







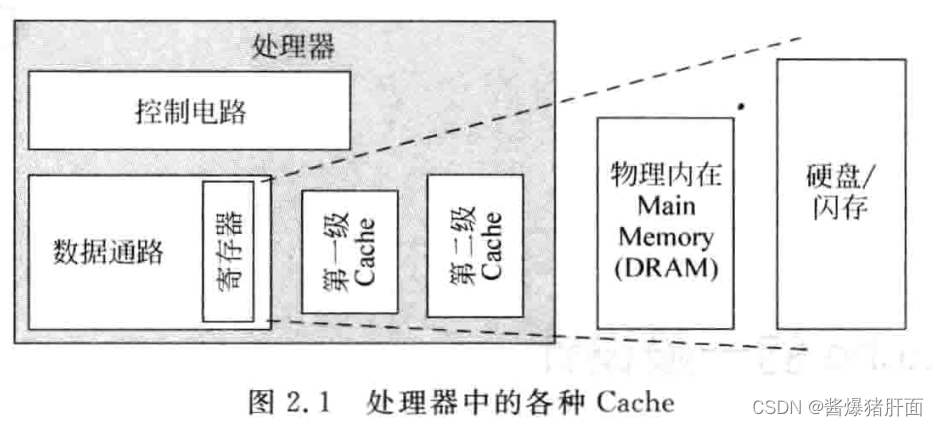
现代的通用处理器从实现方式上看,可以分为标量(Scalar)和超标量(Superscalar)这两种。其中,标量处理器每周期最多只能执行一条指令,顺序执行(in-order);而超标量处理器每周期内执行多条指令,可以顺序执行也可以乱序执行(out-of-order)。相比于标量处理器而言,超标量处理器提高了程序执行效率,但也增加了处理器及其流水线的设计复杂度。
《超标量处理器设计》一书以Superscalar RISC处理器设计作为重点,同时以其流水线作为贯穿的主线,按流水线阶段、部件分章节展开介绍。

系列文章目录
【读书笔记】《超标量处理器设计》开篇:我的动机杂谈
【读书笔记】《超标量处理器设计》第1章 超标量处理器概览
【读书笔记】《超标量处理器设计》第2章 Cache
文章目录
| 思考问题 |
|---|
| 1. 为什么需要Cache?不用Cache会有什么问题? |
| 2. Cache到底是什么?(广义狭义说法辨析) |
| 3. Cache的基本组成方式有哪些? |
| 4. Cache工作时会遇到哪些问题?如何解决? |
| 5. 提升Cache性能的方法包括哪些? |
1 Cache的一般设计
问题现象:大容量存储访问速度远低于处理器速度。
Cache的动机
- 时间相关性(Temporal Locality):如果一个数据被访问了,那么在以后很有可能还会被访问
- 空间相关性(Spatial Locality):如果一个数据现在被访问了,那么它周围的数据在以后可能也会被访问
Cache说法辨析
-
广义Cache,上级存储是下级存储的“Cache”
-
狭义Cache,特指紧密耦合在处理器中的L1Cache、L2 Cache
-
Cache的组成
- Data部分:保存一片连续地址的数据
- Tag部分:存储着这片连续数据的公共地址
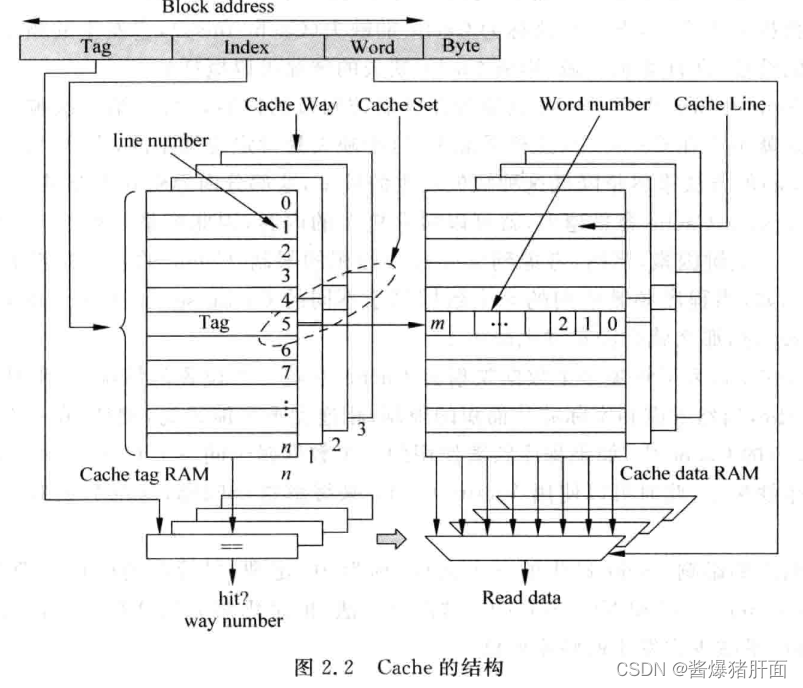
| 概念 | 解释 |
|---|---|
| Cache Line | 一个Tag和它对应的所有数据组成的一行 |
| 数据块Cache data block (也叫Cache block或Data block) | Cache line中的数据部分 |
| Cache set | 若一个数据可存储在Cache多个地方,则被同一个地址找到的多个Cache line |
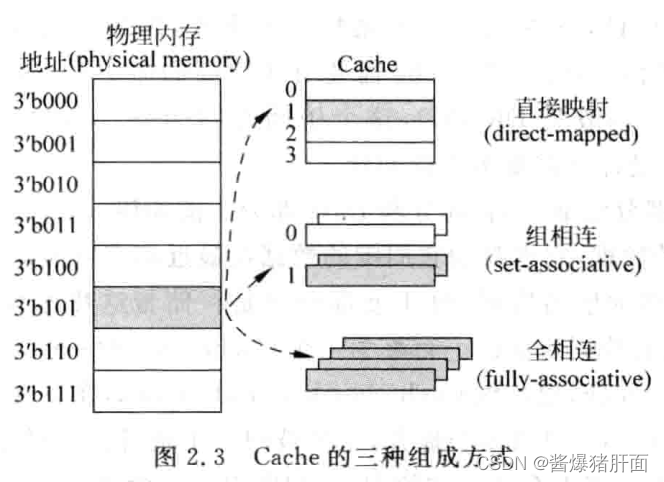
| Cache实现方式 | 说明 |
|---|---|
| 直接映射(direct-map)Cache | 对于物理内存中的一个数据,Cache中只有一个地方可以容纳它 |
| 组相连(set-associative)Cache | 对于物理内存中的一个数据,Cache中有很多地方都可以放置这个数据 |
| 全相连(fully-associative)Cache | 对于物理内存中的一个数据,Cache中任何地方都可以放置这个数据 |
三种组织方式的差异:
| Aside: Cache缺失(Cache miss) |
|---|
| 要找的数据或者指令并不在Cache中 |
| 3C定理 Cache缺失(Cache miss)的三个条件 | 说明 |
|---|---|
| Compulsory | 第一次被访问指令或数据肯定不会在Cache中 |
| Capacity | Cache容量有限,装不下更多指令或数据 |
| Conflict | 多个数据映射到Cache中同一个位置 |
1.1 Cache的组成方式
-
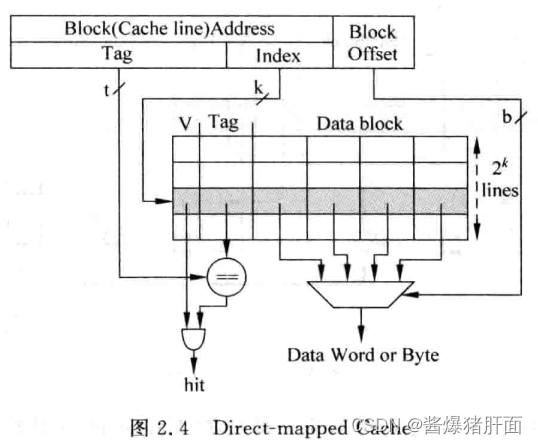
直接映射(Direct-mapped)
-
访问地址划分说明
Tag Index Block Offset 用于判断Index所找Cache line是否有效 用于找到 1个Cache line用于定位Cache line中字节以找到真正数据 注:Cache line中还会有个有效位V,判断是否存着有效的数据
-
存在问题:Index相同的地址会寻址到同一个Cache line交替访问,即产生冲突
-
优点:简单,不需要替换算法
-
缺点:执行效率低,现代处理器很少使用此方法
-
-
组相联(Set-associative)
-
动机:解决直接映射Cache一个数据只能放在一个Cache line中而产生冲突的问题
-
要点:一个Index可以找到多个Cache line
Aside: n路组相联(n-way set-associative Cache) 对于一个组相联结构的Cache来说,一个数据可以放在n个位置 -
2-way组相联Cache示意图
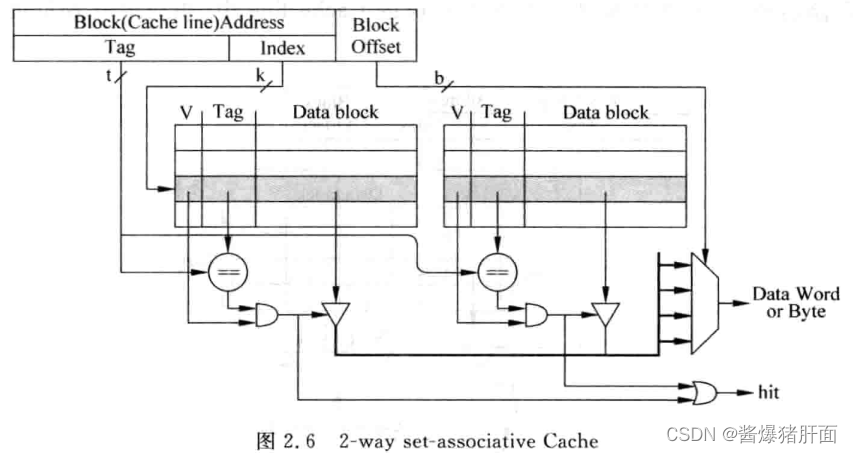
-
地址划分
Tag Index Block Offset 用于判断Index所找Cache line中哪个有效 用于找到 多个Cache line(即一个Cache set)用于定位Cache line中字节以找到真正数据 -
优点:显著减少Cache缺失率
-
缺点:延迟更大,或引入流水线
-
实现:Tag和Data分开放置,称为Tag SRAM和Data SRAM
按访问Tag SRAM和Data SRAM的顺序方式分并行访问与串行访问
-
并行访问
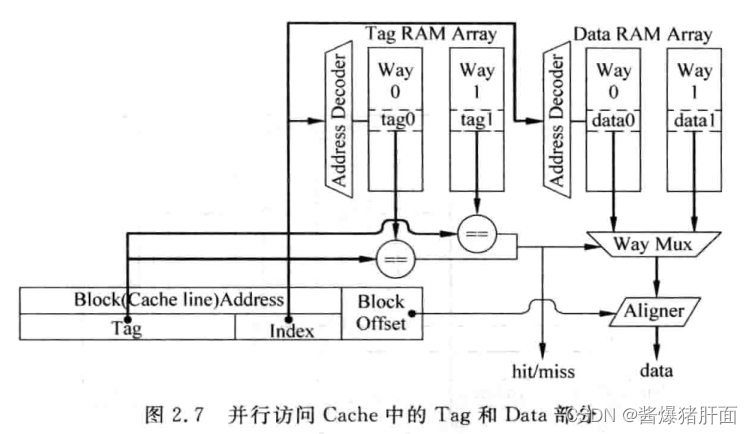
-
流程概述
- Tag被读取的同时,地址在Data部分也被读取
- 接着送多路选择器,根据Tag比较选对应Data block
- 根据Block Offset选出合适的字节
Aside: 数据对齐(Data Alignment) 根据Block Offset选择字节 -
存在问题:若一个周期内完成访问过程,则会占据很大延迟
-
需求:使处理器运行在比较高的频率下
-
解决:在Cache访问中引入流水线
-
利弊权衡:
- 对于I-Cache,使用流水线不会有影响
- 对于D-Cache,使用流水线会增大load指令的延迟
-
并行访问流水线示意图
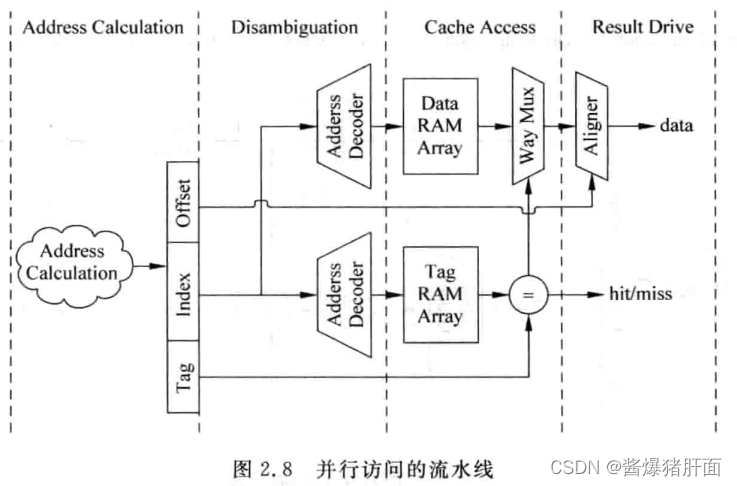
阶段 说明 Address Calculation 计算得出存储器的地址 Disambiguation 对load/store指令之间存在的相关性进行检查 Cache Access 直接并行访问Tag SRAM和Data SRAM,使用Tag比较结果进行选择 Result Drive 使用存储器地址中的block offset值,从数据部分给出的data block中选出最终需要的数据(字节或者字) -
优点:将整个Cache的访问放到几个周期内完成,降低处理器的周期时间
-
-
串行访问
- 流程概述:
- 先访问Tag SRAM
- 根据Tag比较结果知道哪一路数据需要被访问
- 访问指定SRAM,其他SRAM使能信号置无效
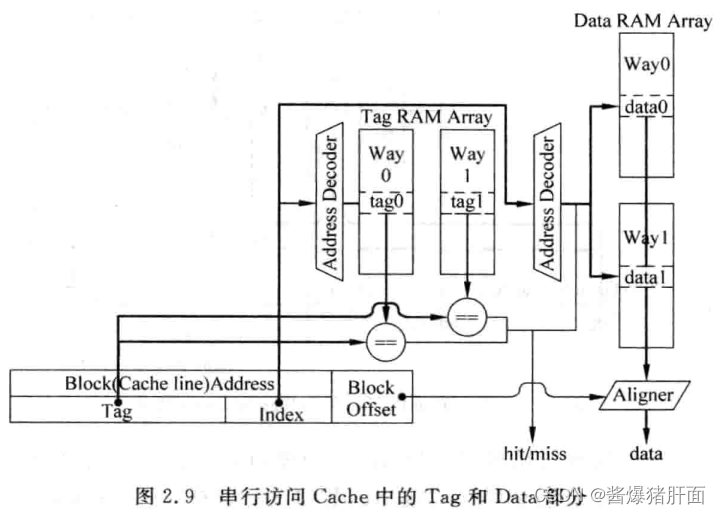
- 流程概述:
-
存在问题:完全串行了Tag SRAM和Data SRAM的访问,延迟更大,需要流水线
- 优点:由于不需要多路选择,降低处理器周期时间
- 缺点:Cache访问增加了一个周期,即增大load指令延迟
-
并行访问 v.s. 串行访问
并行访问有较低时钟频率和较大功耗,访问Cache时间缩短一个周期
- 乱序执行超标量处理器:可乱序指令调度,增加一个周期影响不大,最好采用串行访问
- 普通顺序执行处理器:无法乱序指令调度,增加一个周期引起处理器性能降低,最好采用并行访问
-
-
全相连(Fully-associative)
- 区别:不再有Index,数据可存Cache任何Cache line
比组相连更“激进”的情况、更灵活。前者一个数据只能映射到Cache上“一组”Cache line;而后者可映射到Cache上全部的Cache line
- 说明:存储器地址得和所有Cache line的Tag比较从而从中找到匹配项
- 实现:使用内容寻址的寄存器(Content Address Memory,CAM)存Tag;用SRAM存数据
- 优点:缺失率最低
- 缺点:延迟最大
- 评析:这种结构不会有很大容量,例如TLB即以这种方式实现
- 区别:不再有Index,数据可存Cache任何Cache line
1.2 Cache的写入
| Aside:哈佛结构 |
|---|
哈佛结构是一种计算机内存存储组织方式,其特点是指令存储器(Instruction Memory)和数据存储器(Data Memory)分开,分别独立编址。与哈佛结构相对的是冯·诺伊曼结构(Von Neumann Architecture),在冯·诺伊曼结构中,指令和数据存储在同一存储设备中,共享地址空间。 |
-
写I-Cache
- I-Cache一般不可直接写入(即便有自修改self-modifying)
- 实现:借助D-Cache
- 将要写的内容先写入D-Cache
- D-Cache再写下级存储(例如L2 Cache)
- I-Cache内容置为无效
- 再执行时则用已被修改过的指令
-
写D-Cache
- 场景问题:不同于读,写D-Cache会存在不一致问题
- 简单解决:写D-Cache的同时,也写到其下级存储,即
写通(Write Through) - 存在问题:D-Cache下级存储访问时间长,而store出现频率又高,最终拖累处理器执行效率
- 进阶解决:数据写D-Cache的Cache line时先做记号(dirty),等之后需要被替换时再写下级存储,即
写回(Write Back) - 优点:减少些慢速存储器的频率
- 缺点:给存储器的一致性管理造成负担
Aside: 不一致(non-consistent) 当执行一条store指令时,如果只是向D-Cache中写入数据,而并不改变它的下级存储器中的数据,这样就会导致D-Cache和夏季存储其中,对于这一个地址有不同的数据。即不一致 - 存在问题:上述都是假定写D-Cache的地址D-Cache中的;若地址并不在D-Cache中则产生写缺失(write miss)
- 初步解决:将数据直接写到下级存储,即Non-Write Allocate
- 其他解决:将下级存储缺失对应数据块(data block)取出,将写入数据合并,再整体写入D-Cache,即Write Allocate
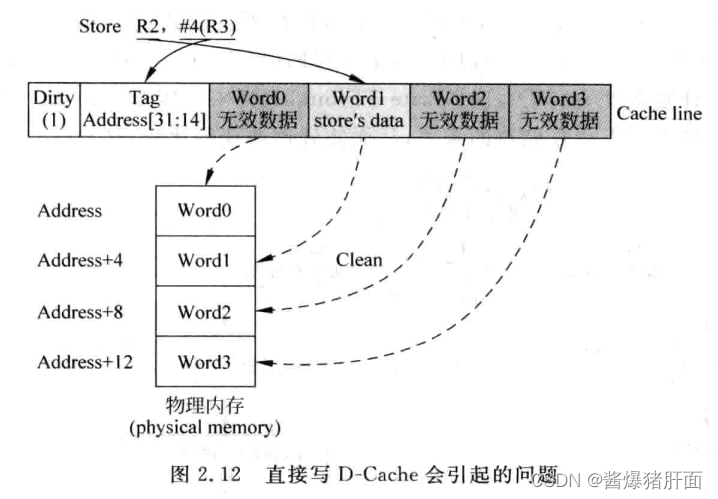
- 思考问题:D-Cache缺失时为何不能直接从D-Cache中找一个line写入?
- 写往往是一个字,而D-Cache管理是以Cache line为粒度管理
- 若将这个字写入一个Cache line,则此Cache line其他位置和下级存储不一致
- 若再接着将Cache line写回下级存储,则导致下级存储中原本正确的数据被篡改
1.3 Cache的替换策略
-
场景动机:D-Cache读写缺失,且CacheSet内所有line都被占用,则需要踢一个替换
-
最近最少使用法(Least Recently Used,LRU)
- 概述:有限选择最近被使用次数最少的Cache line
- 流程:
- 每个Cache line记录年龄(age),每当被访问一次则增加其年龄
- 进行替换时,先换年龄最小的
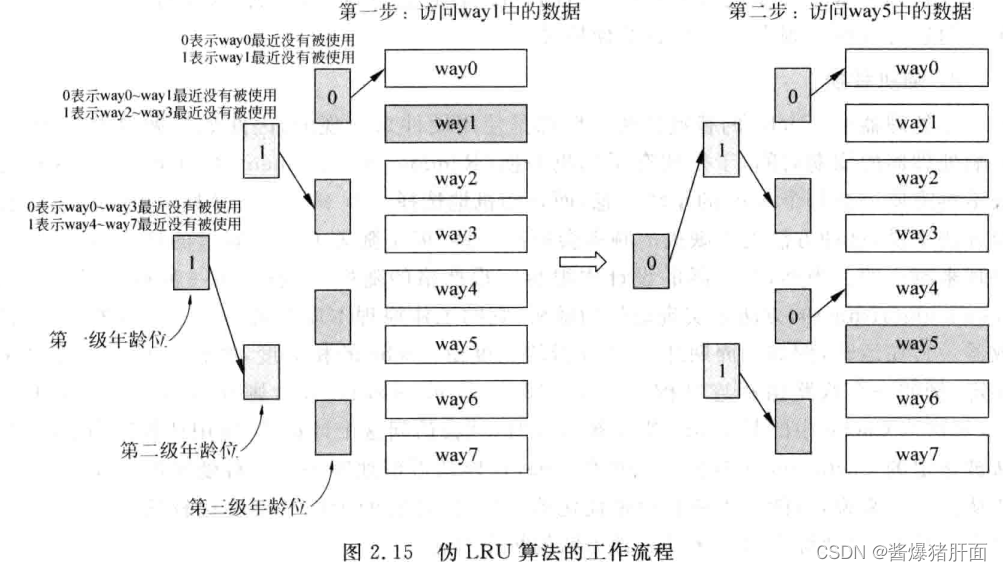
- 存在问题:随着Cache相关度增加(即way个数增加),精确实施LRU困难
- 实际实施:伪LRU方法
- 所有way分组,每组一个1位年龄部分
- 即年龄位表示“一组”way的最近被使用情况(而不是“一个”way的情况)
-
随机替换
- 动机:Cache替换算法一般由硬件实现,若太复杂则影响周期时间
- 概述:随机选一个way进行替换
- 优点:硬件复杂度低,不会损失过多性能
- 缺点:缺失率更高
- 实现:实际很难严格随机,一般用始终算法(clock algorithm)实现近似随机
本质是一个计数器,每周期加1
2 提高Cache的性能
- 基本方法:写缓存,流水线,多级结构,victim cache,预取
乱序执行超标量处理器特有方法:非阻塞,关键字优先,提前开始
2.1 写缓存
-
场景:D-Cache缺失,需要从下级存储读数据
-
存在问题:L2 Cache或Mem一般只有一个接口串行完成,访问时间过长
-
解决:写缓存(Write Buffer)
- 写回(Write Back):Dirty的Cache Line首先放入写缓存,等到下级存储空闲再写
- 写通(Write Through):每当数据写D-Cache的同时,并不会同时写下级存储,而是将其放到写缓存中。
-
问题:增加复杂度,缺失时不仅要查下级存储还要查缓冲区
-
小结:相当于L1 Cache到下级存储器之间的一个缓冲
对Write Throught尤其重要
2.2 流水线
- 场景
- 读D-Cache:同时读取Tag SRAM和Data SRAM。处理器周期时间要求不严,可一个周期内完成
- 写D-Cache:只能串行,难以一个周期内完成
- 经典解决(流水线划分):
- Tag SRAM的读取和比较放一个周期
- Data SRAM放在下一个周期
- 分析
- 对于一条store指令而言,即使D-Cache命中也需要两个周期完成
- 但整体看,连续store仍可获得每周期执行一条store指令的效果
| Trick |
|---|
| 1. 读DCache,load的数据可能正好在store的流水线寄存器中(Relayed Store Data) 2. 则比较load所携带地址和sotre的流水线寄存器:Delayed Store Addr寄存器。若匹配则不用从Data SRAM再拿 |
- 引发问题:过深的流水线导致高硬件复杂度
2.3 多级结构
-
场景动机:实际现实中没有一个既容量大又速度快的存储器
-
需求目标:“看起来”使用了一个容量大且速度快的存储
-
解决:多级结构
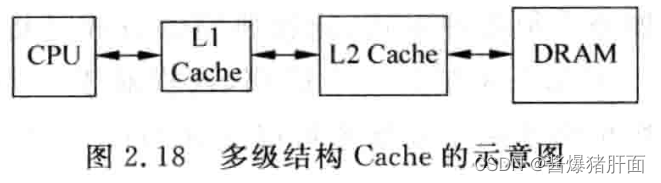
L2一般write back;L1 write through也可接收
-
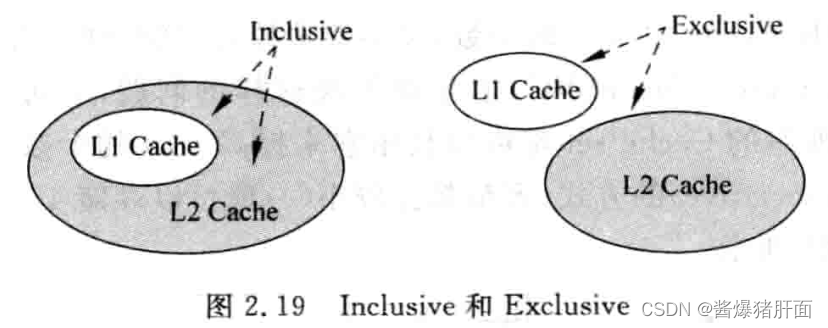
概念辨析:Inclusive和Exclusive
- inclusive:L2 Cache包含了L1 Cache中所有内容,则称L2 Cache是Inclusive的
- 优点:避免干扰流水线;简化一致性管理
- 缺点:浪费硬件资源(一份数据存两个地方)
- exclusive:L2 Cache和L1 Cache的内容互不相同,则称L2 Cache是Exclusive的
- 优点:避免硬件资源浪费
- 缺点:干扰流水线(需要检查所有的Cache)
- inclusive:L2 Cache包含了L1 Cache中所有内容,则称L2 Cache是Inclusive的
2.4 Victim Cache
- 动机:被踢出的数据可能马上又要使用
- 举例说明:2-way场景,三个数据映射到同Cache set
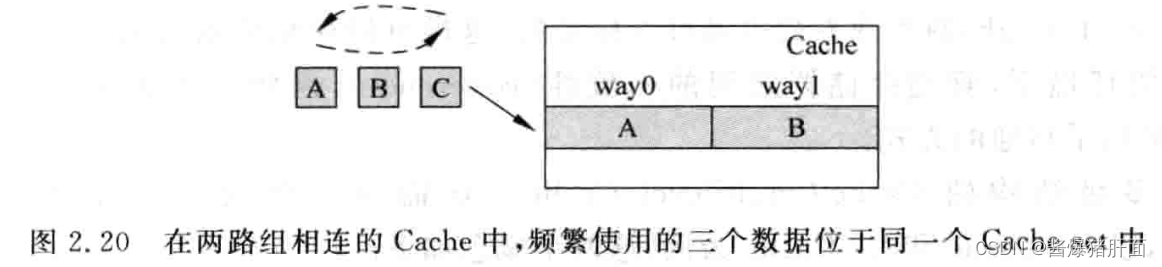
- 解决:Victim cache(保存最近被踢出的Cache数据)
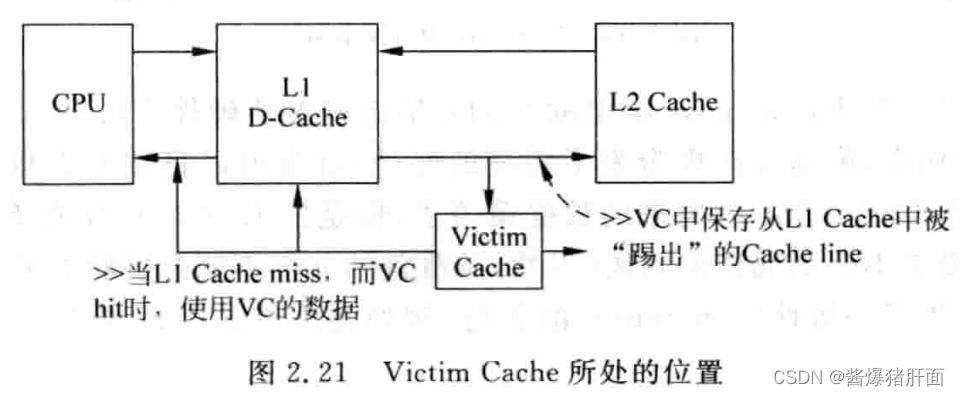
- 全相连、容量小
- 和Cache互斥(即Cache换下来给VC;VC再命中给Cache)
- 处理器可同时读VC和Cache,命中效果相同
- 洞见解析:Victim Cache本质相当于增加Cache中way数,避免多个数据竞争Cache中有限位置,从而降低Cache的缺失率
| Aside: Filter Cache |
|---|
| 一种类似Victim Cache的设计思路,只不过Filter Cache用在Cache之前;而Victim Cache用在Cache之后 |
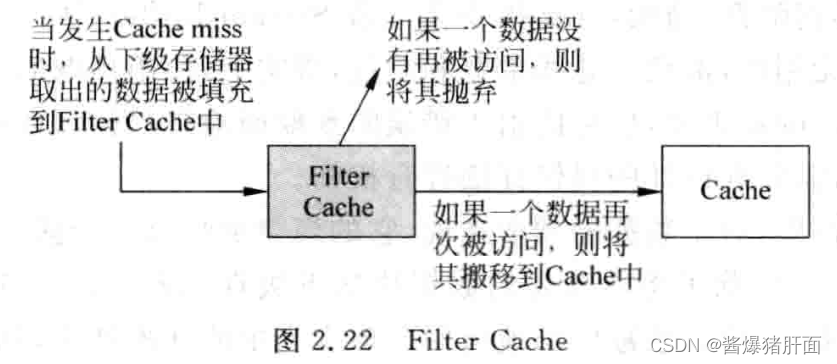
2.5 预取
-
场景动机:解决Cache 3C中的Compulsory
-
解决方向:分硬件预取和软件预取
-
解决:硬件预取
- 对于指令(I-Cache)
-
动机:程序串行执行,猜测后续执行什么指令是相对容易的
-
实现:访问I-Cache中的一个数据块(data block)时,将它后面的数据块也取到I-Cache中
-
存在问题:Cache污染
Aside: Cache污染 程序存在分支指令,猜测出错时导致被使用的指令进入I-Cache。降低I-Cache可用空间;占用了原本可能有用的指令 -
解决:将预取指令先放到一个单独的缓存中(Stream Buffer)
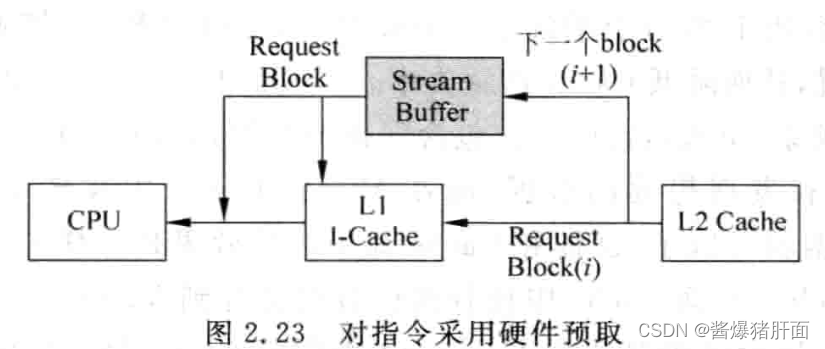
-
利弊权衡
- 好处:减少Cache的缺失率
- 坏处:错误预取导致浪费功耗和性能
-
- 对于数据(D-Cache)
- 思考:是否可仿照上述对于指令I-Cache的预取方式设计?
- 存在问题:数据不如指令有规律性,程序访问的数据可能不在下一数据块中
- 解决:Strided Prefeching(观测预测数据访问步长)
例如,观测访问地址a、a+128、a+256,则预测下次访问a+384。甚至预取a+512、a+640等
- 对于指令(I-Cache)
-
解决:软件预取
- 思路:在编译阶段使用编译器对程序进行分析
- 实现:指令集有预取指令,则通过指令预取?
- 注意:预取的时机把握
- 预取过晚:真要用数据的时候还没准备好
- 预取过早:可能踢掉D-Cache中本有用的数据,造成Cache污染
- 要求:预取指令不能阻碍后续指令的执行,则要求D-Cache是非阻塞(non-blocking)的
- 其他问题:在虚拟存储器中,预取指令或引发异常(exception)。按处理方式划分为:
- 处理错误的预取指令(Faulting Prefetch Instruction)
- 不处理错误的预取指令(Nonfaulting Prefetch Instruction),则发生异常的预取指令变成一条空指令
3 多端口Cache
3.1 True Multi-port
概述:一个Cache多个port
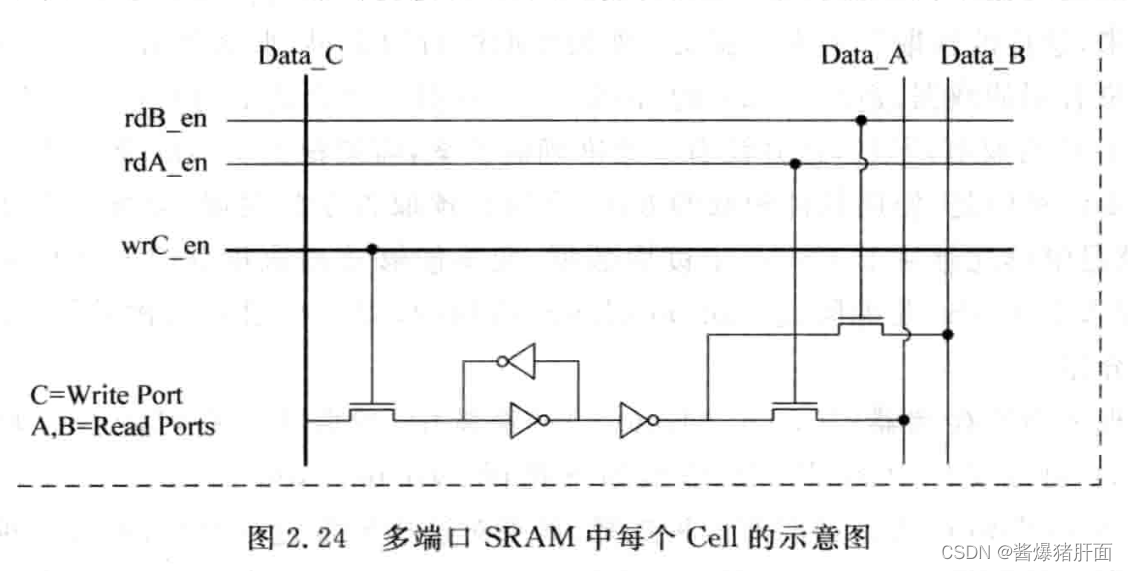
实现:对电路进行复制
优点:精确提供双端口Cache功能
缺陷:将很多电路进行复制,现实中不用这种设计
3.2 Multiple Cache Copies
概述:多个Cache,每个Cache一个port(共用一个store port)
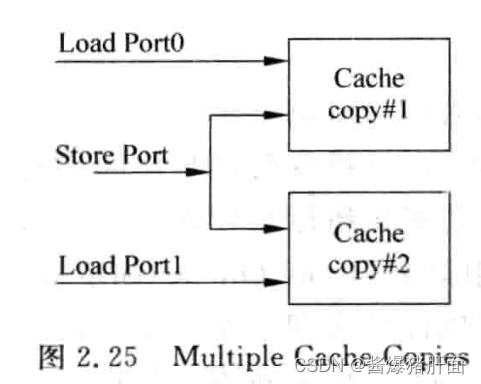
缺陷:需要保证两Cache的一致性问题,很少使用
3.3 Multi-banking
概述:Tag SRAM多端口;Data SRAM非多端口
实现:将Cache划分为多个小的bank(每个bank一个端口),不同bank的访问可在同一周期内进行:同一bank的访问则需要多个周期
| Aside: bank冲突(bank-conflict) |
|---|
| 两个或多个端口的地址位于同一个bank之中,引起冲突 |
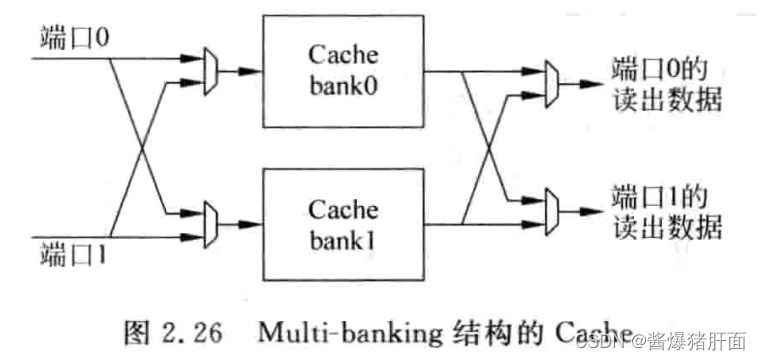
注意:影响多端口Cache性能的一个关键就是bank冲突,可采用更多bank来缓解
优点:总线面积降低,不会对处理器周期造成太大影响
3.4 真实的例子AMD Opteron的多端口Cache(略)
4 超标量处理器的取指令
| Aside: N-way超标量处理器 |
|---|
| 每个周期可以同时解码 n条指令 |
要求:n-way超标量处理器给一个取指令的地址,I-Cache应该至少送出n条指令,n条指令为一组,即fetch group。
*概念辨析:n-way处理器是以解码能力为依据定义的,而至于实际取指则是出于对流水线充分利用的角度出发的理想目标
即解码与取指的指令个数并不要求一致,即可能出现每周期取指条数多余解码条数的!
方法:具体而言,即data block大小为n个字,每周期全部输出
理想:处理器取指令地址是n字对齐的,则实现每周期从I-Cache读n条指令功能
现实情况:由于跳转指令的存在,处理器送的取指令地址不可能总是n字对齐的
一个fetch group落在两个Cache line中
而每周期只能访问一个Cache line
导致一个周期内无法取出n条指令
进而导致后续流水线无法得到充足指令,部分资源“空置”
评估指标:平均每周期指令数,即期望
以4-way为例,这个期望为2.5,即平均每周期能取指2.5条
对于4-way是不划算的,但是对于2-way绰绰有余(注意上述对n-way处理器定义的概念辨析 )
现实情况:每周期取指令数大于能够解码的指令数
存在问题:取指速度快于解码速度,来不及解码怎么办?
解决:通过缓存将多余指令缓存起来
例如:MIPS 74Kf
2-way超标量处理器
取值四字对齐时,每周期取4条指令
指令取值暂存指令缓存(Instruction Buffer,IB)
后续指令解码器从指令缓存中取指令
现实问题:实际中,平均每周期取指令往往多于2.5
即使本周期不是四字对齐的,那后面周期也会变成四字对齐
进阶解决:用数据块(data block)变大的方式,在非四字对齐时每周期读取四条指令
除非取值地址落在line最后三个字,否则都能保证每周期读四条指令
八字数据块的平均每周期取指数为3.25

引发问题:Cahe容量增大,Cache set个数减少,增加Cache缺失率
现实问题:每个SRAM周围要布保护电路,若按八个SRAM实现,则保护电路占用面积过大
实际实现:用四个SRAM实现大小为八个字的数据块
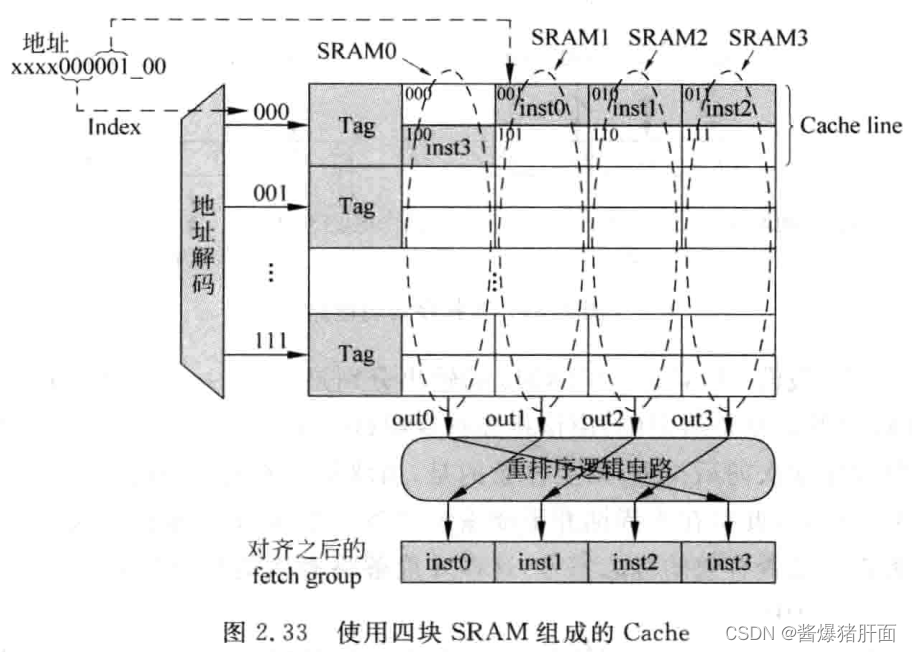
说明:
- 一个Cache line占了SRAM的两行
- 问题:有些SRAM读第一行,有些读第二行。需要有个电路控制其读地址
- 问题:四个SRAM的输出并不是按指令原始顺序排序的,需要有个重排序逻辑电路,以满足原始顺序
- 需求:
- 一个控制电路产生每个SRAM的读地址
- 另一个控制电路将四个SRAM输出的内容进行重排序,使其按照程序中规定的原始顺序进行排列
总结
Cache是处理器存储层次中非常重要的部分。其他教科书可能上来直接就只讲了multi-bank的常用、经典设计,而很少谈促成这种设计的历程与思考(前两种naive设计存在的弊端)。而《超标量处理器设计》一书中从问题的根源:为什么需要Cache出发,结合Cache设计的洞见逐步展开。介绍了Cache的基本概念,包括三种组成方式、三种冲突,以及经典以及超标量处理器场景下提升Cache性能的方法。涵盖了多端口Cache的设计方法以及利弊分析。整体看来,《超标量处理器设计》第2章除了涵盖Cache基本知识内容本身外,还蕴藏着一条纲。这条纲从为什么需要Cache作为起点,串联其了Cache的知识点。同时,这条以问题为导向的纲也推动着篇章的展开。
书中包含很多细节的内容这里没有展开(包括平均每周期取指的期望计算等),还请结合书本阅读学习。















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









