







Group by
group by是根据某一个字段对数据进行分组;
比如我们这里有个数据

我们针对job进行分组
select job,count(*) from empp group by job;
但是呢,一定要记住,我们根据某一个字段进行分组了,比如这里进行分组了,如果还要打印其他字段。
比如:
select ename,job from empp group by job;这里就会有猜测,到底一个组里面,这么多ename,到底要打印哪个ename,这里hive为了避免这种猜测,就认为这种形式是不符合规范的,所以,我们在进行group by时,一定不能出现这种情况。除非,我们使用了其他的聚合函数,比如count,sum,min,max等等,能够从一个组中挑选某一个确定值,这样同样可以避免这种猜测,就能够执行。
还有就是group by的去重效果
group是自动根据group的字段进行去重,这个和distinct的效果差不多
我们先来梳理梳理group by的原理
group by其实是通过它的某一字段,将所以相同的那一列的信息全都弄到一起,形成一个虚拟表。
比如
a,1
b,3
a,2
c,5
c,7
a,4
b,9
进行groupby后
1
a2
4
3
b9
5
c7这是数据量小,但是如果数据量大的话,就可能不只是在一个分区进行操作了,就应该是多个分区,多个节点之间进行通信了。
这就带来了distinct和groupby同样由去重的功能,性能差别问题。
其实,在数据量小的时候,性能还真是不一样
 ‘
‘
比如面这个使用select count(distinct ename) from empp;我们可以看到数据量太小了map和reduce都只有一个,从而只需要15秒

但是我们使用groupby进行去重,就会拖慢速度。一共有两个job。
但是毕竟是大数据,这么小的数据量还用hive干嘛,直接用mysql不就可以解决了,数据量少说也需要个几十G的数据来吧。
当数据量大的时候,性能差别就不一样了
groupby会远远比distinct好很多,因为distinct会把所有的记录shuffle到一个reduce中,而groupby不一样,它是多个reduce,并且并发执行,性能肯定好很多。
所以一般都用groupby而不用hive。
groupby也可以对多个字段进行
无非就是多一个字段而已咯,没有别的难处
select ename,job from empp group by ename,job;
Order, Sort, Cluster, and Distribute By
order by:
就和sql里面的order by差不多,需要对所有的数据进行排序,看重的是整个数据,而且在hive.mapred.mode=strict模式下,必须使用limit限制输出的个数,因为数据量太大可能会造成集群崩溃的。
所以order不适用于数据量太大,因为它企图将所有的数据进行排序,节点之间的通信浪费了时间,排序也浪费了时间。
一般很少使用
sort by:
sort by是根据reduce排序的,他只能保证每一个reduce的顺序是用户定义的那个顺序,其他的不能够保证了。
distribute by:
能够根据字段进行分区。
当数据量大的时候,就可以使用distribute by 和sort by进行配合来排序了。
首先使用distribute将相同字段的分到一个reduce
然后使用sort根据那个字段进行排序,然后再根据其他字段进行排序。
cluster by:
可以被sort和distribute替代,是一样的效果。
join
和上面一样,先来几张表来做做实例


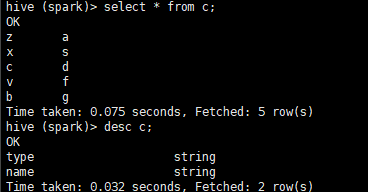
这里我们创建了三个表,a,b,c表
a与b通过 id字段连接
b与c通过type字段连接
select a.id,b.type,c.name from a join b on (a.id=b.id) join c on (c.type=b.type);
这里我们通过连接
需要我们注意的,我们要注意集中情况,并且来分辨job个数,以及一些优化问题
如果三个表连接的字段是一样的,那么就只会启动一个job,也就是一个mapreduce
但是如果字段不一样,那么就会启动两个job
这里的字段是不是一样,就是看中间的过度表也就是b表的连接字段是不是同一个字段
我们这里字段是不一样的,所以来看看执行情况

这里的job个数有两个,说明他们的分成了两个mapreduce过程。
这里我们必须了解一下join操作是怎样的原理的。
如果说一个join操作对应一个mapredue,那么一定会分成map端和reduce端。那么map端做什么,reduce又做什么呢。
在map阶段,将连接的id字段作为键,给后面的字段增一个tag信息,作为value,tag是确定来自哪个表。
然后根据key进行shuffle,shuffle之后再reduce端根据tag进行join。先将一个表加入内存,另一个表逐行进行对比。
这是在reduce端的join。但是如果开启优化
set hive.auto.convert.join=false;
set hive.auto.convert.join.noconditionaltask=false;
那么就会进行map端的join
比如上面哪个例子,开启优化后

这时候虽然是两个对比的字段不同,照理说应该要两个job,但是这里只生成了一个job,那是因为这里的两个join一个在map端,一个在reduce端,我们在进行map的时候就可以将一个表先读入内存,然后将第二个表的row读入内存对比。最后将结果shuffle到reduce端,与另一个表进行对比join。
这样原本的两个job需要两个shuffle过程,就只有一个shuffle了,减少了节点之间的通信与网络传输。加快了速度。数据小的情况下看不出来,数据大的时候就知道了。所以在优化的时候,一般就是减少shuffle的传输量。比如对map端的数据进行过滤。等等。
















 1259
1259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











