










为什么写这篇文章
最近几个月一直在做内容咨询平台,然后有人提议用cos公式计算用户偏好度,我就感觉有点疑惑,这个公式不是计算相似度的吗?拿这个公式怎么能突出用户的偏好?最多反应A、B两个用户都看这篇文章,但不能体现谁更加喜欢看,然后自己就写了一个计算COS相似度的程序,顺便整理一下其中的原理写成博客分享给大家。
∑
i
=
1
n
(
x
i
×
y
i
)
∑
i
=
1
n
(
x
i
)
2
×
∑
i
=
1
n
(
y
i
)
2
\frac{\sum_{i=1}^{n} (x_i \times y_i)}{\sqrt{\sum_{i=1}^{n}{(x_i)^{2}}}\times \sqrt{\sum_{i=1}^{n}{(y_i)^2}}}
∑i=1n(xi)2×∑i=1n(yi)2∑i=1n(xi×yi)
COS相似度公式推理
基础理论
任何看似很复杂的公式,其实都是从最基础的理论推出来的,首先先来看下直角三角形余弦公式:
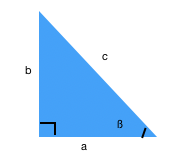
c
o
s
ß
=
a
c
cos_ß= \frac{a}{c}
cosß=ca
任意三角形余弦公式
有了这个基本公式后,能不能求出任意三角形的余弦呢?假设任意三角形三边分别位a、b、c,从上往下作一条高为h,如下图可以分为两个直角三角形;设未知数x,则有
c
o
s
ß
=
x
a
cos_ß=\frac{x}{a}
cosß=ax, 推理如下:

通过直角三角行边长定理:两直角边的平方和=斜边的平方
得出结论:
a
2
−
x
2
=
b
2
−
(
c
−
x
)
2
a^{2}-x^{2}=b^{2}-(c-x)^{2}
a2−x2=b2−(c−x)2
=>
a
2
−
x
2
=
b
2
−
(
c
2
−
2
x
c
+
x
2
)
a^{2}-x^{2}=b^{2}-(c^2-2xc+x^2)
a2−x2=b2−(c2−2xc+x2)
=>
a
2
−
x
2
=
b
2
−
c
2
+
2
x
c
−
x
2
a^{2}-x^{2}=b^{2}-c^2+2xc-x^2
a2−x2=b2−c2+2xc−x2
=>
2
x
c
=
a
2
+
c
2
−
b
2
2xc= a^2+c^2-b^2
2xc=a2+c2−b2
=>
x
=
a
2
+
c
2
−
b
2
2
c
x= \frac {a^2+c^2-b^2}{2c}
x=2ca2+c2−b2
所以
c
o
s
ß
=
a
2
+
c
2
−
b
2
2
a
c
cos_ß=\frac {a^2+c^2-b^2}{2ac}
cosß=2aca2+c2−b2
任意两个坐标的余弦公式
回归正题,我们最终目的是为了求两组数据的相似度,那能不能把每组数据当作一个坐标呢?也可以说当作两个向量
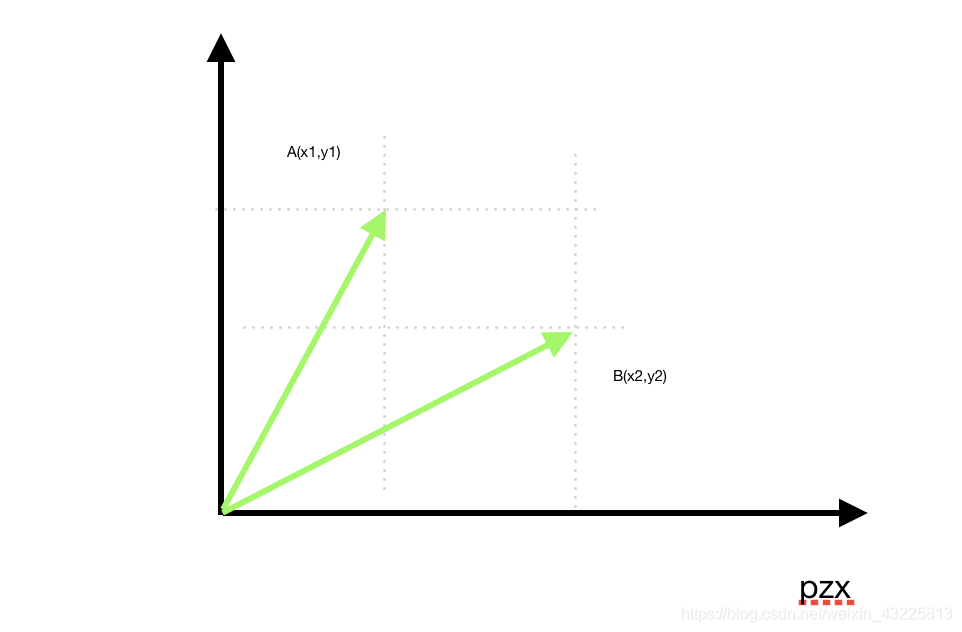
设两个坐标A(x1,y1),B(x2,y2)和原点形成的角ß,结合前面的结论,是不是只需要求出A到原点距离、B到原点的距离、以及A到B的距离就能知道角ß的余弦值了;仔细看上图的虚线,得出以下几个公式:
A到原点的距离=
x
1
2
+
y
1
2
\sqrt{x_1^2+y1^2}
x12+y12
B到原点的距离=
x
2
2
+
y
2
2
\sqrt{x_2^2+y_2^2}
x22+y22
A到B的距离=
(
y
1
−
y
2
)
2
+
(
x
2
−
x
1
)
2
\sqrt{(y_1-y_2)^2+(x_2-x_1)^2}
(y1−y2)2+(x2−x1)2
通过上述得出的任意三角形余弦公式得出表达式:
c
o
s
ß
=
x
1
2
+
y
1
2
+
x
2
2
+
y
2
2
−
(
(
y
1
−
y
2
)
2
+
(
x
2
−
x
1
)
2
)
2
×
x
1
2
+
y
1
2
×
x
2
2
+
y
2
2
cosß=\frac{x_1^2+y_1^2+x_2^2+y_2^2-((y_1-y_2)^2+(x_2-x_1)^2)}{2\times\sqrt{x_1^2+y1^2}\times\sqrt{x_2^2+y_2^2}}
cosß=2×x12+y12×x22+y22x12+y12+x22+y22−((y1−y2)2+(x2−x1)2)
=>
=
x
1
2
+
y
1
2
+
x
2
2
+
y
2
2
−
(
y
1
2
−
2
y
1
y
2
+
y
2
2
+
x
2
2
−
2
x
1
x
2
+
x
1
2
)
2
×
x
1
2
+
y
1
2
×
x
2
2
+
y
2
2
= \frac{x_1^2+y_1^2+x_2^2+y_2^2-(y_1^2-2y_1y_2+y_2^2+x_2^2-2x_1x_2+x_1^2)}{2\times\sqrt{x_1^2+y1^2}\times\sqrt{x_2^2+y_2^2}}
=2×x12+y12×x22+y22x12+y12+x22+y22−(y12−2y1y2+y22+x22−2x1x2+x12)
=>
=
2
y
1
y
2
+
2
x
1
x
2
2
×
x
1
2
+
y
1
2
×
x
2
2
+
y
2
2
=\frac{2y_1y_2+2x_1x_2}{2\times\sqrt{x_1^2+y1^2}\times\sqrt{x_2^2+y_2^2}}
=2×x12+y12×x22+y222y1y2+2x1x2
=>
=
y
1
y
2
+
x
1
x
2
x
1
2
+
y
1
2
×
x
2
2
+
y
2
2
=\frac{y_1y_2+x_1x_2}{\sqrt{x_1^2+y1^2}\times\sqrt{x_2^2+y_2^2}}
=x12+y12×x22+y22y1y2+x1x2
至此终于得到任意两个向量的余弦公式了,但怎么感觉和开头提出的公式有点不一样?
其实大家转变下思路,如果是任意两个坐标(x1,x2),(y1,y2);那么公式就是对的上了:
x
1
y
1
+
x
2
y
2
x
1
2
+
x
1
2
×
y
2
2
+
y
2
2
\frac{x_1y_1+x_2y_2}{\sqrt{x_1^2+x_1^2}\times\sqrt{y_2^2+y_2^2}}
x12+x12×y22+y22x1y1+x2y2
继续扩展,如果坐标是(x1,x2,x3,…,xi),(y1,y2,y3,…,yi),那么公式:
∑
i
=
1
n
(
x
i
×
y
i
)
∑
i
=
1
n
(
x
i
)
2
×
∑
i
=
1
n
(
y
i
)
2
\frac{\sum_{i=1}^{n} (x_i \times y_i)}{\sqrt{\sum_{i=1}^{n}{(x_i)^{2}}}\times \sqrt{\sum_{i=1}^{n}{(y_i)^2}}}
∑i=1n(xi)2×∑i=1n(yi)2∑i=1n(xi×yi)
COS相似度原理
首先提出一个问题,如果两条直线重合,那么他们是不是就是一样的?答案是肯定的;那么两个向量也是一个道理,如果两个向量方向是一样的,那么他们的夹角就是0度,那么余弦为1,表示完全一样,如果他们的方向刚好成90度,那么余弦为0,表示完全不一样;因此可以通过余弦判断相似度;那么怎么把这种算法应用到数据分析和推荐上面呢?请继续看下面的例子。
题目1:请判断下面两句话的相似度.
A: 拥有技术很容易,拥有技术解决方案才是财富
B: 技术很容易拥有,但拥有技术解决方案很难
- 首先我们对两个语句分别进行分词
A: [拥有,技术,很,容易,拥有,技术,解决,方案,才是,财富]
B: [技术,很,容易,拥有,但,拥有,技术,解决,方案,很,难] - 取并集
[拥有,技术,很,容易,解决,方案,才是,财富,但,难] - 判断A、B两个句子每个分词出现的频率(拿并集和自己比较)
A:[2,2,1,1,1,1,1,1,0,0]
B:[2,2,2,1,1,1,0,0,1,1] - 大家想下如果两个句子分词一样,出现的频率也一样是不是相似度就几乎一样了;而且通过频率得出来的两个数组,是不是可以看作两个多维坐标?如果两条数据越相似那么得出来的这两个坐标的向量的方向就会越靠近甚至一样;那么这样是不是就把数据和算法结合起来了,通过这两个坐标带入到上面的公式就得出了他们的相似度。
- 这里给出一个接口大家可以测试下https://alanpoi.com/compare/t/p
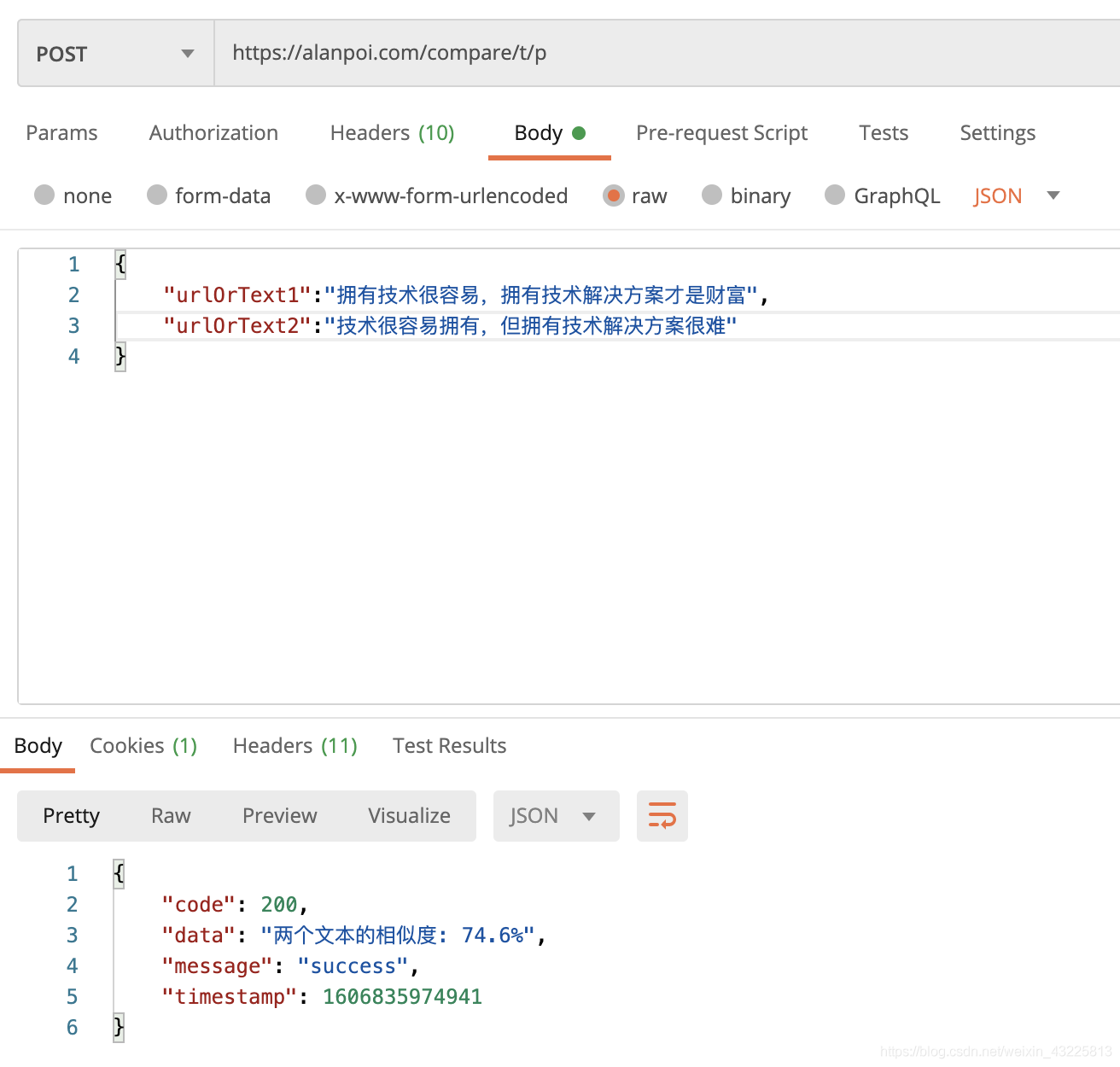
上面的74.6%是没有过滤分词后的停用词计算的,目前接口已经过滤了停用此,计算出得结果会更符合实际场景;你们通过上面的公式计算的结果也会是这个值
为什么要过滤停用词?
比如“我有女朋友”和”我有苹果“,这两句话完全不是一个意思,如果把”我有“也算进去,那算出它的相似度会超出想象;但是如果只匹配词语就可以不过滤,比如判断一篇文章所有的标签和用户的标签相似度,那么就可以直接计算
深入扩展
上面的场景可能可以解决大部分相似度判断的场景,但是还有一部分不能满足,那就是语义词,比如“我有一台笔记本”和“我有一台电脑”,通过上面的公式计算可能就相似度几乎为0了,那么怎么解决呢?
解决思路
第一步 先提前准备好一个语义词库,把相同语义的词放一组,如果考虑数据很大,可以打上标签或者分类
第二部 进行分词
第三部 数据替换(还是笔记本和电脑的例子,笔记本去匹配语义库,匹配到了把这一组全部放到分词中,电脑也去匹配,最终两个句子的分词就分别为[笔记本,电脑],[笔记本,电脑])
第四部 带入公式计算
个人建议:如果针对很长的文本,根据语句或者段落分开计算,这样子会更准确。
源码调用
<dependency>
<groupId>com.alanpoi</groupId>
<artifactId>alanpoi-common</artifactId>
<version>1.3.3</version>
</dependency>
- 如果自己已经分好词了调用
SimilarUtil.calculate(List<String> val1, List<String> val2)
- 如果是两个文本字符
// 不强制要求,建议在项目启动的时候初始化
//如果不启动初始化,第一次调用分词由于初始化数据会导致很慢,之后就会很快了
WordSegInitConfig.init();
SimilarUtil.calculate(String text1, String text2)
最近太忙,都没有什么精力搞自己的事情,写的和画的图都比较仓促,希望能给大家带来帮助!
原创不易,转载请注明原文地址
















 8627
8627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











