







NSGA-III是在NSGA-II的基础上,为了解决在目标数超越3个乃至更多的情况下,拥挤度指标不再适应的问题,通过引入参考点的概念来解决这个问题。与NSGA-II相比,NSGAIII仍然适配了他的交叉变异算子,快速非支配排序算子,但从快速非支配排序之后,NSGA-III开始与NSGA-II产生了分歧,在NSGA-II中这里应该进行拥挤度划分,但是NSGAIII是开始了相关的参考点计算,下面进行详细解释
1.根据帕累托分层生成新种群
for (int i=0;i<s.size();i++){
//首先把帕累托等级给分开
if (front.keySet(). contains ( s.array.get(i).rank)){
front.get(s.array.get(i).rank).add(s.array.get(i));
} else{
front_l=new ArrayList<>();
front_l.add(s.array.get(i));
front.put(s.array.get(i).rank,front_l);
}
}这里可以使用一个HashMap来实现,根据每一个解的rank值作为key,rank值相同的作为同一个帕累托层,这样就生成了根据帕累托层分辨的种群front
int rankingIndex=1;//表示第几层,因为是从帕累托等级为1开始的,所以,你懂的
int candidateSolutions=0;
while(candidateSolutions<maxsize){
candidateSolutions+=front.get(rankingIndex).size();
if ((newS.size()+front.get(rankingIndex).size()<=maxsize)){
//如果没有溢出就往里面添加
front_l = front.get(rankingIndex);
for (int i = 0 ; i < front_l.size(); i++) {
newS.add(front_l.get(i));
}
}根据划分好帕累托层的种群向新的种群news中添加个体,直到添加到第l-1层时,newS大小刚好不大于种群数。
2.寻找理想点
ideal-point理想点的含义是所有目标维度上目标值最小的点
List<Double> ideal_point;
int numberOfObjectives=pop.array.get(1).fitness.length;
ideal_point = new ArrayList<>(numberOfObjectives);
for (int f=0; f<numberOfObjectives; f+=1){
double minf = Double.MAX_VALUE;
for (int i=0; i<front.get(1).size(); i+=1) // min values must appear in the first front
{
minf = Math.min(minf, front.get(1).get(i).fitness[f]);
}
ideal_point.add(minf);
}
return ideal_point;
}3.根据ASF函数寻找额外点
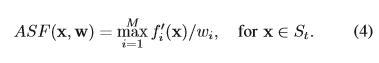
ASF函数就是对所有个体在固定一个维度的情况下其他维度上的数同时除以一个极小数,然后取这些个体上的最大值作为ASF函数值
List<NSGAIIIDoubleSolution> extremePoints = new ArrayList<>();
int numberOfObjectives=population.array.get(1).fitness.length;
NSGAIIIDoubleSolution min_indv = null 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1026
1026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









