






Effient Few-Shot复现
E-FewShot数据集处理
一、数据集
该模型数据集大致分为两种类型:合成数据集 和 带注释的数据集。
- 合成数据集:使用留一法创建合成数据集
- 带注释的数据集:使用FewShot的注释数据集
二、合成数据集
1.下载Amazon和Yelp原始数据集
- Amazon数据集:
Amazon数据集(用于实验的小数据集、大数据集) - Yelp数据集:
Yelp数据集(这个从Yelp官网下载,但是不太好用)
Yelp数据集(这个从Kaggle网站下载,下载Yelp比较方面)
(1)论文中要求Amazon数据集有四个方面的数据
Electronics 数据集
Clothing Shoes and Jewelry 数据集
Home and Kitchen 数据集
Health and Personal Care 数据集

如下图,在 Amazon数据集中下载
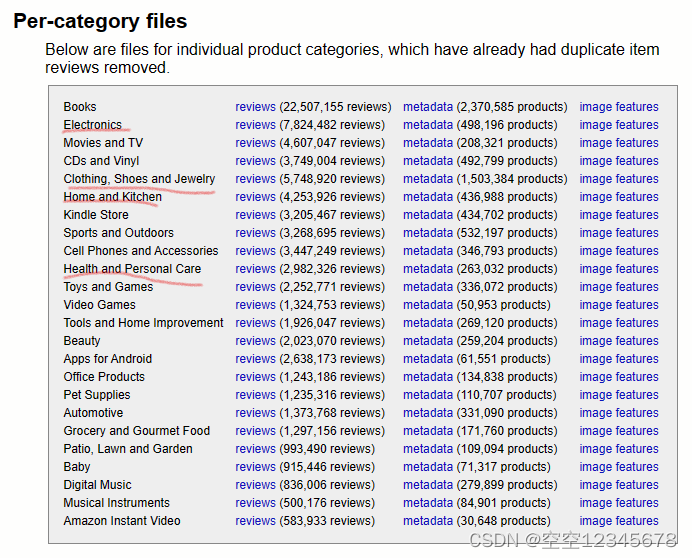
(2)Amazon网页中主要分为两部分:小数据集和正常数据集
小数据集
大数据集
(已下载,以后可以直接拿,不用在下载了)




(3)留一法创建合成数据集
在这里,我们使用留一法,来创建合成数据集。来源评论是根据 ROUGE-1 F 分数选择的。
[备注:其实每一个data之前应该都有“. ./”,但是由于我改动了一些代码,其他人运行可以原封不动]
python preprocessing/leave_one_out.py
--input-file-paths
../data/amazon/reviews/raw/Clothing_Shoes_and_Jewelry.json.gz
../data/amazon/reviews/raw/Electronics.json.gz
../data/amazon/reviews/raw/Health_and_Personal_Care.json.gz
../data/amazon/reviews/raw/Home_and_Kitchen.json.gz
--output-folder-path=data/amazon/reviews/l1o
--rev-num=10 --worker-num=80 --src-rev-min-len=20
--src-rev-max-len=120 --tgt-rev-min-len=20 --tgt-rev-max-len=120
--dataset=amazon --percentile=95 --measure=f
上面这段python命令是一个Python脚本命令,用于运行名为leave_one_out.py的预处理脚本。以下是命令的各个参数的解释:
* --input-file-paths:输入文件路径,指定要处理的输入文件的路径。在这个命令中,有四个输入文件被指定,分别是:
../data/amazon/reviews/raw/Clothing_Shoes_and_Jewelry.json.gz
../data/amazon/reviews/raw/Electronics.json.gz
../data/amazon/reviews/raw/Health_and_Personal_Care.json.gz
../data/amazon/reviews/raw/Home_and_Kitchen.json.gz
* --output-folder-path:输出文件夹路径,指定预处理后的文件将保存到的文件夹路径。在这个命令中,输出文件将保存在../data/amazon/reviews/l1o文件夹中。
* --rev-num:每个商品的评论数目。在这个命令中,每个商品将选择前10个评论。
* --worker-num:工作进程数。在这个命令中,使用80个工作进程来并行处理数据。
* --src-rev-min-len:源评论的最小长度。在这个命令中,源评论的最小长度被设置为20。
* --src-rev-max-len:源评论的最大长度。在这个命令中,源评论的最大长度被设置为120。
* --tgt-rev-min-len:目标评论的最小长度。在这个命令中,目标评论的最小长度被设置为20。
* --tgt-rev-max-len:目标评论的最大长度。在这个命令中,目标评论的最大长度被设置为120。
* --dataset:数据集名称。在这个命令中,数据集名称被设置为"amazon"。
* --percentile:百分位数。在这个命令中,百分位数被设置为95。
* --measure:度量指标。在这个命令中,度量指标被设置为"f"。
注意路径是否正确。
备注
这运行下来其实可以得到train、test、valid,但是由于代码中设置的是
| train | vaild | test |
|---|---|---|
| 90% | 10% | 0% |
processing/leave_one_out.py文件

所以没有test数据集,到后续运行可能会出现错误,所以这里需要手动改一下
小数据集运行结果
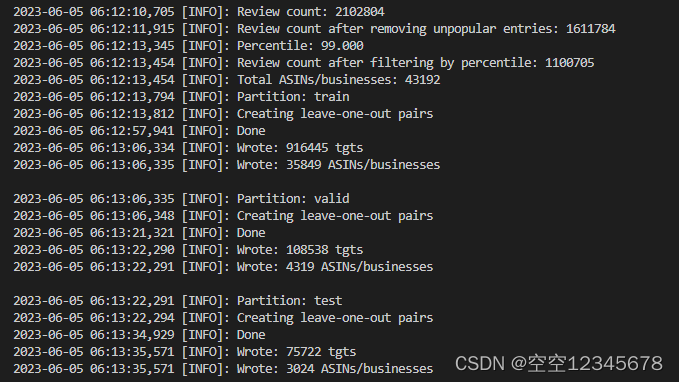
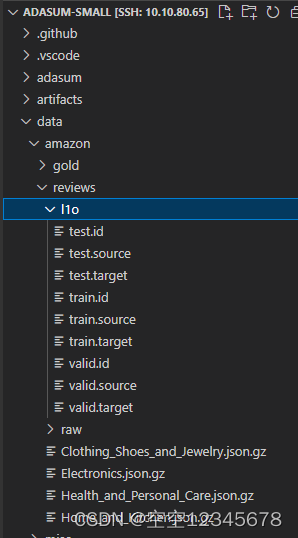
生成的文件
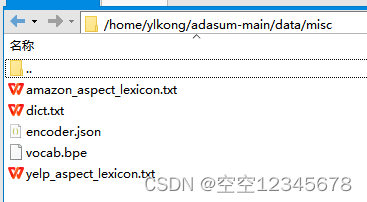
(4)词典
这里使用了作者的提供的词典,直接下载了
Amazon词典:Amazon词典下载地址
Yelp词典:Yelp词典下载地址
(5)Query/plan creation / 查询和计划创建
为每个拆分创建查询
python preprocessing/create_queries.py \
--input-folder-path=./data/amazon/reviews/l1o \
--output-folder-path=./data/amazon/reviews/l1o \
--lexicon-file-path=./data/misc/amazon_aspect_lexicon.txt
调试出错,shared文件不存在
但是调试时出现了一个错误
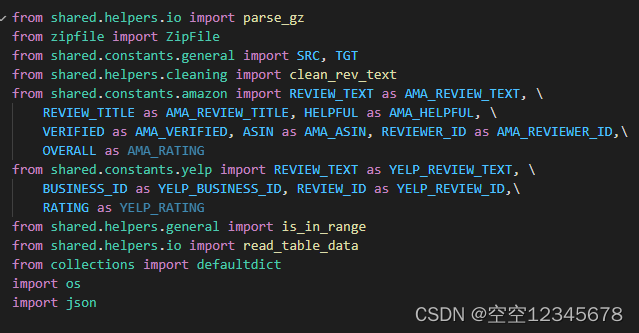
调试的时候出现了错误error,系统报错,shared不存在。
这是因为正常运行时,代码是在/home/ylkong/adasum-main中运行
ylkong@cu12:~/adasum-main$ python preprocessing/create_queries.py
--input-folder-path=./data/amazon/reviews/l1o
--output-folder-path=./data/amazon/reviews/l1o
--lexicon-file-path=./data/misc/amazon_aspect_lexicon.txt
> 2023-06-02 02:51:00,439 [INFO]: Split: train
但是如果调成Debug时,此时就会自动变成/home/ylkong,导致出错
(adasum) ylkong@cu12:~$ cd /home/ylkong ; /usr/bin/env
/home/ylkong/anaconda3/envs/adasum/bin/python
/home/ylkong/.vscode-server/extensions/ms-python.python-2023.8.0/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher 41615
-- /home/ylkong/adasum-main/preprocessing/create_queries.py
如何处理这个问题
解决办法:将debug的运行地址改为当前项目的地址.就是将launch.json文件中添加
"cwd": "${workspaceFolder}/adasum-main"
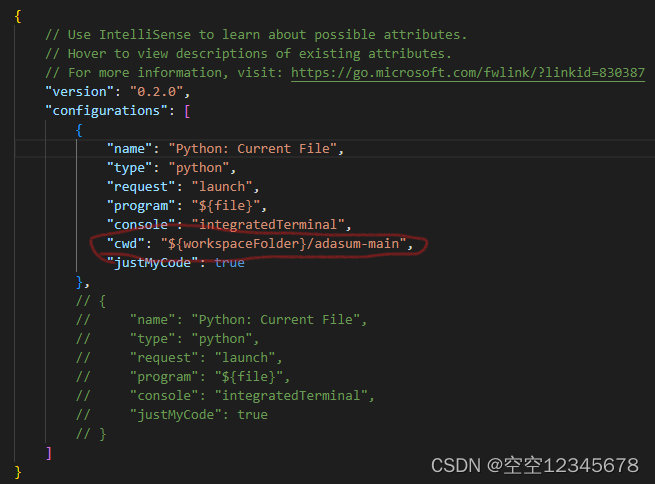
再重新运行代码,仍然出现shared文件夹不存在错误
由于操作问题,电脑重启,导致重新分割数据集,但是此时运行代码还是会出现error,系统报错shared文件夹不存在。
具体解决办法:解决办法
import sys
sys.path.append('/home/ylkong/adasum-main')
如果写成下面这个,仍然出错,因为加载的是项目根目录。
import sys
sys.path.append('/home/ylkong/adasum-main/shard')
总结
例如:以上就是今天要讲的内容,本文仅仅简单介绍了E-Fewshot论文中数据集的处理














 3088
3088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









