







一、前言
1、记忆性
利用手工构造的交叉组合特征来使线性模型具有“记忆性”,使模型记住共现频率较高的特征组合,且可解释性强。
这种方式有着较为明显的缺点:首先,特征工程需要耗费太多精力。其次,因为模型是强行记住这些组合特征的,所以对于未曾出现过的特征组合,权重系数为0,无法进行泛化。
2、泛化性
为了加强模型的泛化能力,引入了DNN结构,将高维稀疏特征编码为低维稠密的Embedding vector,这种基于Embedding的方式能够有效提高模型的泛化能力。基于Embedding的方式可能因为数据长尾分布,导致长尾的一些特征值无法被充分学习,其对应的Embedding vector是不准确的,这便会造成模型泛化过度。
2016年,Google提出Wide&Deep模型,将线性模型与DNN很好的结合起来,在提高模型泛化能力的同时,兼顾模型的记忆性。
二、Wide&Deep
"记忆能力"可以被理解为模型直接学习并利用历史数据中物品和特征的“共现频率”的能力。 一般来说, 协同过滤、逻辑回归这种都具有较强的“记忆能力”, 由于这类模型比较简单, 原始数据往往可以直接影响推荐结果, 产生类似于“如果点击A, 就推荐B”这类规则的推荐, 相当于模型直接记住了历史数据的分布特点, 并利用这些记忆进行推荐。
"泛化能力“可以被理解为模型传递特征的相关性, 以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。比如矩阵分解, embedding等, 使得数据稀少的用户或者物品也能生成隐向量, 从而获得由数据支撑的推荐得分, 将全局数据传递到了稀疏物品上, 提高泛化能力。再比如神经网络, 通过特征自动组合, 可以深度发掘数据中的潜在模式,提高泛化等。
Wide&Deep模型的直接动机就是将两者进行融合, 使得模型既有了简单模型的这种“记忆能力”, 也有了神经网络的这种“泛化能力”, 这也是记忆与泛化结合的伟大模式的初始尝试。
1、Wide&Deep模型结构
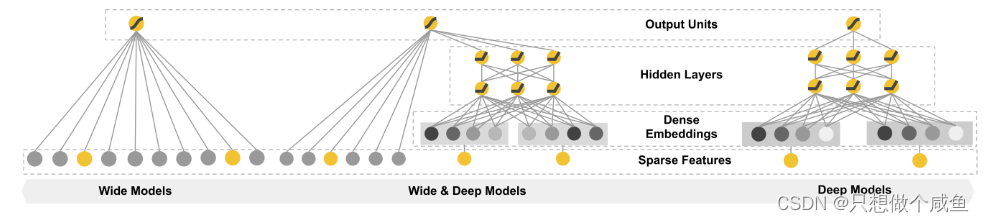
W&D模型把单输入层的Wide部分和Embedding+多层的全连接的部分连接起来, 一起输入最终的输出层得到预测结果。 单层的wide层善于处理大量的稀疏的id类特征, Deep部分利用深层的特征交叉, 挖掘在特征背后的数据模式。 最终, 利用逻辑回归, 输出层部分和Deep组合起来, 形成统一的模型。
(1)wide部分
Wide部分是一个广义的线性模型, 公式如下:

(2)deep部分
该部分主要是一个Embedding+MLP的神经网络模型。大规模稀疏特征通过embedding转化为低维密集型特征。

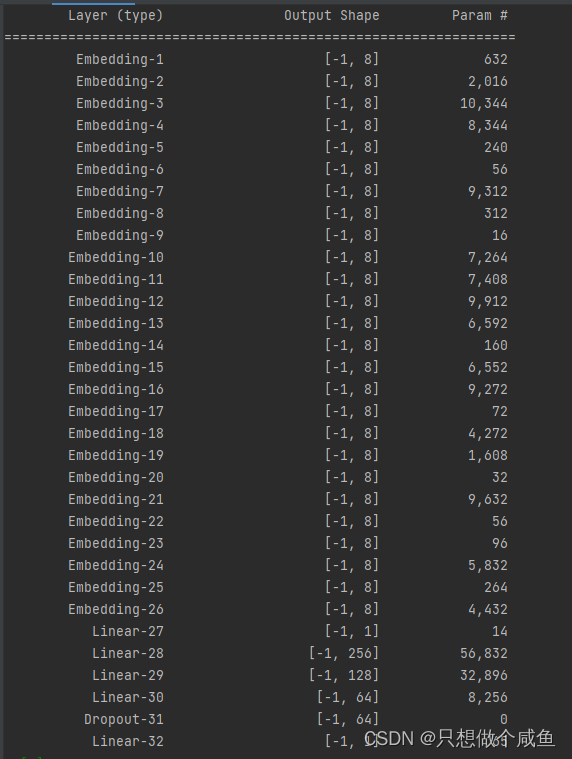
三、 Wide&Deep模型代码实现
class WideDeep(nn.Module):
def __init__(self, feature_columns, hidden_units, dnn_dropout=0.):
super(WideDeep, self).__init__()
self.dense_feature_cols, self.sparse_feature_cols = feature_columns
# embedding
self.embed_layers = nn.ModuleDict({
'embed_' + str(i): nn.Embedding(num_embeddings=feat['feat_num'], embedding_dim=feat['embed_dim'])
for i, feat in enumerate(self.sparse_feature_cols)
})
hidden_units.insert(0,
len(self.dense_feature_cols) + len(self.sparse_feature_cols) * self.sparse_feature_cols[0][
'embed_dim']) #13+26*8
self.dnn_network = Dnn(hidden_units)
self.linear = Linear(len(self.dense_feature_cols))
self.final_linear = nn.Linear(hidden_units[-1], 1)
def forward(self, x):
dense_input, sparse_inputs = x[:, :len(self.dense_feature_cols)], x[:, len(self.dense_feature_cols):]
sparse_inputs = sparse_inputs.long()
sparse_embeds = [self.embed_layers['embed_' + str(i)](sparse_inputs[:, i]) for i in
range(sparse_inputs.shape[1])] #从输入一列一列的导出到embed 提相应embedding,每一列就是单个特征,对应embed那个特征的列表
sparse_embeds = torch.cat(sparse_embeds, axis=-1)
dnn_input = torch.cat([sparse_embeds, dense_input], axis=-1)
# Wide
wide_out = self.linear(dense_input) #32*1
# Deep
deep_out = self.dnn_network(dnn_input) #32*64
deep_out = self.final_linear(deep_out) #32*1
# out
outputs = F.sigmoid(0.5 * (wide_out + deep_out))
return outputs网络结构如下:
补一下:以后怕迷糊
sparse_embeds = [self.embed_layers['embed_' + str(i)](sparse_inputs[:, i]) for i in
range(sparse_inputs.shape[1])] #从输入一列一列的导出到embed 提相应embedding,每一列就是单个特征,对应embed那个特征的列表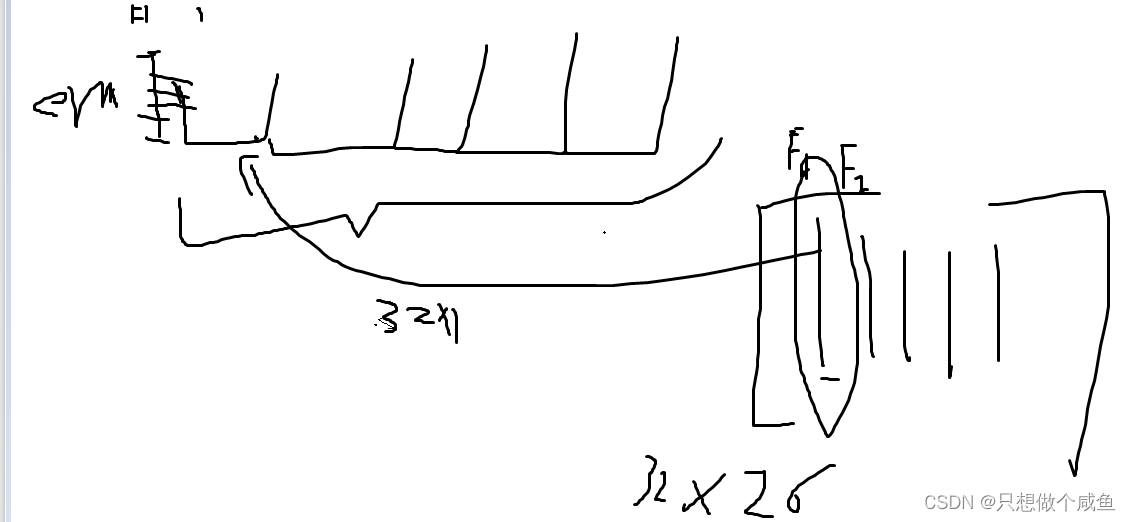
测试一下:
hidden_units = [256, 128, 64]
dnn_dropout = 0.
model = WideDeep(fea_cols, hidden_units, dnn_dropout)
summary(model, input_shape=(trn_x.shape[1],))
# 测试一下模型
for fea, label in iter(dl_train): #batch——size32
out = model(fea)
print(out)
break
训练模型
简单的核心:
# Wide
wide_out = self.linear(dense_input) #32*1
数值特征进线性层直接出
# Deep
deep_out = self.dnn_network(dnn_input) #32*64
deep_out = self.final_linear(deep_out) #32*1
数值+离散特征进DNN 再出
# out
outputs = F.sigmoid(0.5 * (wide_out + deep_out))
wide+deep 过分类函数,出概率值
总结:
Wide&Deep模型的提出不仅综合了“记忆能力”和“泛化能力”, 而且开启了不同网络结构融合的新思路。 所以后面就有各式各样的模型改进Wide部分或者Deep部分,















 2364
2364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









