






Yelp数据集的结构
第一章:yelp_academic_dataset_review.json的结构
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
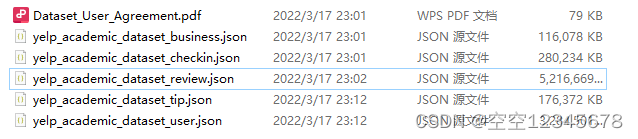
一、Yelp数据集组成
Yelp数据集主要由五部分组成,分别是
yelp_academic_dataset_business.json:包含了Yelp商家信息的数据
每个商家的信息都以JSON格式存储,包括商家的名称、地址、经纬度坐标、类别(如餐厅、咖啡馆等)、营业时间、星级评分以及其他相关信息。这个文件用于描述Yelp平台上注册的商家的基本信息。
yelp_academic_dataset_checkin.json:包含用户在Yelp平台上进行签到(Check-in)的数据
签到是指用户在实体店面(如餐厅、商店等)实际到达的时间点记录。这个文件存储了用户签到的时间和商家的信息,可以用于分析用户活动模式和商家受欢迎程度。
yelp_academic_dataset_review.json:包含了Yelp用户对商家的评论数据
每条评论都以JSON格式存储,包括用户ID、商家ID、评分、评论文本、评论时间等信息。这个文件是Yelp数据集中最重要的部分,用于进行情感分析、自然语言处理和用户行为分析等任务。
yelp_academic_dataset_tip.json: 包含用户在Yelp平台上对商家的小费(Tip)数据
小费是指用户给予商家的建议、提示或推荐,类似于评论但通常更为简短。每条小费数据都包含了用户ID、商家ID、小费文本、小费时间等信息。
yelp_academic_dataset_user.json: 包含了Yelp平台上用户的基本信息
每个用户的数据都以JSON格式存储,包括用户ID、姓名、注册时间、好友列表、评分分布、评论数量等信息。这个文件提供了关于Yelp用户的一些统计信息和行为模式。
这里我们只讨论yelp_academic_dataset_review.json
二、yelp_academic_dataset_review.json文件
1、首先将文件的前20行导出
import json
file_path="./yelp-dataset/yelp_academic_dataset_review.json"
output_file_path="./yelp_review.txt"
with open(file_path, 'r') as file:
# 创建一个空列表来保存前20行数据
json_lines = []
# 逐行读取JSON文件并解析每一行的数据
for i, line in enumerate(file):
try:
data = json.loads(line)
json_lines.append(json.dumps(data)) # 将解析后的数据重新转换为JSON格式的字符串并保存到列表中
# 判断是否已经读取了20行数据,如果是,则跳出循环
if i == 19:
break
except json.JSONDecodeError:
print(f"Error decoding JSON on line {i+1}")
# 将前20行的JSON数据保存到txt文件中
with open(output_file_path, 'w') as output_file:
for line in json_lines:
output_file.write(line + '\n')
print("前20行JSON数据已保存到txt文件中。")
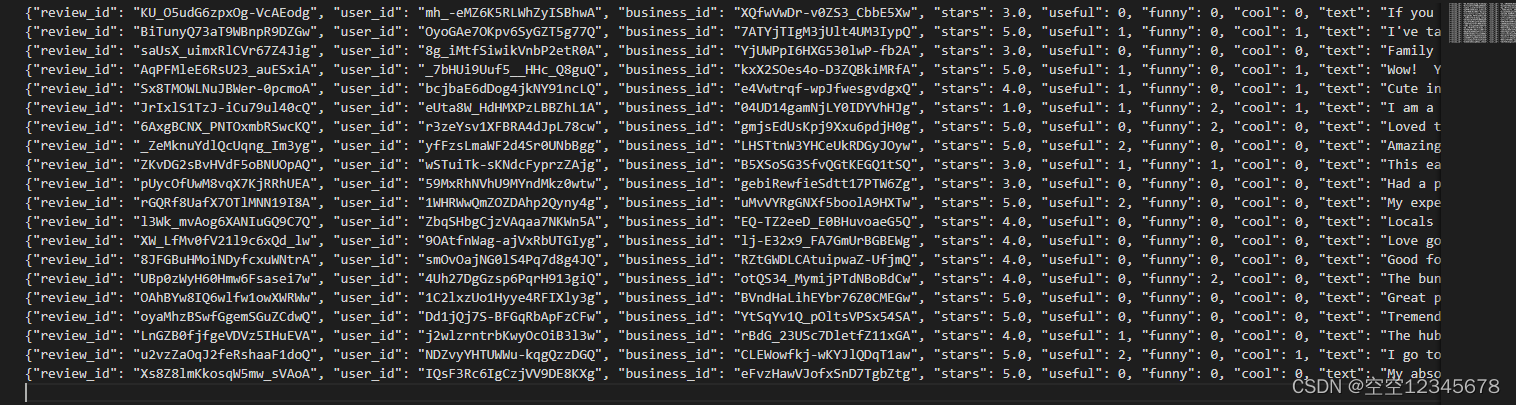
2、数据(一行)
{
“review_id”: “KU_O5udG6zpxOg-VcAEodg”,
“user_id”:“mh_-eMZ6K5RLWhZyISBhwA”, “business_id”: “XQfwVwDr-v0ZS3_CbbE5Xw”,
“stars”: 3.0,
“useful”: 0,
“funny”: 0,
“cool”: 0,
“text”: “If you decide to eat here, just be aware it is going to take about 2 hours from beginning to end. We have tried it multiple times, because I want to like it! I have been to it’s other locations in NJ and never had a bad experience. \n\nThe food is good, but it takes a very long time to come out. The waitstaff is very young, but usually pleasant. We have just had too many experiences where we spent way too long waiting. We usually opt for another diner or restaurant on the weekends, in order to be done quicker.”,
“date”: “2018-07-07 22:09:11”
}
这段JSON数据包含了一条Yelp用户对商家的评论信息,以下是该数据的中文解释:
1. "review_id": "KU_O5udG6zpxOg-VcAEodg"
评论的唯一标识符,用于区分不同的评论记录。
2. "user_id": "mh_-eMZ6K5RLWhZyISBhwA"
用户的唯一标识符,用于区分不同的用户。
3. "business_id": "XQfwVwDr-v0ZS3_CbbE5Xw"
商家的唯一标识符,用于指示该评论所属的商家。
4. "stars": 3.0
用户对商家的星级评分,范围通常是1到5,表示对商家的满意程度。
5. "useful": 0
其他用户对这条评论的评价,表示该评论对其他用户是否有用。
6. "funny": 0
其他用户对这条评论是否觉得有趣或幽默。
7. "cool": 0
其他用户对这条评论是否觉得酷或有品味。
8. "text":
“If you decide to eat here, just be aware it is going to take about 2 hours from beginning to end. We have tried it multiple times, because I want to like it! I have been to its other locations in NJ and never had a bad experience. \n\nThe food is good, but it takes a very long time to come out. The waitstaff is very young, but usually pleasant. We have just had too many experiences where we spent way too long waiting. We usually opt for another diner or restaurant on the weekends, in order to be done quicker.”
用户撰写的评论文本,对用户在该商家就餐的体验和观点进行描述。
9. "date": "2018-07-07 22:09:11"
评论发布的日期和时间


















 2197
2197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









