







【论文笔记】:Tsinghua:Finding Skill Neurons in Pre-trained Transformer-based Language Models[EMNLP22]

本文贡献:
- 发现技能神经元(skill neurons)的存在,这是预训练Transformers中的特殊神经元,它们对特定的任务具有高度的预测能力,并开发了一种通过prompt tuning来找到它们的方法 .
- 通过实验证实,技能神经元确实编码了处理任务所需的技能。
- 证明了技能神经元是在预训练中产生的,而不是通过微调。
- 初步评估了解技能神经元的应用。
摘要
-
本文发现了对特定任务的prompt tuning之后的某些神经元对该任务有很高的预测性。通过发现确认了:
1.1 skill neurons对对应task至关重要
当相关的神经元受到干扰时,任务能力显著下降
1.2 skill neurons是对应特定任务的
类似的任务往往有相似的技能神经元分布。
并将其命名为skill neurons -
此外,证明了skill neurons很可能是在预训练过程中产生的,而并非是在微调时产生。
-
并探讨了skill neurons的应用:
3.1 加速Transformers的训练
通过网络剪枝和建立更好的可迁移性指标。
3.2 可能促进对Transformers的理解
1. Introduction介绍
预训练语言模型(PLMs)尤其是基于Transformers的预训练模型在nlp的不同任务中表现出色。
但是我们并不清楚模型的参数如何分配作用于下游任务。是否有特定的神经元去编码这些能力?这个研究有利于我们理解和调整模型能力。
prompt tuning:(准备好可训练的embeddings、冻结PLMs的参数,仅对soft prompts进行微调)的方法引起广泛关注并成为了有效的微调方法。
本文发现了,在对一项任务进行微调之后,基于Transformers的预训练模型的一些神经元对该任务具有很高的预测性。
 图1显示了RoBERTaBASE中一个特定神经元的激活分布(Liu et al.,2019b)。该神经元的激活可以高度预测SST-2的标签(Socher et a l.,2013),一个已建立的情绪分析数据集。当输入句子表达积极情绪时,该神经元soft prompts的激活往往比表达消极情绪时高。这表明这个神经元可以编码区分情感的技能。将其命名为
图1显示了RoBERTaBASE中一个特定神经元的激活分布(Liu et al.,2019b)。该神经元的激活可以高度预测SST-2的标签(Socher et a l.,2013),一个已建立的情绪分析数据集。当输入句子表达积极情绪时,该神经元soft prompts的激活往往比表达消极情绪时高。这表明这个神经元可以编码区分情感的技能。将其命名为skill neurons
2. Preliminary研究准备
介绍prompt tuning、对所研究的神经元的定义以及研究设计。
2.1 Prompt Tuning
prompt tuning或soft promoting是一个近期热门的预训练模型PLMs下游任务高效微调参数的方法。给PLM的输入序列预置了软提示来促使PLM以与预训练目标相同的方式解码任务中的预期标签。
即:Prompt的目标是将下游任务的目标转换为Pre_training任务,一般为MLM——Masked Language Modeling(还有NSP——next sentence prediction,但是很少)
Prompt tuning步骤:
- 构建模版(Template Construction):
通过人工定义、自动搜索、文本生成等方法,生成与给定橘子相关的一个含有<mask>标记的模版。
例如对于情感分析任务:
原输入:I like movies directed by Nolan.
把标记模版it was <mask>拼接到输入序列中:
I like movies directed by Nolan.it was <mask>
然后将其喂入模型,并得到<mask>预测的各个token的概率分布。
- 标签词映射(Label Word Verbalizer):
对于每个任务,都使用一个verbalizer function(标签词映射函数:因为我们只关心下游任务的标签,所以需要建立一个映射关系)来将特定的标签词(Pre training的预测词)映射到下游任务的标签上。每个软提示(soft prompt)都是一个虚拟的token,其本质上是可训练的embedding。 - 训练(Training)
根据verbalizer,获得下游任务预测标签的概率分布,采用交叉信息熵进行训练。(因为只对训练好的MLM head进行了微调,1. 避免了fine-tuning中的过拟合问题,2. 还拉近了下游任务和预训练的目标,降低语义差异)
2.2 Neurons in Transformers(神经元)
Transformer(Vaswani等人,2017)是最先进的NLP模型架构,PLMs主要都是基于它。预训练模型通常由多个Transformer层堆叠。而每个Transformer层由一个自注意力模块和一个前馈网络(FFN)组成。其中FFN承载2/3的参数,非常的重要,并且编码了丰富的信息,因此本文从FFN入手研究:
F
F
N
(
X
)
=
f
(
X
K
T
+
b
1
)
V
+
b
2
(
1
)
FFN(X)=f(XK^T+b_1)V+b_2(1)
FFN(X)=f(XKT+b1)V+b2(1)
X X X 是一个token的hidden embedding
f ( ⋅ ) f(·) f(⋅) 是激活函数
K 、 V K、V K、V 是可训练的参数
b 1 和 b 2 b~1~ 和 b~2~ b 1 和b 2 是偏置
为了简化,使:
a
=
f
(
x
K
T
+
b
1
)
∈
R
d
m
(
2
)
a = f(xK^T+b_1)\in\mathbb{R}^{d_m}(2)
a=f(xKT+b1)∈Rdm(2)
我们将a的第i个元素
a
i
a~i~
a i 作为
X
X
X上的第
i
i
i个神经元的激活。
代表了
K
i
和
V
i
K~i~和V~i~
K i 和V i 的重要性,所以我们定义
K
i
和
V
i
K~i~和V~i~
K i 和V i 是第
i
i
i个神经元的权重。
2.3 Investigation Setup
为了全面研究技能神经元:
- 本文选择了使用广泛的RoBERTabase模型;
- 并在三中类型的七项任务中进行实验
- Sentiment Analysis情感分析
- SST-2
- IMDB
- TweetEval(Tweet)
- Natural Language Inference自然语言推理
- MNLI
- QNLI
- Topic Classification主题分类
- AG News
- DBpedia
- Sentiment Analysis情感分析
3. Finding Skill Neurons 找技能神经元
设计简洁高效的实验找到skill neurons。
3.1 Binary Classification Task 二分类任务
基于Trasformer的预训练模型: M \mathcal{M} M
对于一个二分类的任务: T \mathcal{T} T
其数据集: D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x ∣ d ∣ , y ∣ D ∣ ) } D=\{(x_1,y_1),(x_2,y_2),...,(x_{|d|},y_{|D|})\} D={(x1,y1),(x2,y2),...,(x∣d∣,y∣D∣)},并将其分为 D t r a i n 、 D t r a i n 和 D t e s t D_{train}、D_{train}和D_{test} Dtrain、Dtrain和Dtest
每个样本 D i ( x i , y i ) D_i(x_i,y_i) Di(xi,yi):包括输入 x i x_i xi和 y i ∈ { 0 , 1 } y_i\in\{0,1\} yi∈{0,1}
M \mathcal{M} M中每个特定的神经元: N \mathcal{N} N
输入句子 x x x的一个token t t t的激活值: a ( N , t , x ) a(\mathcal{N}, t, x) a(N,t,x)
a = f ( x K T + b 1 ) ∈ R d m a = f(xK^T+b_1)\in\mathbb{R}^{d_m} a=f(xKT+b1)∈Rdm
对模型
M
\mathcal{M}
M使用训练集
D
t
r
a
i
n
D_{train}
Dtrain进行提示微调,得到soft prompts:
P
=
{
p
1
,
p
2
,
.
.
.
,
p
l
}
P=\{p_1, p_2,...,p_l\}
P={p1,p2,...,pl}.
则对于一个给定的soft prompt :
p
i
p_i
pi,可以计算得到神经元
N
\mathcal{N}
N 在
p
i
p_i
pi 上的基线激活值:
a
b
s
l
(
N
,
p
i
)
=
1
∣
D
t
r
a
i
n
∣
∑
x
i
,
y
i
∈
D
t
r
a
i
n
a
(
N
,
p
i
,
x
i
)
,
(
3
)
a_{bsl}(\mathcal{N},p_i)=\frac{1}{|D_{train}|}\sum_{x_i,y_i\in D_{train}}a(\mathcal{N}, p_i, x_i) , (3)
absl(N,pi)=∣Dtrain∣1xi,yi∈Dtrain∑a(N,pi,xi),(3)
直观的,当
a
(
N
,
p
i
,
x
)
>
a
b
s
l
(
N
,
p
i
)
a(\mathcal{N}, p_i, x)>a_{bsl}(\mathcal{N},p_i)
a(N,pi,x)>absl(N,pi) 时,神经元
N
\mathcal{N}
N 对于输入句子
x
x
x 预测为证标签1。由此可以推出开发集的预测精度(Acc)为:
A
c
c
(
N
,
p
i
)
=
∑
x
j
,
y
j
∈
D
d
e
v
1
[
1
[
a
(
N
,
p
i
,
x
j
)
>
a
b
s
l
(
N
,
p
i
)
]
=
y
j
]
∣
D
d
e
v
∣
,
(
4
)
Acc(\mathcal{N},p_i)=\frac{\sum_{x_j,y_j\in D_{dev}1_{[1_{[a(\mathcal{N}, p_i, x_j)>a_{bsl}(\mathcal{N},p_i)]}=y_j]}}}{|D_{dev}|},(4)
Acc(N,pi)=∣Ddev∣∑xj,yj∈Ddev1[1[a(N,pi,xj)>absl(N,pi)]=yj],(4)
其中
1
[
条件
]
∈
{
0
,
1
}
1_{[条件]}\in\{0,1\}
1[条件]∈{0,1}在条件成立时取值为1的指示函数。
以上是以往的工作情况,只考虑了标签与神经元激活之间的正相关关系,然而类似于大脑中的抑制性神经元也有助于某些功能,强烈的负相关表明技能可能编码在这个神经元里,所以本文将神经元
N
\mathcal{N}
N 在soft prompt token
p
i
p_i
pi 上的预测性定义为:
P
r
e
d
(
N
,
p
i
)
=
max
(
A
c
c
(
N
,
p
i
)
,
1
−
A
c
c
(
N
,
p
i
)
)
,
(
5
)
Pred(\mathcal{N},p_i)=\max(Acc(\mathcal{N},p_i),1-Acc(\mathcal{N},p_i)),(5)
Pred(N,pi)=max(Acc(N,pi),1−Acc(N,pi)),(5)
然后,将模型
M
\mathcal{M}
M 内的所有神经元按照预测能力进行降序排序,并将顶部的神经元作为实验中的技能神经元。
附录G讨论了为什么选择这种方式。
首先经过扰动进行选择:扰乱每个神经元实验,花销太大。
3.2 Multi-class Classification Task 多分类任务
多分类任务拆解成多个二分类任务使用3.1中的方法找出skill neurons(用的soft prompts是原始任务的,而不是子任务的)
多类分类任务的技能神经元由相等数量的子任务技能神经元组成。

MNLI验证集中两个神经元在样本提示上的激活分布。虚线表示两个神经元的基线激活。
4. Do Skill Neurons Encode Skills?
通过一系列实验探索skill neurons是否编码特定任务。
4.1 Skill Neurons Generally and StablyEmerge一般性稳定性
Generally:对2.3中提到的7个NLP任务使用3中提到的方法进行5次随机实验,并对比了他们的Acc和标准差:发现均存在可与prompt tuning对比的技能神经元

对于二分类:top-1技能神经元的预测性
对于多分类:通过训练仅以分解子任务的前1个神经元的激活为输入的线性回归模型来获得技能神经元的性能
Stability: 为了排除技能神经元的产生并不是随机结果,作者用
R
o
B
E
R
T
a
b
a
s
e
RoBERTa_{base}
RoBERTabase对SST-2任务进行了五次随机追踪(用不同的数据顺序和不同的prompt初始化),均找到高预测性的技能神经元,证实了随机神经元的稳定性。

- Max,Avg 是前人使用输入token的方式寻找激活值高的神经元。
- 这也表明了prompt对寻找skill神经元对重要性。
4.2 Skill Neurons are Crucial for HandlingTasks处理任务至关重要
如果技能神经元编码了技能,那么它对任务很重要。
因此论文作者进行五次随机试验对比了对特定技能神经元添加高斯扰动和随机对神经元进行高斯扰动:
(这个是对TWEET任务技能神经元添加扰动的结果,其余可以在附录D看到)

我们发现TWEET任务Acc降的比随机更多,也比一些其他任务掉的多。
同时发现SST-2和IMDB掉的也挺多,甚至比TWEET多。应该是同类型任务。(作者在下一节也提到了,编码特定任务,所以相似任务的会相似)
4.3 Skill Neurons are Task-specific特定任务的
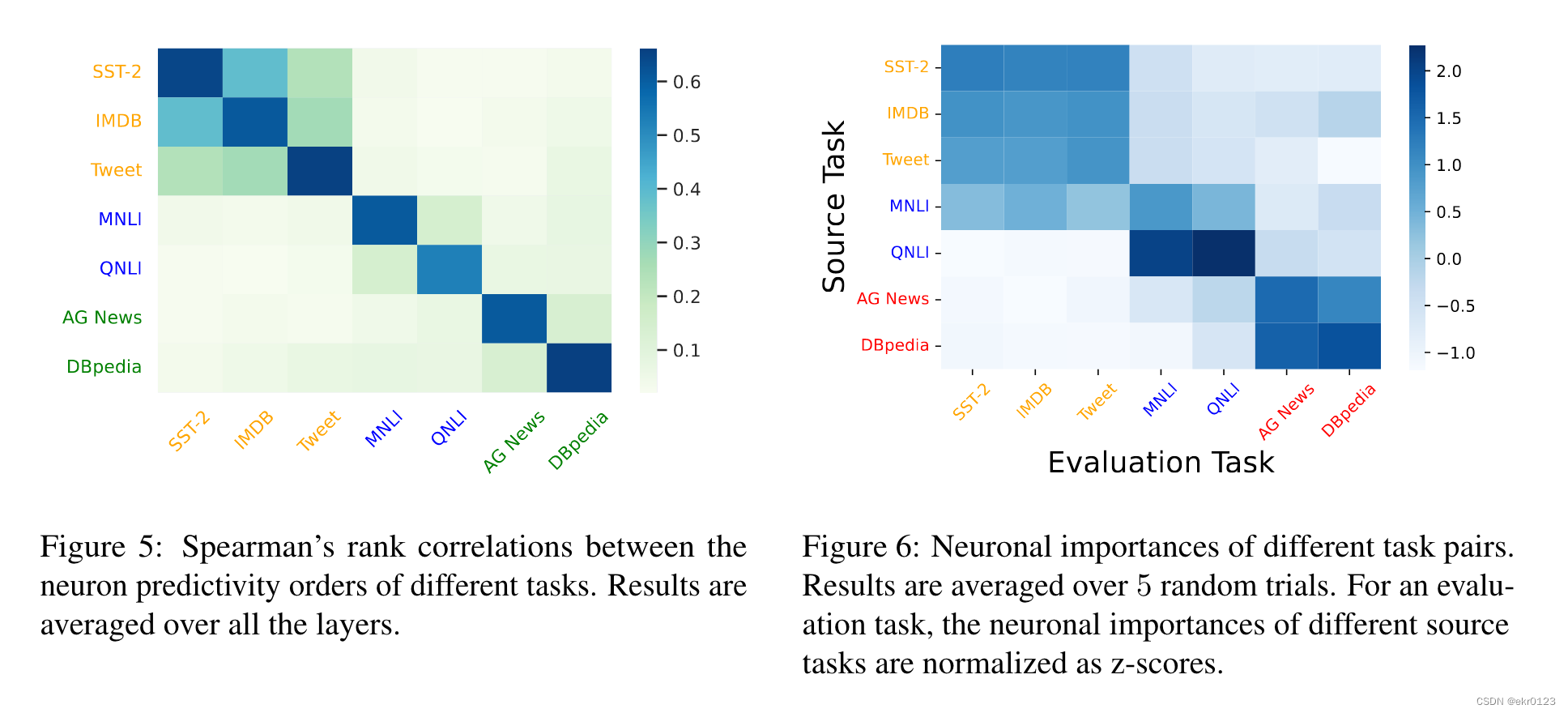
这节证明了技能神经元编码特定任务的高级技能而非任务一般的低级技能,如识别词性等。(评估了斯皮尔曼相似度,也有力支撑了上一节的实验)
4.4 Skill Neurons are not from WordSelectivity并非来自单词选择性
前人工作提出Transformers的神经元可能被某些词或者概念选择性激活。
本文对技能神经元的相关单词进行了研究:
- 包括输入嵌入和神经元权重向量之间有上下余弦相似度的单词
- 以及具有上下平均激活的单词

我们可以看出这些单词并没有传达情感(情感分类任务)。这表明不是来自关键词选择性。
此外,考虑到prompt tuning方法通过解码标签标记进行预测,需要检查技能神经元是否依赖于所使用的标签词。 如果是这样,则表明技能神经元不编码处理任务的技能,而是编码选择性解码某些单词的技能。 但是通过发现如果使用不同的随机词作为标签词,神经元所达到的预测阶数是相当一致的。 具体来说,对于所有任务,5个随机标签词的神经元预测阶数之间的平均 Spearman 相关性为 0.87。从而排除了这种可能性,
5. Where do Skill Neurons Come from?技能神经元来源
首先试图找到具有tuning-free prompts的技能神经元,包括随机提示和人工编写的硬提示。如表3所示。我们可以看到,即使没有进行调整,我们仍然可以找到具有非平凡预测性的神经元。Malach等人(2020)表明,随机初始化的神经网络可能具有预测子网络。因此,还使用random prompts与随机初始化的模型进行比较。观察到,虽然随机模型中的神经元在一定程度上具有预测性,但其预测性远低于预训练模型中的神经。这些结果表明,技能神经元是在预训练中产生的,而prompt tuning是找到它的有效工具。
 为了进一步证明:使用了别的微调方式进行了验证(adapter-based tuning和BitFit)这些方式也固定预训练参数不变。
为了进一步证明:使用了别的微调方式进行了验证(adapter-based tuning和BitFit)这些方式也固定预训练参数不变。
也进行了干扰技能神经元的实验,结果与之前实验类似。技能神经元也表现出了对特定任务的重要性。所以更加证实了技能神经元是在预训练过程中产生的。
6. Application 应用
初步探讨了skill neurons的应用。
6.1 Network Pruning 网路剪枝
网络剪枝(减少存储消耗,删去冗余参数)
作者尝试了保留前2%的技能神经元,冻结98%的神经元为基线激活。对
R
o
B
E
R
T
a
b
a
s
e
RoBERTa_{base}
RoBERTabase模型对上九层进行这种策略,将参数降低为
2
3
\frac23
32. 并取得了不错的Acc表现(具体看下表)。速度提升了近1.4倍。

6.2 Transferability Indicator 可转移性指标
先前的工作探索了跨任务提示调整进行微调,也有前人提出了激活神经元在软提示之间的重叠率(ON)作为提示传递性指标,与零样本提示传递性具有良好的相关性。但是他们将所有的ON纳入计算,这会带来没有特定技能的冗余神经元的噪声干扰。
作者将目标任务的前20%的skill neurons纳入计算。这一改进将之前的他们任务的平均斯皮尔曼相关性从0.53提升到了0.71。
Limitations 局限
- 这些实验全是基于 R o B E R T a b a s e RoBERTa_{base} RoBERTabase,其他基于Transformers的PLMs尚不清楚是否也普遍存在技能神经元,这些需要实验验证。
- 实验中,所用到的数据集都是英文数据集,因为资源丰富。尽管作者认为skill neurons并不依赖于英语,但是也需要进行实验验证。
- 这些工作都是基于前人的研究,都是在FNN层中进行的,需要进一步探索其他参数。















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









