









 本文介绍了如何在SpringBoot项目中集成LiteFlow,包括配置依赖、组件定义、规则文件编写、动态构建流程、数据上下文管理以及高级特性。通过这些步骤,实现大数据平台中数据流式任务的可编排处理。
本文介绍了如何在SpringBoot项目中集成LiteFlow,包括配置依赖、组件定义、规则文件编写、动态构建流程、数据上下文管理以及高级特性。通过这些步骤,实现大数据平台中数据流式任务的可编排处理。
文章目录
题外话:
最近喜欢上骑摩托车了,不是多大排量的摩托车,小排量踏板,当骑车的时候真的可以获得快乐抛却烦恼,八九十的速度也是可以到的,但是还是要管住右手,慢慢骑。希望以后可以换个自己喜欢的巡航,骑帅不骑快。
背景:
最近在做大数据平台,数据治理相关,大数据量数据的清洗、转换、补全、融合等操作处理,最开始的设计的是不同数据任务,但是这样的话就比较固化,可拓展性不强。基于对数据平台的产品化考虑,决定将数据的流式任务处理具象成流程化处理。
在码云及git上面看了些开源项目,研究了一下,感觉使用场景匹配度不是太高,并且代码及功能有些重,决定还是使用LiteFlow自己开发相应的流程组件,最终实现数据流程任务的可编排。
学习LiteFlow
具体可以查看下官方文档:LiteFlow官方文档,该说不说这个文档实在是太全面了,讲解也比较详细。
从HelloWorld到安装运行,从规则文件到各种组件,然后是数据上下文、动态构造及各种高级特性,接下来简单说一下一般场景下使用到的重要功能点:
spring boot整合LiteFlow
依赖
LiteFlow提供了liteflow-spring-boot-starter依赖包,提供自动装配功能:
<dependency>
<groupId>com.yomahub</groupId>
<artifactId>liteflow-spring-boot-starter</artifactId>
<version>2.11.0</version>
</dependency>
配置
组件定义
在依赖了以上jar包后,你需要定义并实现一些组件,确保SpringBoot会扫描到这些组件并注册进上下文。
@Component("a")
public class ACmp extends NodeComponent {
@Override
public void process() {
//do your business
}
}
以此类推再分别定义b,c组件:
@Component("b")
public class BCmp extends NodeComponent {
@Override
public void process() {
//do your business
}
}
@Component("c")
public class CCmp extends NodeComponent {
@Override
public void process() {
//do your business
}
}
spring boot配置文件
然后,在你的SpringBoot的application.properties或者application.yml里添加配置(这里以properties为例,yml也是一样的)
liteflow.rule-source=config/flow.el.xml
规则文件的定义
同时,你得在resources下的config/flow.el.xml中定义规则,SpringBoot在启动时会自动装载规则文件。
<?xml version="1.0" encoding="UTF-8"?>
<flow>
<chain name="chain1">
THEN(a, b, c);
</chain>
</flow>
执行
可以在Springboot任意被Spring托管的类中拿到flowExecutor,进行执行链路:
@Component
public class YourClass{
@Resource
private FlowExecutor flowExecutor;
public void testConfig(){
LiteflowResponse response = flowExecutor.execute2Resp("chain1", "arg");
}
}
组件
包括:普通组件、选择组件、条件组件、次数循环组件、条件循环组件、迭代循环组件及退出循环组件。
以普通组件为例:
普通组件节点需要继承NodeComponent,可用于THEN和WHEN关键字中。需要实现process方法:
@LiteflowComponent("a")
public class ACmp extends NodeComponent {
@Override
public void process() {
System.out.println("ACmp executed!");
}
}
@LiteflowComponent继承自@Component,如果你在spring体系的环境里,组件里可以任意注入spring的bean进行使用。@LiteflowComponent的参数a,就是你在写EL规则时需要用到组件ID。
组件中会有需要可以覆盖重写的方法, 具体就不罗列了,可以看下liteflow官方文档。
EL规则
LiteFlow在2.8.X版本中设计了非常强大的规则表达式。一切复杂的流程在LiteFlow表达式的加持下,都异常丝滑简便。
你只需要很短的时间即可学会如何写一个很复杂流程的表达式。简单列举下串行及并行的EL规则表达式写法:
串行
关键字:THEN,必须大写
<chain name="chain1">
THEN(a, b, c, d);
</chain>
<chain name="chain1">
THEN(a, b, c, d);
</chain>
上面两种写法是等价的。
并行
关键字:WHEN,必须大写。
<chain name="chain1">
WHEN(a, b, c);
</chain>
可以串行。并行组合:
<chain name="chain1">
THEN(
a,
WHEN(b, c, d),
e
);
</chain>
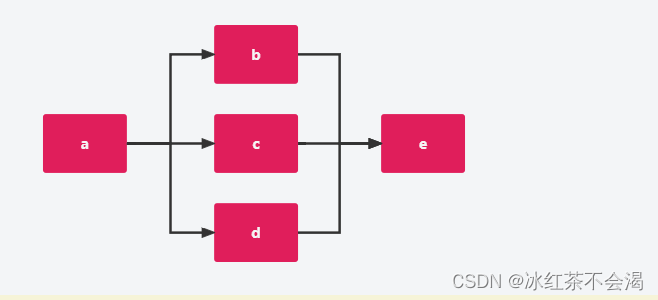
动态构建组件
一般业务场景其实并不会是固定的流程,而是动态的,后端搭配前端完成流程编排,像上面一样固定的组件其实实际使用场景较少,适用于固定流程的。但是如果流程不固定的话,就需要用到动态构建组件了。
贴一下官方代码吧:
//构建一个普通组件
LiteFlowNodeBuilder.createCommonNode().setId("a")
.setName("组件A")
.setClazz("com.yomahub.liteflow.test.builder.cmp.ACmp")
.build();
//构建一个普通条件组件
LiteFlowNodeBuilder.createSwitchNode().setId("a")
.setName("组件A")
.setClazz("com.yomahub.liteflow.test.builder.cmp.ACmp")
.build();
动态构建普通组件,首先要定义好ACmp类,通过LiteFlowNodeBuilder.createCommonNode()方法链式构建组件,其中setId、setName、setClazz都是可以动态指定的。
这里的节点类(ACmp),不需要你去声明@LiteflowComponent或者@Component,如果项目是spring体系的话,LiteFlow框架会自动的把节点类注入到spring上下文中。
所以你仍旧可以在这个类(ACmp)里使用@Autowired和@Resource等等之类的spring任何注解,也就是说可以正常使用业务service。
贴一个ACmp代码吧:
/**
* @Description demo
* @Author: phli
* @CreateTime: 2023/9/13 17:05
*/
public class ACmp extends NodeComponent {
@Resource
private RestTemplate restTemplate;
@Override
public void process() throws Exception {
//自己的业务代码
Object object = restTemplate.postForObject("", null, Object.class);
}
@Override
public void onSuccess() throws Exception {
super.onSuccess();
}
@Override
public void onError(Exception e) throws Exception {
super.onError(e);
}
}
简单说一下:process就是该组件的执行逻辑方法,onSuccess方法即为流程的成功事件回调,onError就是流程的失败事件回调。一些组件中会用到的内置方法(我用到的):
- 获取组件id:getNodeId;
- 获取组件别名;getName;
- 获取流程的初始参数:getChainName;
- 获取流程的初始参数:getRequestData;
动态构建chain(流程)
上面讲过我们可以再规则配置文件中,会通过:
flowExecutor.execute2Resp("chain1", "arg");
//chain1
<?xml version="1.0" encoding="UTF-8"?>
<flow>
<chain name="chain1">
THEN(a, b, c);
</chain>
</flow>
执行chainName为”chain1“的流程。上面说过这种方式都比较死板,基本没有拓展性,我们还可以通过代码来构建chain:
LiteFlowChainELBuilder.createChain().setChainId("chainA").setChainName("chain2").setEL(
"THEN(a, b, WHEN(c, d))"
).build();
构建chain的前提是先要构建组件,不然流程创建会出错,提示找不到组件。chainId、chainName及EL都可以动态指定。
值得提一下的是,由于用构造模式是一个链路一个链路的添加,如果你用了子流程,如果chain1依赖chain2,那么chain2要先构建。否则会报错。
销毁chain
可以通过以下代码销毁chain:
FlowBus.removeChain("你的流程ID")
高级特性
包括但不限于:前后置组件、组件回滚、组件切面、异步线程池、组件监控、替补组件、组件重试等等。具体就不展开说了,可以看下官方文档,真的很全:
整个流程节点如果多的话,执行比较慢可以将放到异步逻辑里面。
数据上下文
每个chain中的每个组件节点肯定会需要数据使用、交换以及数据共享,很多场景下更多的是同一个流程公用一份数据集合。我最开始使用的是ThreadLocal,以chiainId为key,value即为共享数据。但是看了下文档有专门说明数据上下文的概念及使用,个人感觉内置的功能在数据隔离、线程安全及数据性能方面应该会更好一些,所以改为使用内置的数据上下文
要做到可编排,一定是消除每个组件差异性的。如果每个组件出参入参都不一致,那就没法编排了。
概念
每个组件只需要从数据上下文中获取自己关心的数据即可,而不用关心此数据是由谁提供的,同样的,每个组件也只要把自己执行所产生的结果数据放到数据上下文中即可,也不用关心此数据到底是提供给谁用的。这样一来,就从数据层面一定程度的解耦了。从而达到可编排的目的。
一旦在数据上下文中放入数据,整个链路中的任一节点都是可以取到的。
使用
默认上下文
LiteFlow提供了一个默认的数据上下文的实现:DefaultContext。这个默认的实现其实里面主要存储数据的容器就是一个Map。
你可以通过DefaultContext中的setData方法放入数据,通过getData方法获得数据。
DefaultContext虽然可以用,但是在实际业务中,用这个会存在大量的弱类型,存取数据的时候都要进行强转,颇为不方便。所以官方建议你自己去实现自己的数据上下文。
自定义上下文
你可以用你自己的任意的Bean当做上下文进行传入。LiteFlow对上下文的Bean没有任何要求。
自己定义的上下文实质上就是一个最简单的值对象,自己定义的上下文因为是强类型,更加贴合业务。
你可以像这样进行传入:
LiteflowResponse response = flowExecutor.execute2Resp("chain1", 流程初始参数, FlowContext.class);
其中FlowContext为自己定义的bean,FlowContext内部数据结构看自己业务定义没有固定合适,举个例子:
/**
* @Description 数据上下文
* @Author: phli
* @CreateTime: 2023/9/14 17:52
*/
@Data
public class FlowContext {
private List<Map<String, Object>> data;
}
在组件节点内可以通过以下方式获取数据上下文进行数据的获取及设置:
FlowContext context = this.getContextBean(FlowContext.class);
//或者你也可以用这个方法去获取上下文实例,和上面是等价的
//CustomContext context = this.getFirstContextBean();
//设置data
//context.setData();
多上下文
执行的时候同时初始化你传入的多个上下文。在组件里也可以根据class类型很方便的拿到。这个比较简单就不举例子了。
核心功能
参考了一下相关文章自己画了一个图:
流程图

下面按照执行顺序简单说明下每个核心功能组件是干啥的:
解析器parser
作用就是用来解析流程配置的规则,也就是将你配置的规则文件解析成Java代码来运行。支持的文件格式有xml、json、yml。前面讲过可以再配置文件里面配置node,chain及EL表达式等。这个组件就是将配置文件解析出来,对于xml来说,解析器会将标签解析成Node对象,将解析成Chain对象等。
可以简单看下上面流程图中举例的BaseXmlFlowParser:
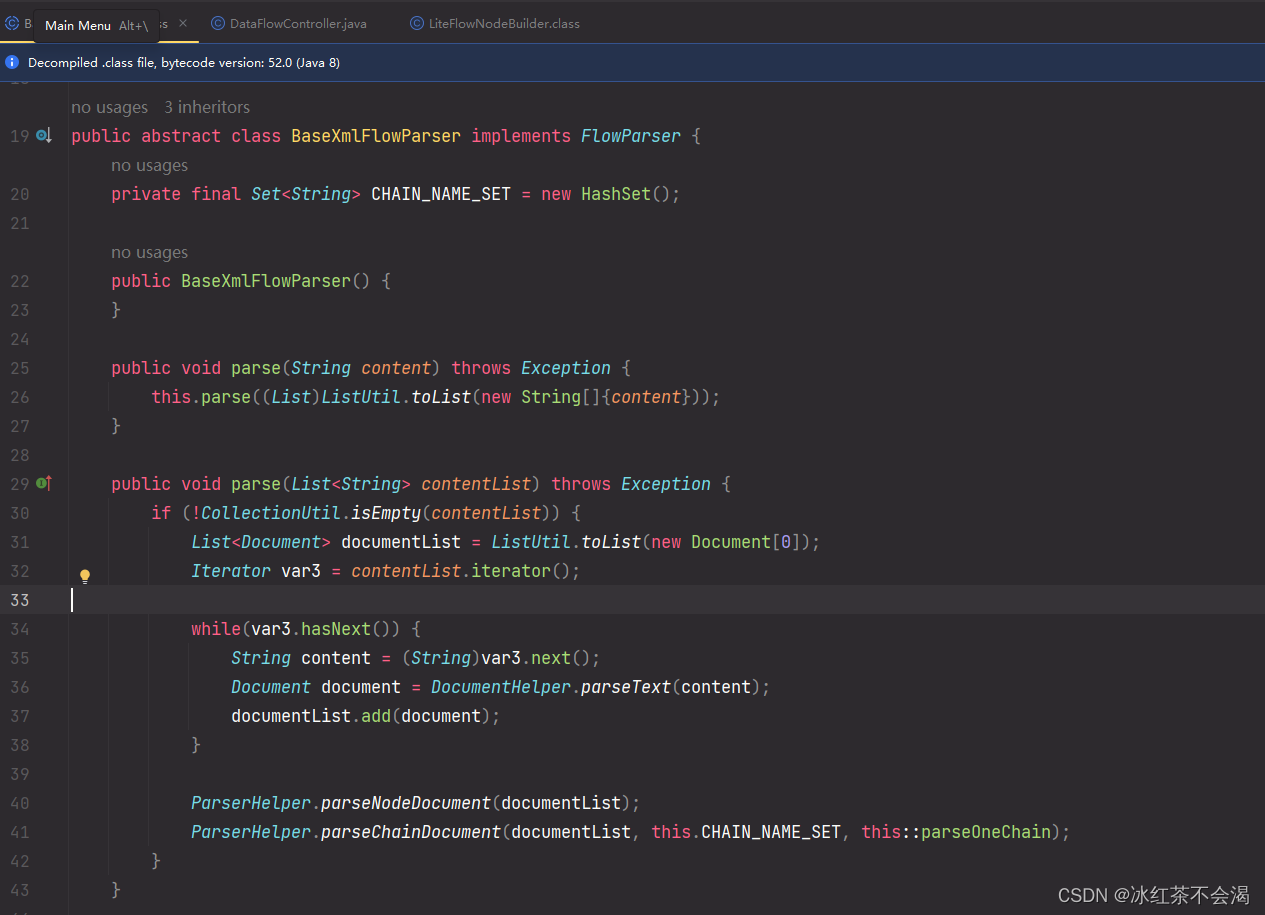
就是获取xml属性然后解析节点及chain。
FlowBus
可以存储parser解析出来的node及chain的元数据信息。可以看下源码:
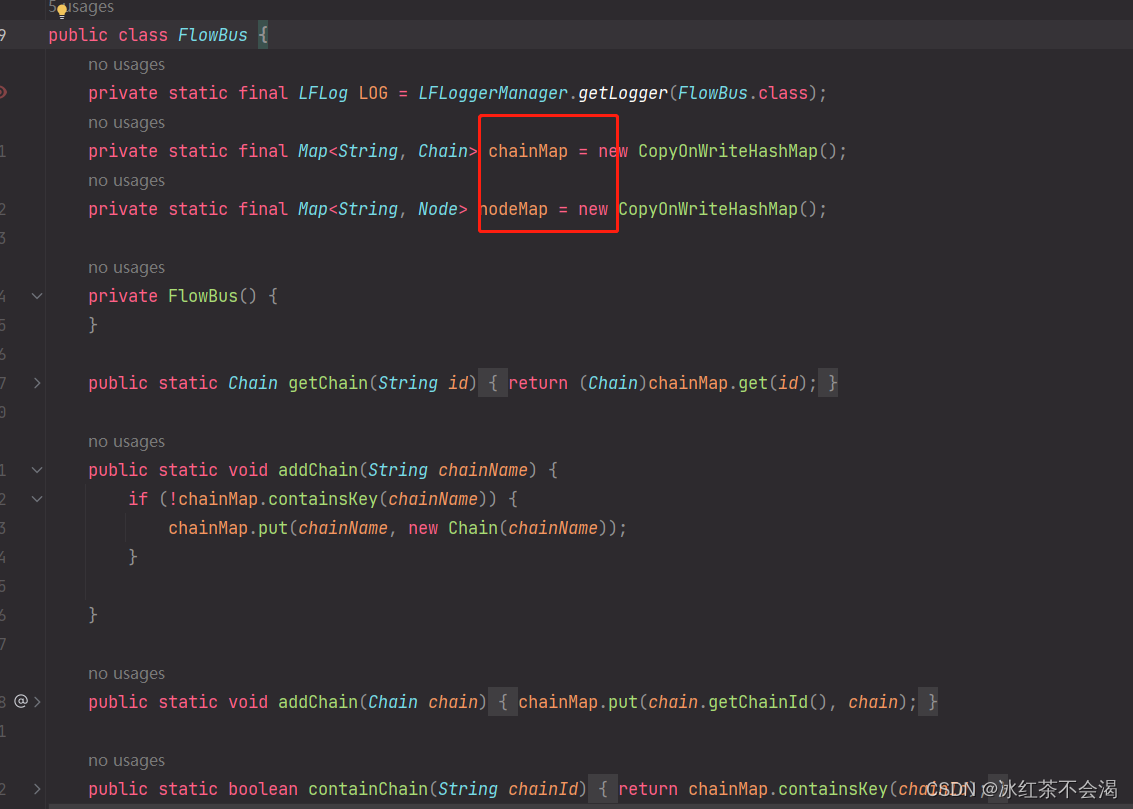
线程安全的chainMap和nodeMap存储node及chain信息。还包括一些其他方法:addChain、addNode、containChain及removeChain等。
总结
以上,可以实现一个简单的流程引擎编排功能。


















 4847
4847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











