据(常用数据-热点数据),
控制块的顺序是按修改时间的顺序。
update 先把buffer pool里的值修改成最新值,之后再持久化到磁盘中。有线程定期查看buffer pool里哪些页是脏页
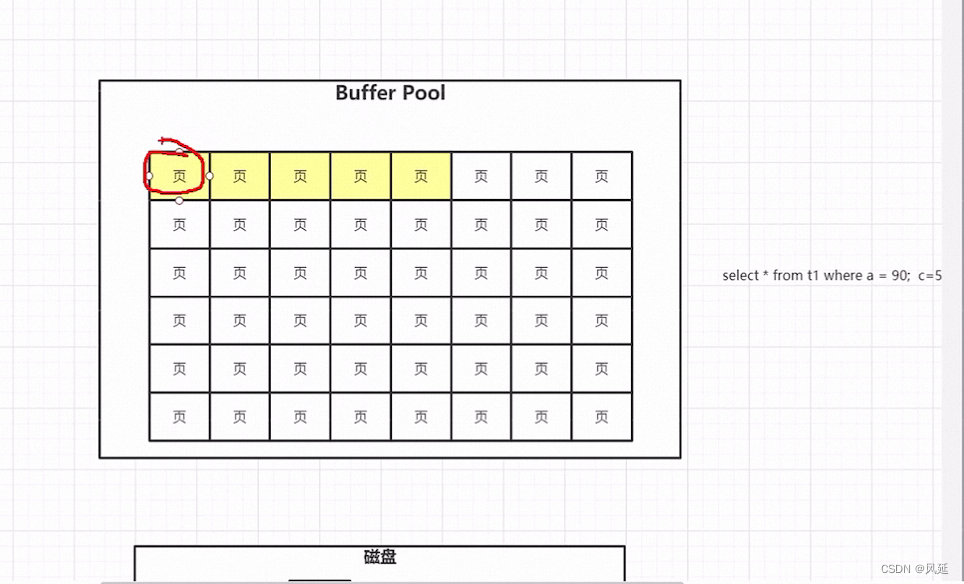
mysql从磁盘取数据,最小的单位是页,把页的数据copy到buffer pool里,内存中的存储类似数组,内存缓存的数据淘汰后会导致内存数据的不连续。
mysql从磁盘取数据,最小的单位是页,把页的数据copy到buffer pool里,内存中的存储类似数组,内存缓存的数据淘汰后会导致内存数据的不连续。
基节点,热数据区域,冷数据区域 什么情况下把冷数据区域的数据挪到热数据区域中来。(升级版LRU,解决了全表扫描会换血内存的情况)
对于冷数据区域的页,占用3/8,
执行update命令
1.修改buffer pool里面的页数据—脏页
2.生成一个redo log
3.redo log 持久化
4.修改成功
Mysql挂掉了,buffer pool里的缓存没了,需要从磁盘中找到数据缓存到buffer pool中,但有redolog
ib_logfile0 ib_logfile1 为什么会有两个文件
只有当事务提交后才需要做redolog持久化
1.修改buffer pool里面的页数据—脏页
2.修改磁盘中的页数据,代价比较大,修改一条就要把整页数据进行持久化,随机IO:磁头逐条找持久化的数据消耗的时间很久
3.修改成功
redolog
ib_logfile0
ib_logfile1
两个都写满了,触发检查点,把redolog的所有页都持久化到磁盘上,可以适当将redolog文件数和文件大小调大,提高效率,但重启会很慢
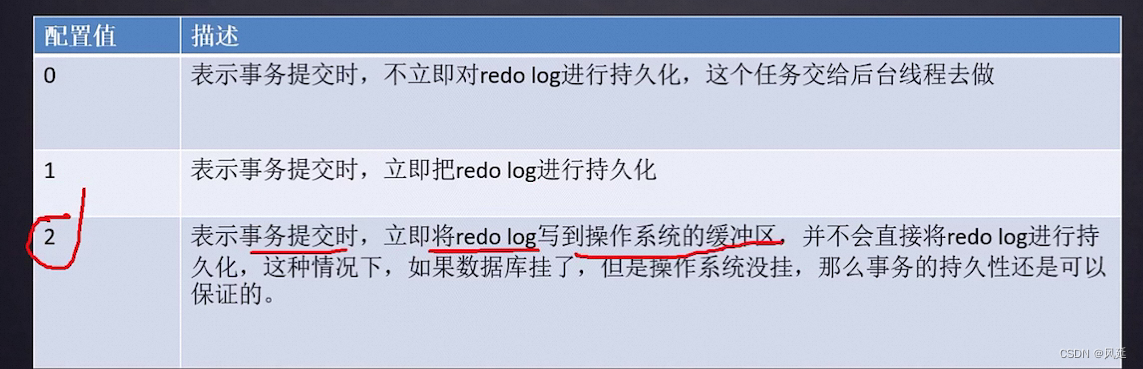
innodb_flush_log_at_trx_commit
0 表示事务提交时,不立即对redolog进行持久化,这个任务交给后台线程(mysql自己的,不能数据库挂掉)去做
1 表示事务提交时,立即把redolog进行持久化(安全性最高)
2 表示事务提交时,立即将redolog写到操作系统的缓冲区,并不会直接将redolog进行持久化,这种情况下,如果数据库挂了,但是操作系统没挂,那么事务的持久性还是可以保证的。
binlog记录的是一些sql,update语句,用于主从复制(redolog存储的太小了)
redolog记录的是修改某一页某一个物理位置的数据,恢复数据很快(相比较于binlog)
undolog记录的是反向操作日志记录rollback的















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









