







Spark SQL入门
spark sql 基本原理
sparksql 概述与架构
sparksql是spark在处理结构化数据的解决方法方案。
sparksql是一个分布式的sql查询引擎语言。
sparksql由 catalyst优化,==sparksql内核 ,hive支持 组成
catalyst优化
优化处理查询语句整个过程的 ,对sql的解析,优化
sparksql内核
对要处理的数据进行获取和输入,执行查询。把执行的结果输出为Dataframe格式。
hive支持
支持对hive数据的处理
sparksql执行流程
1:对sql语句进行sql解析器,生成 Unresolved 逻辑计划
2: Unresolved 逻辑计划经过 catalyst分析器,生成Analyzed 逻辑计划,Schema Catalog 则要提取 schema 信息。
3:Analyzed 逻辑计划经过 catalyst优化,生成Optimized 逻辑计划
4:Optimized 逻辑计划 通过 spark planner生成 物理计划,调用next,生成可执行的物理计划。
5: toDf生成 Dataframe。
sparksql 相对于 hive 和 MapReduce 作业的优点
- 支持多种语言进行开发如java,scala,python等 。。。
- 兼容的数据格式多,hive表,json等。。。
- 方便扩展,它解析器和优化器可以重新定义
- 性能优化,采用内存列式存储 ,动态字节码生成,内存缓存数据等
sparksql基本操作命令
数据准备

导入SparkSession包

通过SparkSession的builder的getOrCreate来创建SparkSession对象。

隐式装换,将RDD==>DataFrame

读取json数据
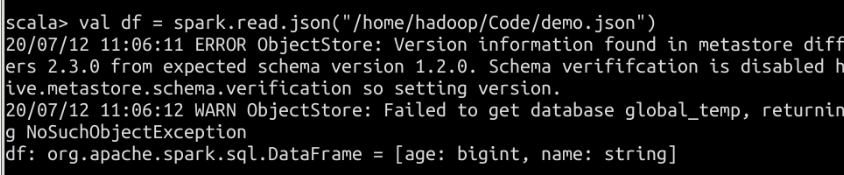
查看结果:
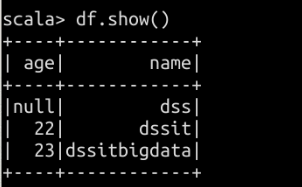
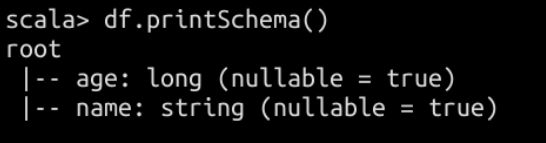
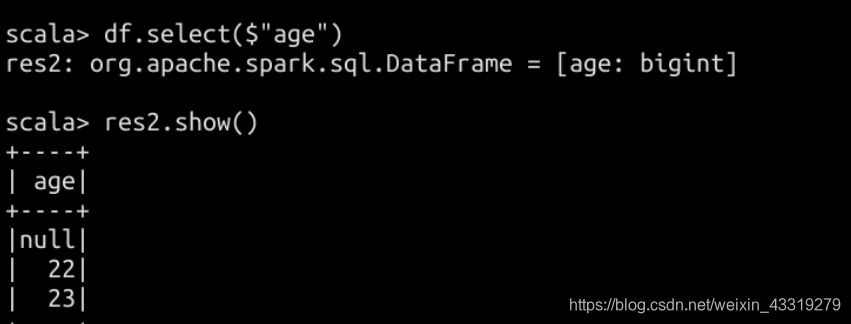
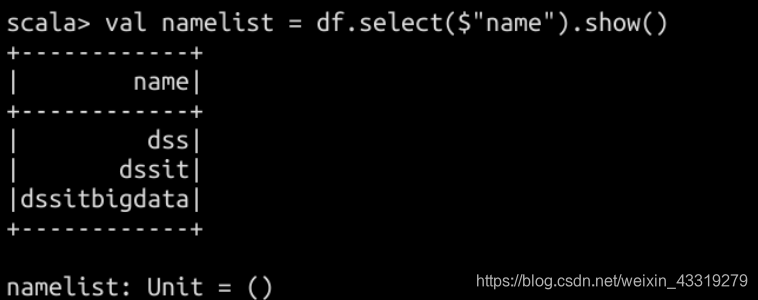
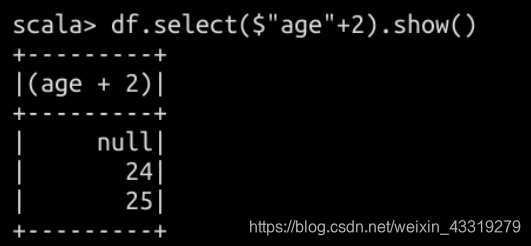
注册为临时view

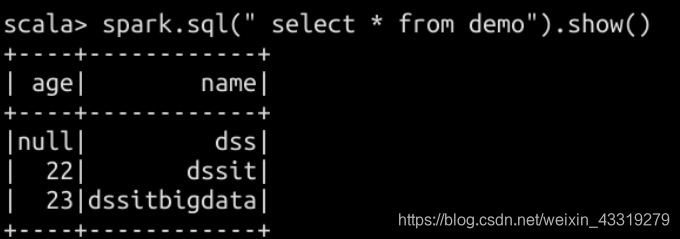
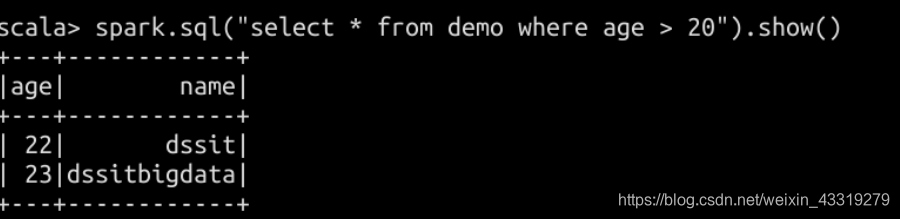
DataFrame 和Dataset 两种的使用
DataFrame:以指定的列组成的分布式数据的集合,相当于关系型数据库中的表,支持多种数据源的构建。
RDD与DataFrame数据结构的区别:

DataFrame 操作分为 Action,基础 DataFrame 函数,集成语言查询,Output 操作,RDD 操作等。
Action
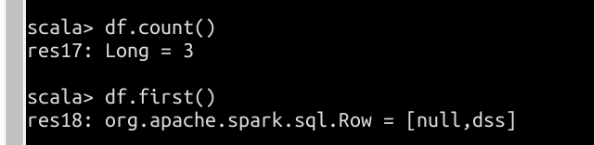
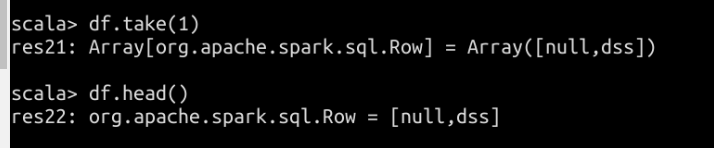
collect、count、first、head、take
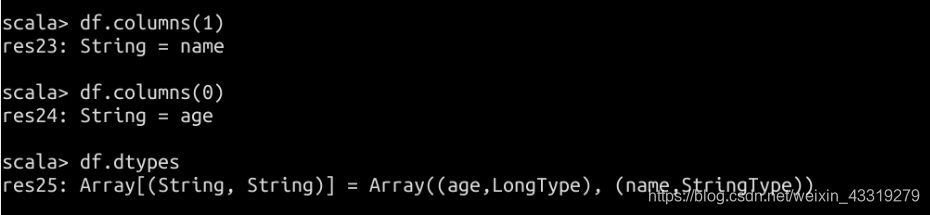
DataFrame 基础函数
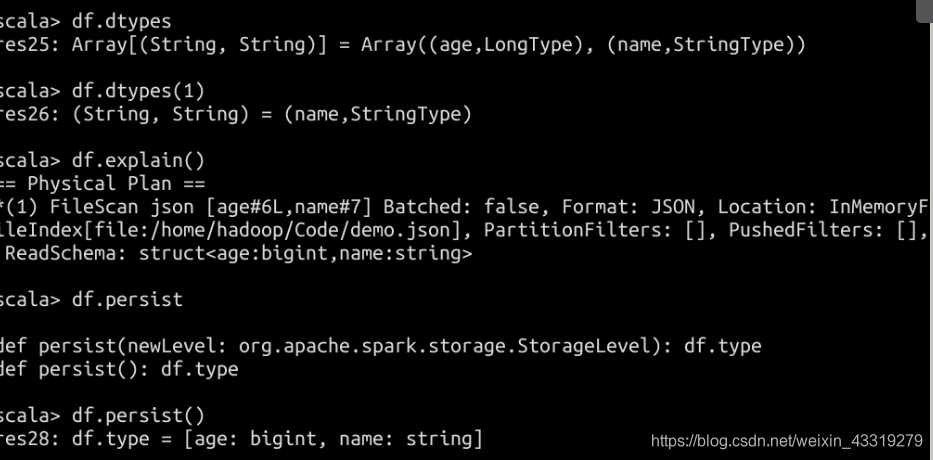
spark数据持久化
默认不指定的话就是StorageLevel (内存) ,当内存不足的时候可以选择内存和磁盘
最优是内存 ,避免磁盘io带来的性能消耗。
DataSet
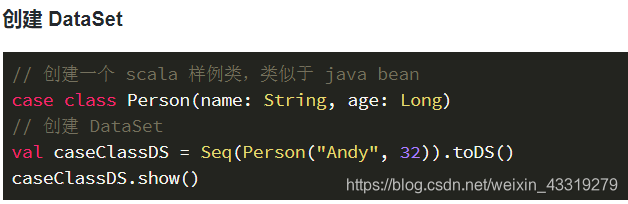


集成语言查询
sort
filter
intersect
limit
RDD转DataFrame的方式
两种方式
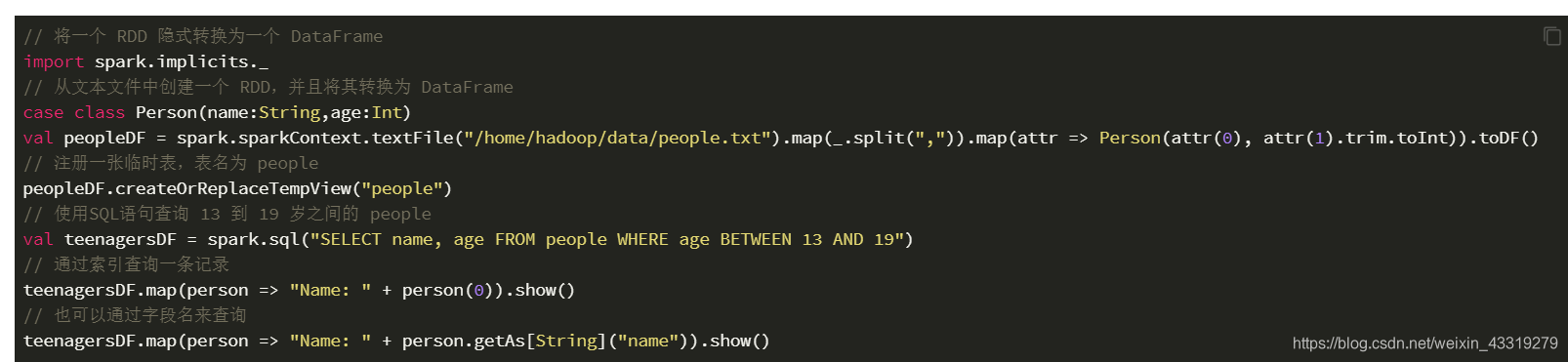
1:如果提前知道sparkApplication的schema的话可以使用隐式装换
如上面所示
import spark.implicits._
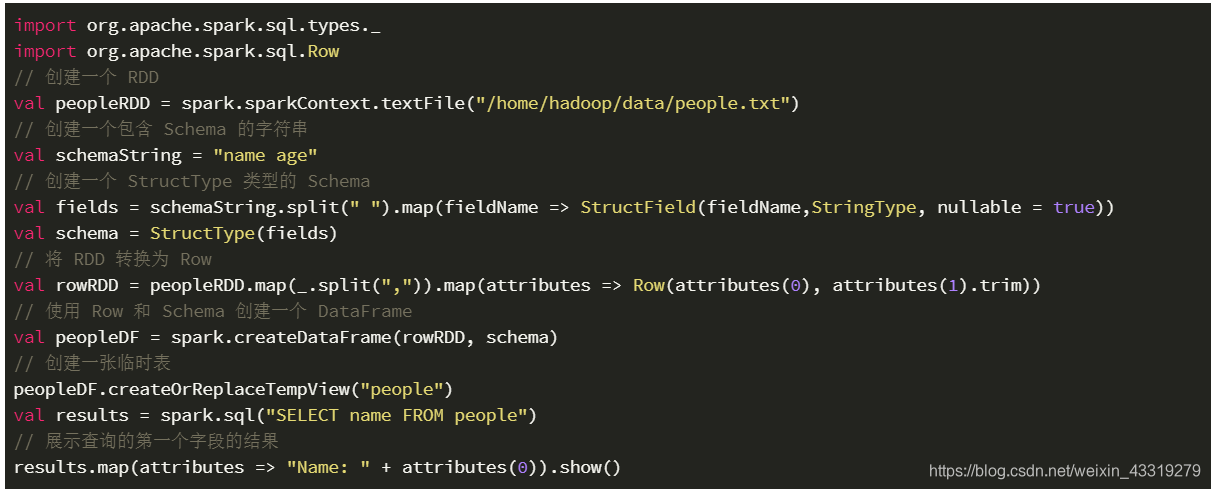
2:通过一个编程接口,允许构建一个 Schema,然后应用到现有的 RDD

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









