







项目中数据分析的需要自己从知乎某个专门的问题上爬数据,但众所周知,知乎的问题的显示方式有点胃疼(指滑动后下翻加载更多回答,还经常卡住),翻了翻网上的教程发现有的要么就是很老了要么就是付费的,本着开源共赢的原则,写一篇记录一下自己踩过的坑,也给后面人警醒。
阅读前必知:
- 本文的方法是2023年10月的,如果过了时间太久可能就不管用了,请注意时效性;
- 部分代码由GitHub Copliot完成,可能存在错误,但是结果应该没问题;
- 代码写的比较辣鸡勿喷,解决方案也有点繁琐,但能用的方法就是好方法~
看之前参考了知乎这篇文章
方法1 使用Web scraper
Web scraper是一个很好用的轻量级的0代码爬虫工具,只需要安装chrome插件就可以使用,在google商店搜就可以了,按F12打开是这样的:
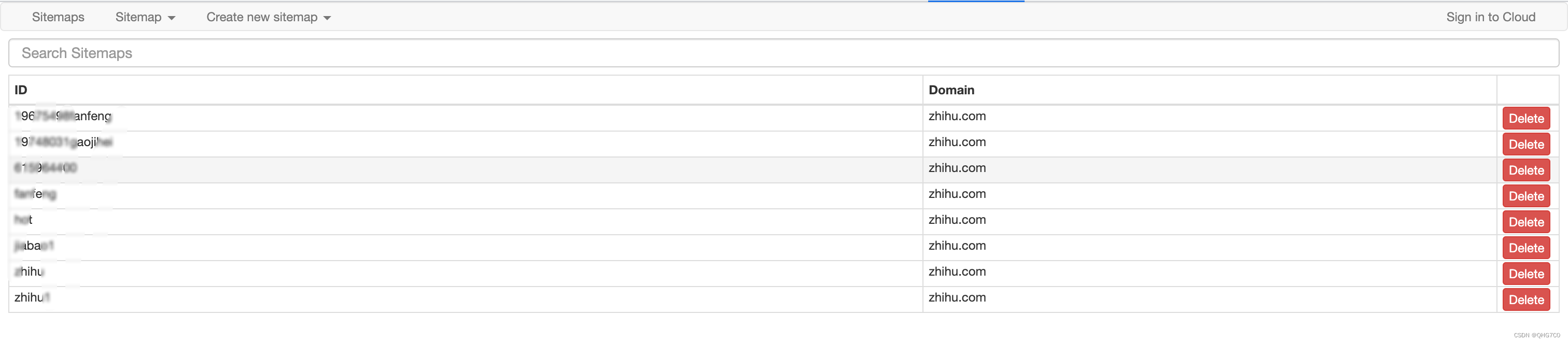
具体使用过程这里不再赘述,记得一定要先选块再选内容。这个的原理和selenium类似,模拟滚到顶端然后再收集,其实这个用来轻量级爬虫是很好的,但对我的任务来说(我的任务有2k多条回答),很容易滑不到顶端然后出现闪退的情况,这里附上我的sitemap,对回答较少的问题应该是可以使用的 :
{"_id":"name","startUrl":["https://www.zhihu.com/question/xxxxxxxxx/answers/updated"],"selectors":[{"id":"block","parentSelectors":["_root"],"type":"SelectorElementScroll","selector":"div.List-item:nth-of-type(n+2)","multiple":true,"delay":2000,"elementLimit":2100},{"id":"content","parentSelectors":["block"],"type":"SelectorText","selector":"span[itemprop='text']","multiple":true,"regex":""},{"id":"user","parentSelectors":["block"],"type":"SelectorLink","selector":".AuthorInfo-name a","multiple":true,"linkType":"linkFromHref"},{"id":"date","parentSelectors":["block"],"type":"SelectorText",
"selector":".ContentItem-time span",
"multiple":true,"regex":""}]}
id就是名字(你这个任务的名字),然后url里面记得替换你要爬的问题id。
方法2 使用selenium
跟上面的原理差不多,滚动到最下面然后抓取页面,但跟上面存在相同的滚动满且卡顿、且知乎缓存导致爬不全的问题,这里也不多说直接附上代码,对小任务应该也是没问题的:
def scrape1(question_id):
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
]
url = f'https://www.zhihu.com/question/{question_id}' # 替换question_id
# 创建一个Options对象,并设置headers
options = Options()
options.add_argument("user-agent=" + random.choice(user_agents))
# 传入cookie
cookies = json.load(open('cookie.json', 'r', encoding='utf-8'))
# options.add_argument("--headless")
# 创建WebDriver时传入options参数
driver = webdriver.Chrome(options=options)
driver.get(url)
driver.delete_all_cookies()
for cookie in cookies:
driver.add_cookie(cookie)
time.sleep(2)
driver.refresh()
time.sleep(5) # 等待页面加载完成
# items = []
# question = driver.find_element(By.CSS_SELECTOR, 'div[class="QuestionPage"] meta[itemprop="name"]').get_attribute(
# 'content')
# while True:
# # 滚动到页面底部
# print('scrolling to bottom')
# driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# time.sleep(random.randint(5, 8)) # 等待页面加载新内容的时间,根据实际情况进行调整
#
# # 如果找到了页面底部元素就停止加载
# try:
# driver.find_element(By.CSS_SELECTOR, 'button.Button.QuestionAnswers-answerButton')
# print('reached the end')
# break
# except:
# pass
#
html = driver.page_source
# 解析HTML
soup = BeautifulSoup(html, 'html.parser')
# 获取所有回答的标签
answers = soup.find_all('div', class_='List-item')
df = pd.DataFrame()
contents = []
answer_ids = []
driver.quit()
for answer in answers:
# 获取回答的文本内容
content = answer.find('div', class_='RichContent-inner').get_text()
contents.append(content)
df['answer_id'] = answer_ids
df['content'] = contents
df.to_csv(f'{question_id}.csv', index=False, encoding='utf-8')
这里cookie自己准备,要么不好跳过最开始的登录过程。
方法3 使用requests配合beautiful soap
这也是我最后成功的方法,最主要的是支持断点接着工作(不用拖到底直接使用)
这里还参考了这篇文章:
原代码的核心代码是这样的:
#网址模板
template = 'https://www.zhihu.com/api/v4/questions/432119474/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cbadge%5B*%5D.topics%3Bsettings.table_of_content.enabled%3B&offset={offset}&limit=5&sort_by=default&platform=desktop'
for page in range(1, 100):
#对第page页进行访问
url = template.format(offset=page)
resp = requests.get(url, headers=headers)
#解析定位第page页的数据
for info in resp.json()['data']:
author = info['author']
Id = info['id']
text = info['excerpt']
data = {'author': author,
'id': Id,
'text': text}
#存入csv
writer.writerow(data)
#降低爬虫对知乎的访问速度
time.sleep(1)
但我试了下根本不符合我的要求,问题如下:
- 目前知乎改版后,excerpt属性并不能得到完整的答案;
- 目前知乎不用offset进行翻页了,而改用cursor,cursor很难找到规律,但实际上可以使用每个回答的next的指针。
成功思路
我的思路很简单,首先修改上面的代码获取answer_id,然后根据answer_id去爬每个对应的完整 回答。
首先说下模版网页如何获取。
我们点开我们想要的回答,刷新下找这个包:
[外链图片转存中…(img-pkPZH5Pz-1698149682893)]
这个就是我们要用的请求网址,可以看到offset一直是0,说明不管用了。
解决方法是先用一个起始的url0找到next:
import requests
import pandas as pd
import time
template = 'https://www.zhihu.com/api/v4/questions/30644408/feeds?cursor=1c4cacd45e70f24bd620bad51c605d59&include=data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,reaction_instruction,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp;data[*].mark_infos[*].url;data[*].author.follower_count,vip_info,badge[*].topics;data[*].settings.table_of_content.enabled&limit=5&{offset}&order=default&platform=desktop&session_id=1698132896804376037'
df = pd.DataFrame()
# df有三列,answer_id和content以及创建日期
df['answer_id'] = []
df['content'] = []
df['created_time'] = []
answer_ids = []
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'}
cookies = {
# 填自己的z_0 cookie
}
# 第一条使用模版,后面的都是next来获取
url0 = template.format(offset=0)
resp0 = requests.get(url0, headers=headers,cookies=cookies)
for data in resp0.json()['data']:
answer_id = data['target']['id']
# 添加answer_id到df中
answer_ids.append(answer_id)
next = resp0.json()['paging']['next']
for page in range(1,400):# 这里自己估算一下,每页是5条数据
#对第page页进行访问
resp = requests.get(next, headers=headers,cookies=cookies)
print('正在爬取第' + str(page) + '页')
for data in resp.json()['data']:
answer_id = data['target']['id']
# 添加answer_id到df中
answer_ids.append(answer_id)
next = resp.json()['paging']['next']
time.sleep(3) # 这里是情况可快可慢
# 将answer_ids写入df
df['answer_id'] = answer_ids
df.to_csv('answer_id.csv', index=True)
这样就得到了我们需要的回答的answer_id。
第二步,根据answer_id爬内容:
from bs4 import BeautifulSoup
import pandas as pd
import random
contents = []
batch = 0
for answer_id in answer_ids:
print('正在爬取answer_id为{answer_id}的数据'.format(answer_id=answer_id))
url = 'https://www.zhihu.com/question/30644408/answer/{answer_id}'.format(answer_id=answer_id)
try:
resp = requests.get(url, headers=headers, cookies=cookies)
soup = BeautifulSoup(resp.text, 'html.parser')
# 查找content
content = soup.find('div', class_='RichContent-inner').text
contents.append(content)
print(content)
except Exception as e:
print(f'爬取answer_id为{answer_id}的数据时出现异常:{e}')
break
time.sleep(random.randint(1,4))
# 每爬取100个回答就保存一次数据,保存在不同的文件中
if len(contents) % 100 == 0:
new_data = {'answer_id': answer_ids[:len(contents)], 'content': contents}
new_df = pd.DataFrame(new_data)
new_df.to_csv(f'text_{batch}.csv', index=True)
batch += 1
# new_data = {'answer_id': answer_ids[:len(contents)], 'content': contents}
# new_df = new_df.append(pd.DataFrame(new_data))
# new_df.to_csv('text1.csv', index=True)
这里爬100条保存一次,免得前功尽弃。

















 1184
1184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









