







EMNLP20,AES里面为数不多的中顶会的文章。
contribution:
- 第一个在AES里面使用了BERT,同时提出了使用 regression 和 ranking 互补,来进行fine-tune,效果会比较好。可以当做目前为止,BERT在AES中的一个baseline.
- laboratory,大量的实验和比较,分析了当前各种AES的方法之间的优劣和对此的原因。
- 一个AES领域比较好的归纳,也可以当做是一篇review来看
novelty其实不大,主要是用了一个互补loss,基本思想就是觉得一开始fine-tune应该是ranking的占比比较大,但是由于一个batch ranking的supervision signal有限,后面会慢慢增加regression的占比,即dynamic的想法,其他都是常规。
introduction
首先,指出了当前BERT的使用之广,罗列了一些其他领域上fine-tune BERT的思路,认为在AES领域还没有fine-tune的先例;随后,讲了一下当前用neural做AES的范式:
- learning essay representation
- mapping function
- objective function
related
将当前AES的方法归为大致三类:
- prediction(classification / regression)
- recommendation(ranking)
- reinforce learning
- other (hand-crafted feature / statistic model)
具体对应的method这里不赘述
method
- BERT extractor
- FC
- Combination of Regression and Ranking(dynamic)
模型结构很简单,主要是objective function结合了两种loss,这里不过多赘述
experiment
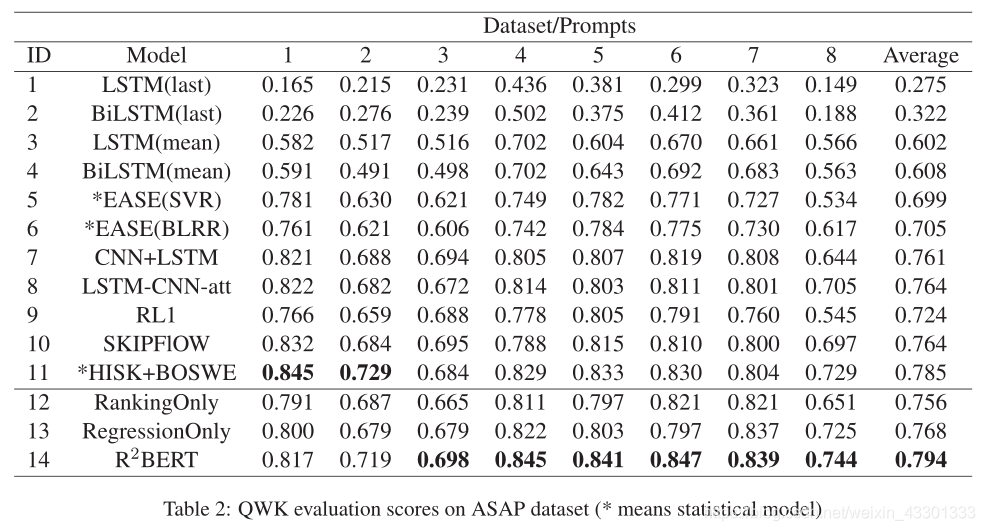
实验做的还是比较多的,概括一下主要的结论:
- bare 的neural model(LSTM/CNN)效果很差,BI-LSTM 和mean pooling之后的稍微好一点,很直接的原因就是essay太长出现的long term dependency,因此效果差于hand-crafted feature。
- hierarchy和ensemble model的性能是comparable的,弥补bare neural的一些缺陷(模型参数更多更复杂了)
- statistic model(HISK+BOSWE) outperform了许多neural的方法,同时在argumentative prompt上面效果最优(argument比较吃一些推理类型的key word,可能直接统计效果更好?回头去看看HISK+BOSWE)
- self-attention能够在narrative上面表现地十分优异,这也和self-attention的强上下文理解能力有关。
- ranking和regression呈现一定的互补性能
接下来还有可视化,发现attention能够集中于某些内容、主题相关的token(如下面的dog),这可能也是为何在narrative上面表现比较好的原因

future work
因为essay的长度原因,导致许多过长的essay没有办法把所有token喂给BERT,虽然实验中尝试取前和后,效果没有太多差异,但是这仍是一个用BERT做AES的比较好的方向,就是如何巧妙地解决长度限制,同时有更好的办法缓解long term dependency。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









