










Wide & Deep模型介绍
目标:
经典推荐深度模型 Wide & Deep。完整的paper名称是《Wide & Deep Learning for Recommender Systems》
Goggle在2016年提出的Wide & Deep模型
内容:
这篇知乎小哥写的挺简单明了的,直接摘抄过来,原文:知乎原文
本文介绍一个经典推荐深度模型 Wide & Deep。完整的paper名称是《Wide & Deep Learning for Recommender Systems》
一. 模型介绍
wide & deep的模型架构如下图所示
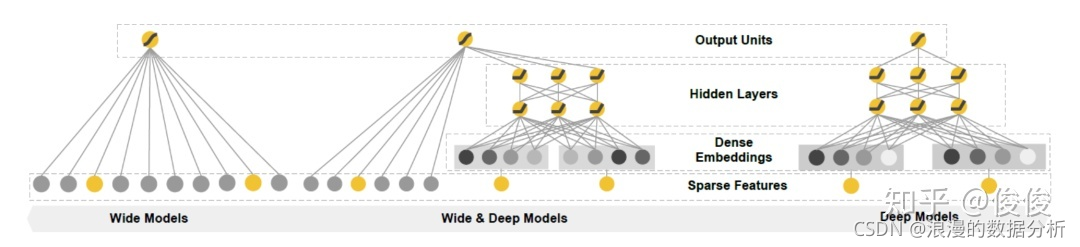
可以看到wide & deep模型分成wide和deep两部分。
- wide部分就是一个简单的线性模型,当然不仅仅是单特征的线性模型,实际中更多的利用特征进行交叉。比如用户经常买了书A又买书B,那么书A和书B两个特征具有很强的相关性,可以作为一个交叉特征进行训练。
- deep部分是一个前馈神经网络模型。
- 将线性模型和前馈神经网络模型合并在一起训练。
- wide部分可以理解为线性的记忆模型,
- deep部分擅长推理过程。
- 两者结合,就具有了推理和记忆功能,推荐结果更准确。
二. 推荐系统架构
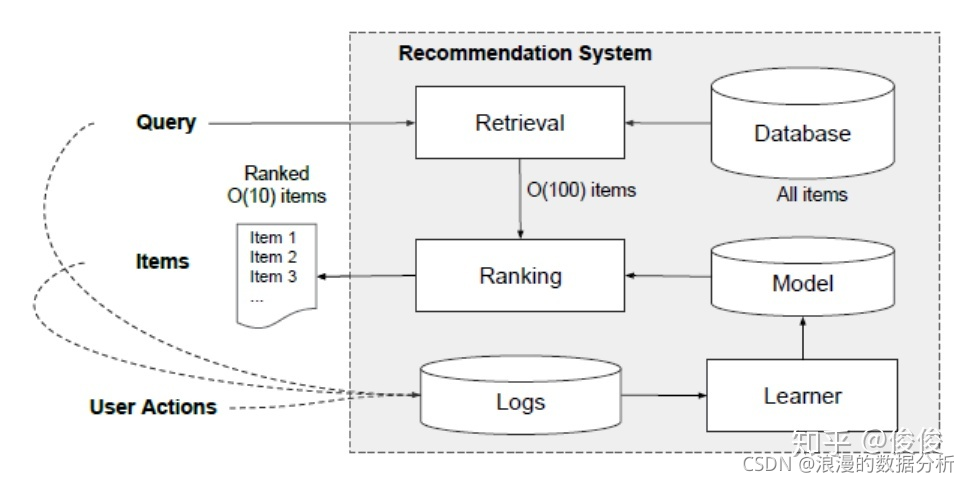
当一个用户请求过来的时候,推荐系统首先会从海量的item里面挑选出O(100) 个用户可能感兴趣的item(召回阶段)。然后这 O(100)个item将会输入到模型里面进行排序。根据模型的排序结果再选择出topN个item返回给用户。同时,用户会对展示的item进行点击,购买等等。最终,用户的feature,上下文feature,item的feature和user action会以log的信息保存起来,经过处理后生成新的训练数据,提供给模型进行训练。paper的重点放在使用wide & deep架构为基础的排序模型。
三. Wide部分
wide部分其实就是一个简单的线性模型 y = wx + b。y是我们的预测目标, x = [ x1, x2, … , xd] 是d个feature的向量,w = [w1, w2, … , wd]是模型的参数,b是bias。这里的d个feature包括原始的输入feature和经过转换的feature。
其中一种很重要的转换feature叫做cross-product转换。假如x1是性别,x1=0表示男性,x1=1表示女性。x2是爱好,x2=0表示不喜欢吃西瓜,x2=1表示喜欢吃西瓜。那么我们就可以利用x1和x2构造出新的feature,令x3=(x1 && x2),则x3=1表示是女生并且喜欢吃西瓜,如果不是女生或者不喜欢吃西瓜,则x3=0。这样经过转换的来的x3就是cross-product转化。这样转换的目的是为了获取交叉特征对预测目标的影响,给线性模型增加非线性。
这个步骤相当于人为提取了一些重要的两个特征的关系。tensorflow中使用函数tf.feature_column.crossed_column
四. Deep部分
deep部分就是前馈神经网络模型。对于高维稀疏的分类特征,首先会转化成低维的稠密的向量,比如embeding操作。然后作为神经网hidden layers的输入进行训练。Hidden layers的计算公式如下
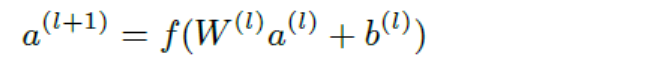
f是激活函数(例如ReLu),a是上一个hidden layer的输出, W是要训练的参数,b是bias
五. Wide和Deep一起训练
通过weight sum的方式将wide和deep的输出组合起来,然后通过logistic loss函数联合起来一起训练。对于wide的部分,一般采用FTRL进行训练。对于deep的部分则采用AdaGrad进行训练。
对于一个逻辑回归问题,预测公式如下所示
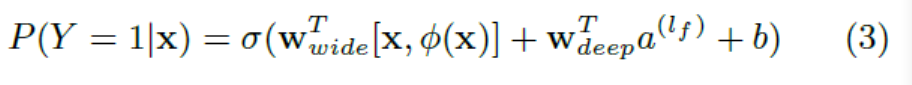
六. 系统实现
推荐系统的实现一共分成了三个阶段:数据生成,模型训练和模型服务。如下图所示
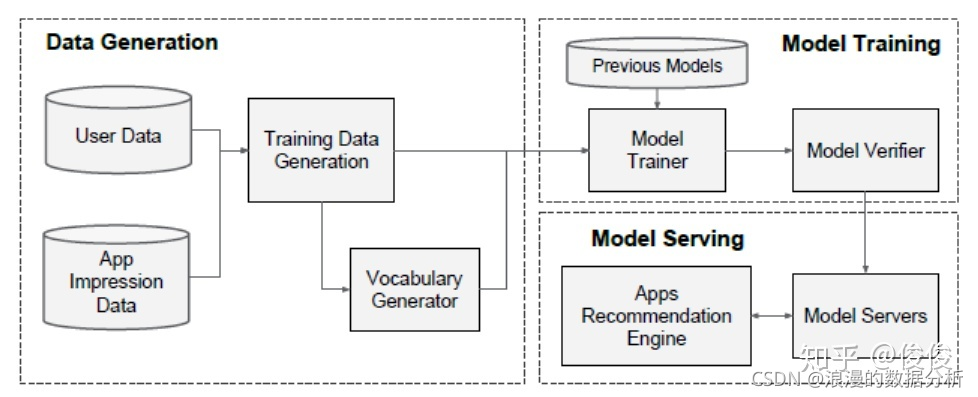
(1)数据生成阶段
在这个阶段,最近N天的用户和item将会用来生成训练数据。每条展示过的item将会对应有一个目标label。例如1表示用用户点击过,0表示用户没点击过。
图中的Vocabulary Generation主要用来做数据转换。例如需要把分类特征转换成对应的整数Id,连续的实数特征将会按照累积概率分布映射到[0, 1]等等。
(2)模型训练阶段
在数据生成阶段我们产生了包含稀疏特征,稠密特征和label的训练样本,这些样本将作为输入放入到模型里面训练。如下图所示
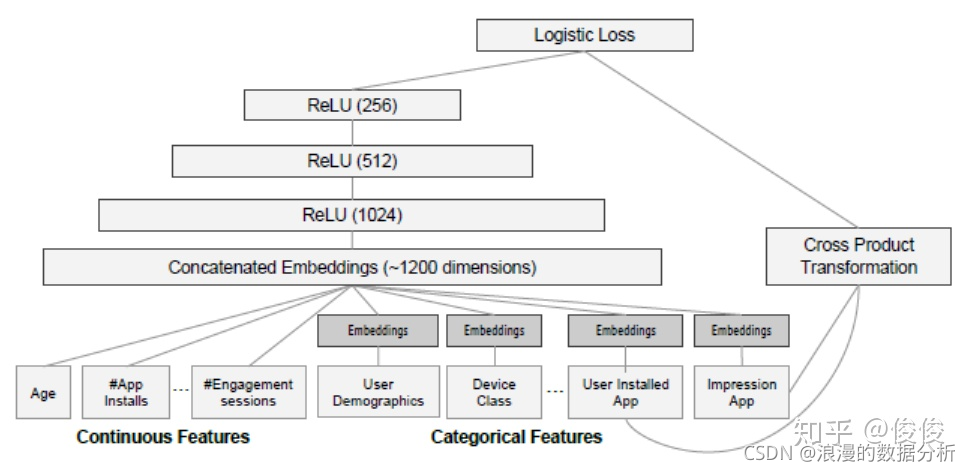
wide的部分包含了经过Cross Product转换的特征。对于deep的部分,分类特征首先会经过一层embedding,然后和稠密的特征concatenate起来后,经过3层的hidden layers,最后和wide部分联合起来通过sigmoid输出。
paper中还提到,因为google在训练的时候训练样本数超过5000亿,每次所有样本重新训练的成本和延迟非常大。为了解决这个问题,在初始化一个新的模型的时候,将会使用老模型的embedding参数和线性模型的weight参数初始化新模型。
(3)模型服务阶段
确认训练没问题以后,模型就可以上线。对于用户的请求,服务器首先会选出用户感兴趣的候选集,然后这些候选集将会放入到模型里面进行预测。将预测结果的分数从高到低排序,然后取排序结果的topN返回给用户。
- 从这里可以看到,实际上,Wide & Deep模型被用在了排序层,并没有用到召回层?为啥呢?因为Wide & Deep模型的训练和预测,运算还是比较多,比较费时,用在大规模物品的召回阶段,性能开销有点吃不消。
- 只有当召回层的数据,已经从几百万到几百以后,可以通过为Wide & Deep模型对召回的百级别的物品进行排序,得到前top N(N=20)。
七. 总结
Wide & Deep模型被用在了排序层。成wide和deep两部分。
* wide部分可以理解为线性的记忆模型,
* deep部分擅长推理过程。
* 两者结合,就具有了推理和记忆功能,推荐结果更准确。
八. 代码:
先实现deep,再实现wide,然后两者的数据结果进行拼接,在进行最终的SIGMOD激活。
deep部分
1、 相对类别特征(feature)进行embeding
# genre features vocabulary
genre_vocab = ['beijin', 'shanghai', 'shenzhen', 'chengdu', 'xian', 'suzhou', 'guangzhou']
GENRE_FEATURES = {
'city': genre_vocab
}
# all categorical features
categorical_columns = []
for feature, vocab in GENRE_FEATURES.items():
cat_col = tf.feature_column.categorical_column_with_vocabulary_list(
key=feature, vocabulary_list=vocab)
emb_col = tf.feature_column.embedding_column(cat_col, 10)
categorical_columns.append(emb_col)
2、 embeding向量在和常规的数值型特征进行拼接,送进MLP
# deep part for all input features
deep = tf.keras.layers.DenseFeatures(user_numerical_columns + categorical_columns)(inputs)
deep = tf.keras.layers.Dense(128, activation='relu')(deep)
deep = tf.keras.layers.Dense(128, activation='relu')(deep)
wide部分
1、 人为提取一些重要的,有关联关系的特征进行交叉。使用tensorflow中的函数:
tf.feature_column.crossed_column([movie_col, rated_movie]
2、然后对交叉后的特征进行multi-hot编码。
def indicator_column(categorical_column):
"""Represents multi-hot representation of given categorical column.
crossed_feature = tf.feature_column.indicator_column(tf.feature_column.crossed_column([movie_col, rated_movie], 10000))
3、 把稀疏矩阵变成稠密向量。
# wide part for cross feature
wide = tf.keras.layers.DenseFeatures(crossed_feature)(inputs)
wide+deep
两个模型的输出,拼接起来然后进行一个神经元的线性激活(或者神经元激活应该都行吧)。最终的到预测评分结果。
both = tf.keras.layers.concatenate([deep, wide])
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(both)
model = tf.keras.Model(inputs, output_layer)
程序运行情况:
提示:和前3篇文章相同的数据,预测结果:
5319/5319 [==============================] - 115s 21ms/step - loss: 67599.8828 - accuracy: 0.5150 - auc: 0.5041 - auc_1: 0.4693
Epoch 2/5
5319/5319 [==============================] - 114s 21ms/step - loss: 0.6549 - accuracy: 0.6526 - auc: 0.7150 - auc_1: 0.6806
Epoch 3/5
5319/5319 [==============================] - 118s 22ms/step - loss: 0.6326 - accuracy: 0.6722 - auc: 0.7363 - auc_1: 0.7065
Epoch 4/5
5319/5319 [==============================] - 116s 22ms/step - loss: 0.6173 - accuracy: 0.6792 - auc: 0.7410 - auc_1: 0.7133
Epoch 5/5
5319/5319 [==============================] - 113s 21ms/step - loss: 0.6067 - accuracy: 0.6840 - auc: 0.7435 - auc_1: 0.7176
1320/1320 [==============================] - 21s 15ms/step - loss: 0.6998 - accuracy: 0.5645 - auc: 0.5718 - auc_1: 0.5391
Test Loss 0.6997529864311218, Test Accuracy 0.5645247101783752, Test ROC AUC 0.5717922449111938, Test PR AUC 0.539068877696991
可以看到,训练时模型准确度更高,也更耗时。
但是在test训练集上的准确度没有很明显的提升。可能是test中新用户比较多。没有之前的行为数据,或者大量数据来训练,模型准确率不算太高。
九、完整代码GitHub:
地址:https://github.com/jiluojiluo/recommenderSystemForFlowerShop

















 1107
1107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









