







Spark之并行度和分区
并行度和分区
默认情况下,Spark 可以将一个作业切分多个任务后,发送给 Executor 节点并行计算,而能
够并行计算的任务数量我们称之为并行度。这个数量可以在构建 RDD 时指定。记住,这里
的并行执行的任务数量(Task),并不是指的切分任务的数量。
集合数据源分区
def main(args: Array[String]): Unit = {
//准备环境
//[*]----当前系统的核数
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//创建RDD
/**
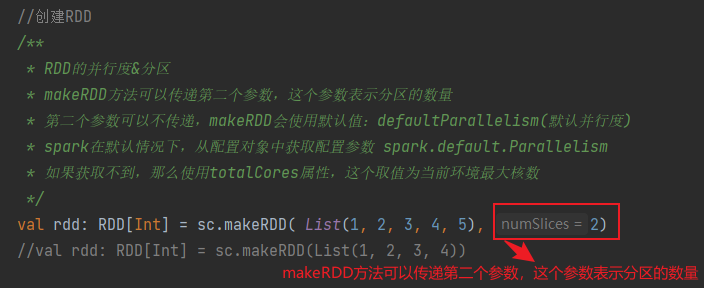
* RDD的并行度&分区
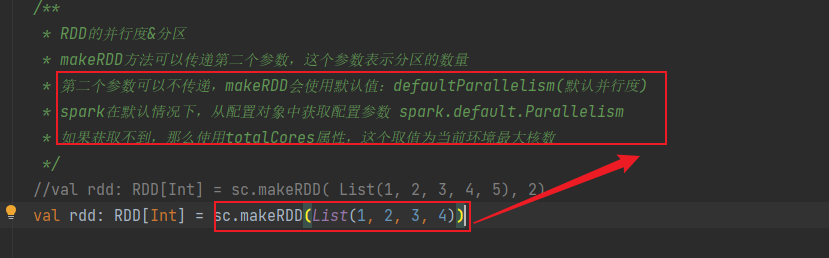
* makeRDD方法可以传递第二个参数,这个参数表示分区的数量
* 第二个参数可以不传递,makeRDD会使用默认值:defaultParallelism(默认并行度)
* spark在默认情况下,从配置对象中获取配置参数 spark.default.Parallelism
* 如果获取不到,那么使用totalCores属性,这个取值为当前环境最大核数
*/
val rdd: RDD[Int] = sc.makeRDD( List(1, 2, 3, 4, 5), 2)
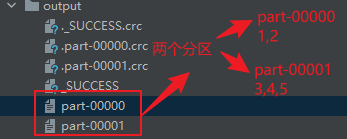
//将处理的数据保存成分区文件
rdd.saveAsTextFile("output")
//关闭环境
sc.stop()
}
第二个参数可以不传递,makeRDD会使用默认值:defaultParallelism(默认并行度)
在不传参数的情况下
spark在默认情况下,从配置对象中获取配置参数 spark.default.Parallelism
如果获取不到,那么使用totalCores属性,这个取值为当前环境最大核数
就是开头配置的环境
val sparkConf: SparkConf = new SparkConf().setMaster(“local[*]”).setAppName(“RDD”)
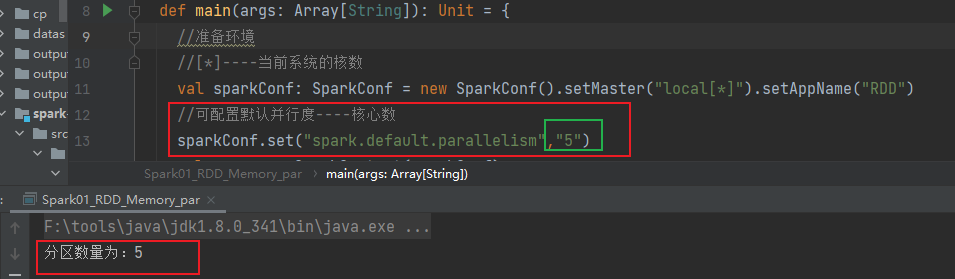
先获取sparkConf.set(“spark.default.parallelism”,“5”)
//[*]----当前系统的核数
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
//可配置默认并行度----核心数
sparkConf.set("spark.default.parallelism","5")
val sc = new SparkContext(sparkConf)
//创建RDD
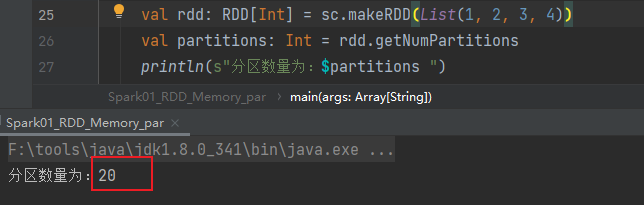
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val partitions: Int = rdd.getNumPartitions
println(s"分区数量为:$partitions ")
//关闭环境
sc.stop()
没有设置时,取值为当前环境最大核数
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val partitions: Int = rdd.getNumPartitions
println(s"分区数量为:$partitions ")
//将处理的数据保存成分区文件
//rdd.saveAsTextFile("output")
文件数据源分区
读取文件数据时,数据是按照 Hadoop 文件读取的规则进行切片分区,而切片规则和数据读取的规则有些差异。
默认分区数
def main(args: Array[String]): Unit = {
//准备环境
//[*]----当前系统的核数
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//创建RDD
//textFile可以将文件作为数据处理的数据源,默认也可以设定分区
/**
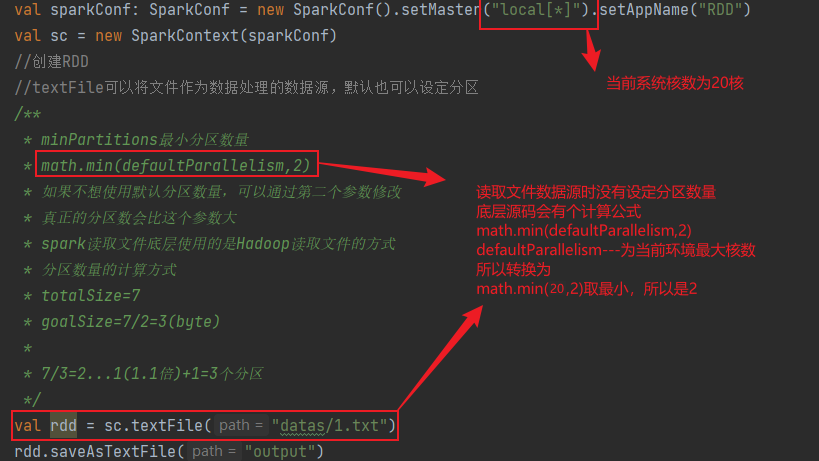
* minPartitions最小分区数量
* math.min(defaultParallelism,2)
* 如果不想使用默认分区数量,可以通过第二个参数修改
* 真正的分区数会比这个参数大
* spark读取文件底层使用的是Hadoop读取文件的方式
* 分区数量的计算方式
* totalSize=7
* goalSize=7/2=3(byte)
*
* 7/3=2...1(1.1倍)+1=3个分区
*/
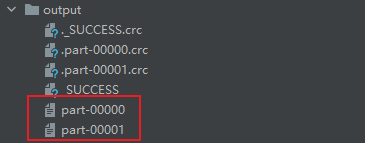
val rdd = sc.textFile("datas/1.txt")
rdd.saveAsTextFile("output")
//关闭环境
sc.stop()
}
指定分区数
文件分区数量的计算方式
文件为
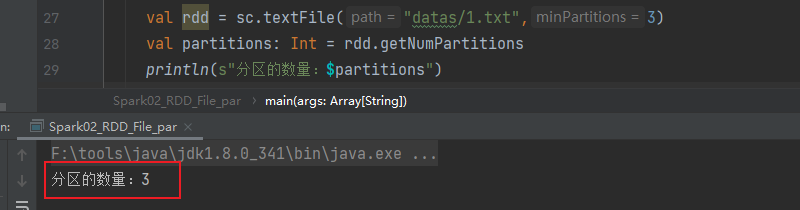
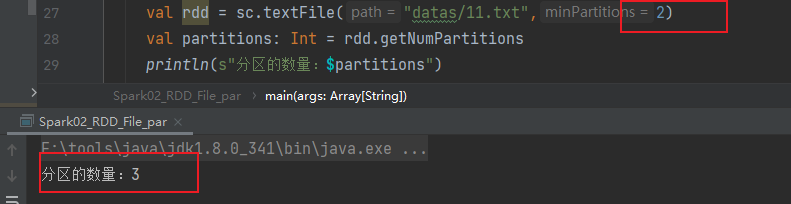
如果指定分区数量设置为2,但实际分区数量为3
文件大小有7个字节,但文件内只有1 2 3
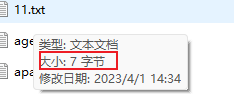
其实是包含了回车换行,也就是7个字节

计算公式
- totalSize=7
- goalSize=7/2=3(byte)—表示每个分区有3个字节
- 7/3=2…1(1.1倍)+1=3个分区----两个分区不够,剩余的数占每个分区的字节数大于10%等同于产生新的分区,如果小于10%不会产生新的分区
所以就会产生三个分区。















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









