







贝叶斯分类算法思想
个人博客:www.xiaobeigua.icu
公式:
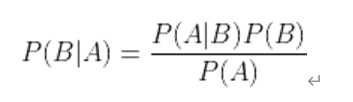
步骤:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集
2、统计得到在各类别下各个特征属性的条件概率估计。即
![]()
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
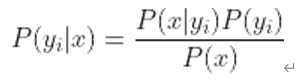
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
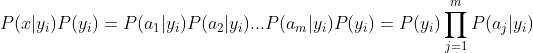
优点:接受大量数据训练和查询时所具备的高速度,支持增量式训练;对分类器实际学习的解释相对简单
缺点:无法处理基于特征组合所产生的变化结果
例子:
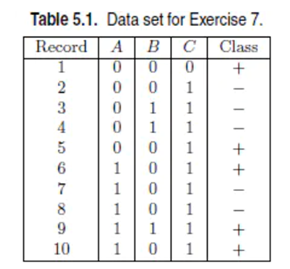
(1)估计条件概率P(A|+),P(B|+),P(C|+),P(A|-),P(B|-),P(C|-)。
P(A=1|+)=P(A=1,+)/P(+)=0.3/0.5=0.6
P(A = 1|−) = 2/5 = 0.4, P(B = 1|−) = 2/5 = 0.4,
P(C = 1|−) = 1, P(A = 0|−) = 3/5 = 0.6,
P(B = 0|−) = 3/5 = 0.6, P(C = 0|−) = 0;
P(B = 1|+) = 1/5 = 0.2, P(C = 1|+) = 2/5 = 0.4,
P(A = 0|+) = 2/5 = 0.4, P(B = 0|+) = 4/5 = 0.8,
P(C = 0|+) = 3/5 = 0.6.
(2)根据(1)中条件概率,使用朴素贝叶斯方法预测测试样本(A=0,B=1,C=0)的类标号。
设P(A=0,B=1,C=0)=K
P(+|A=0,B=1,C=0)=P(A=0,B=1,C=0,+)/P(A=0,B=1,C=0)
=P(A=0,B=1,C=0|+)P(+)/K
=P(A=0|+)P(B=1|+)P(C=0|+)P(+)/K
=0.4*0.2*0.6*0.5/K=0.024/K
P(-|A=0,B=1,C=0|)=P(A=0,B=1,C=0|-)P(-)/K
=0
由于P(-|A=0,B=1,C=0)<P(+|A=0,B=1,C=0),故类标号为+
(3)使用m估计方法(p=1/2且m=4)估计条件概率。
P(A=1|+)=(3+4*1/2)/(5+4)=5/9
P(A = 0|+) = (2 + 2)/(5 + 4) = 4/9,
P(A = 0|−) = (3+2)/(5 + 4) = 5/9,
P(B = 1|+) = (1 + 2)/(5 + 4) = 3/9,
P(B = 1|−) = (2+2)/(5 + 4) = 4/9,
P(C = 0|+) = (3 + 2)/(5 + 4) = 5/9,
P(C = 0|−) = (0+2)/(5 + 4) = 2/9.
(4)同(b),使用(c)中条件概率。
Let P(A = 0,B = 1, C = 0) = K
P(+|A = 0,B = 1, C = 0)
= P(A = 0,B = 1, C = 0|+) × P(+)/P(A = 0,B = 1, C = 0)
=P(A = 0|+)P(B = 1|+)P(C = 0|+) × P(+)/K
=(4/9) × (3/9) × (5/9) × 0.5/K
= 0.0412/K
P(−|A = 0,B = 1, C = 0)= 0.0274/K
类标号是+
(5)比较两种方法,哪种好?
当其中一个条件概率为零时,使用m-估计概率方法对条件概率的估计更好,因为我们不希望整个表达式变成零。















 1750
1750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









