







超标量处理器基础-笔记
现代处理器设计经典书籍,2004年出版

第一章 处理器设计
1.2 指令集处理器设计
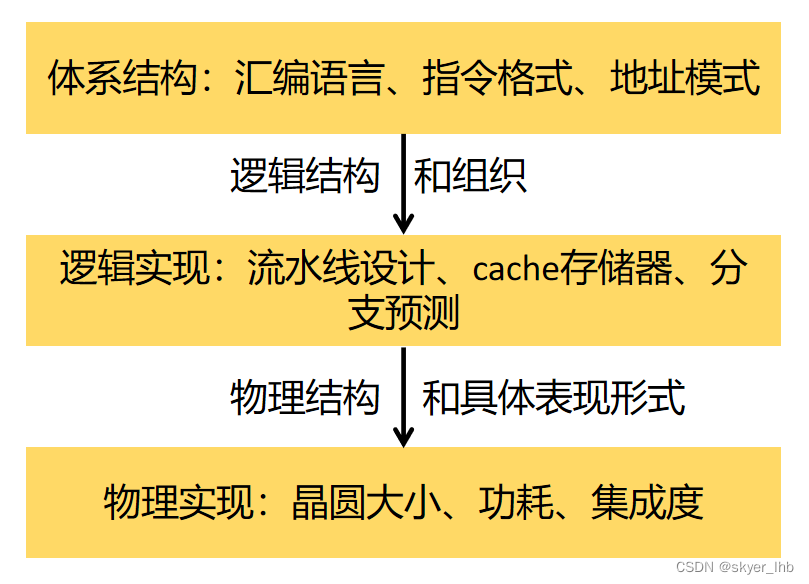
1、微处理器的设计规范就是指令集体系结构(ISA),它定义了微处理器必须执行的一整套指令集,程序可根据ISA的规定开发而无需了解任何有关实际机器的实现细节。体系结构、逻辑实现与物理实现的关系及相关概念如下图:
2、ISA动静态接口(DSI):区别哪些是在编译时静态完成的,哪些是在运行时动态完成的。

1.3 处理器性能法则
处理器性能是根据执行一段特殊代码所需要的时间来衡量的。
- 特定的程序需要执行的动态指令的数目;
- 平均执行一条指令需要花费多少个时钟周期;
- 每个时钟周期所需要的时间
1 性能 = 时间 程序 = 指令 程序 ⋅ 周期 指令 ⋅ 时间 周期 \frac{1}{性能}=\frac{时间}{程序} =\frac{指令}{程序} \cdot \frac{周期}{指令} \cdot \frac{时间}{周期} 性能1=程序时间=程序指令⋅指令周期⋅周期时间
1.4 指令级并行处理
指令数由ISA、编译器和操作系统决定。
第二章 流水线处理器
2.1 流水线基础
- **流水线定义:**将系统分割成许多段,在段与段之间增加适当的缓冲,这些段及其缓冲就构成了流水线。流水线的每一段可看做一个组合逻辑加上一个锁存器,信号通过组合逻辑之后在锁存器处锁存。
- **提出动机:**提高系统吞吐率(带宽)的同时几乎不增加硬件开销。
- **限制流水线时钟频率的因素:**组合逻辑的最长和最短传输延迟之差、为正确建立时钟信号所需要的额外延迟。
- **理想流水线假设及挑战:**一致的运算分量(保持流水段均衡);重复的运算(同一指令类型);独立的运算(减少流水线停顿)。
2.2流水线处理器的设计
1、流水线硬件要求:
- 每一段进行控制和完成数据操作的逻辑;
- 支持多个流水线同时访问的寄存器文件端口;
- 支持多个流水段同时访存的存储器端口。
2、要完成一次运算,计算机必须完成以下三个基本任务:
- 算术操作(ALU指令):对指定操作数执行算术和逻辑运算,这是整个运算中最突出的部分;
- 数据移动(load/store指令):负责将操作数和结果在存储地址之间进行移动;
- 指令排序(分支指令):负责指令顺序的确定。
3、现代ISA倾向于采用定长、正交的指令格式、load/store型指令结构和简单的寻址模式。
2.3 深流水线处理器
目标:通过减少每段的逻辑门数来降低时钟周期,从而提高主频。
主要障碍:指令相关引起的流水线停顿。
第三章 超标量结构
**本质特点:**可以同时发射多条指令;乱序执行。
3.1 标量流水线的局限性
| 标量流水线局限性 | 改进的超标量流水线方法 |
|---|---|
| 标量流水线最大吞吐率不会超过每周期一条指令 | 每个时钟周期启动多条指令执行 |
| 将不同类型的指令放在同一条流水线中处理,效率低下 | 多配置流水线、多记录缓冲技术 |
| 为了保证流水线的步调一致而插入的停顿使流水线产生很多气泡 | 动态流水线 |
3.2 超标量流水线综述
**1、取值:**实现每周期读取出s条指令
主要障碍:
- 读取的s条指令没有对齐,这和指令cache的物理组织有关;
- 控制流改变了取值集中的指令。
对齐问题的解决方法:
- 编译时使用静态技术,编译器了解指令cache的组织结构。
- 执行时由硬件协助解决,即使指令组跨越阵列行边界,对齐硬件也能保证一个周期内取出s条指令。
**2、指令译码:**指令的识别、指令类型确定及指令间相关性的检测。
影响其复杂度的因素:
- ISA;
- 并行流水线的宽度。
预译码:将指令译码的部分工作转移到指令cache进行。
对处理器设计的影响:
- 增加了指令cache的失效开销;
- cache的大小由于存储预译码标识位而增大。
**3、指令分派:**将在译码段确定类型的指令发射到相应的部件执行。
**4、指令执行:**执行除浮点指令的其他指令
5、指令的完成和提交
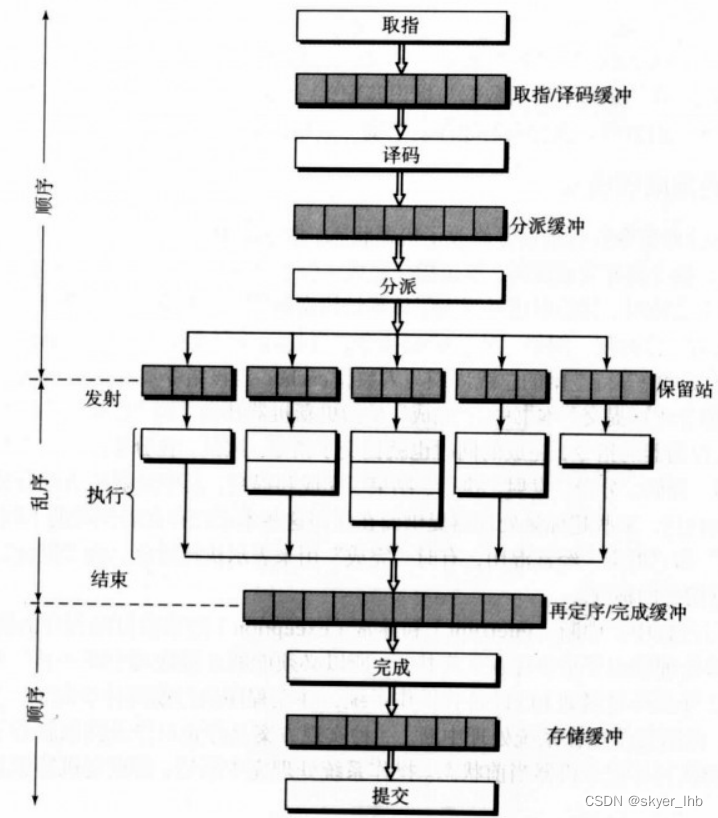
超标量流水线的基本结构如下:前端是顺序执行,执行段式乱序执行,后端是顺序提交。
第四章 超标量技术
**重点:**超标量处理器执行指令时的动态行为,及针对某些特殊指令的处理技术。
**目标:**获得最大的指令吞吐率;
4.1 指令流技术
**用途:**一般用在取值段和译码段。
**目标:**在每个机器周期内为处理器内核提供尽可能多的有用指令,减少指令停顿或利用这些停顿周期进行有用的工作。
**主要挑战:**条件分支和转跳分支的处理。
条件分支指令的停顿开销:
- 生成目标地址引起的开销;
- 条件判定引起的开销;
分支预测:
- 分支目标地址的推测,可通过设置分支目标缓冲BTB来实现,用来保存前几次分支执行时的目标地址。
- 分支方向推测,方法1,设置取值硬件总是预测为不跳转。方法2,需要软件协同,对ISA进行修改。方法3,基于历史信息做分支预测。
动态分支预测可看做由两个相互影响的模块组成,前面的模块负责在流水线的前端推测分支方向和目标地址;后面的模块负责在流水线的后端验证推测的结果。
如果预测失败,需要执行:结束当前指令流并从一个新的、正确的地址取值。
4.2 寄存器数据流技术
**含义:**指ALU(寄存器-寄存器型)指令在处理器执行部件中的有效执行。
寄存器的重用:
- 含义:特定ISA体系结构的寄存器数目有限,寄存器分配工具必须将无限的寄存器符号资源映射到有限的、固定的体系结构上。
- 缺点:会导致假数据相关、反相关和输出相关。
寄存器重命名:
- 含义:为同一体系结构寄存器中的多个定义动态分配不同的名字。
- 一般方法:在体系结构寄存器文件之外配置一个独立的重命名寄存器文件(映射表技术);
- 任务:读取源寄存器;分配目的寄存器;更新寄存器。
4.3 存储器数据流技术
存储器指令负责在存储器和寄存器文件之间传递数据。
存储器数据流指令的执行步骤:生成存储器地址、存储器地址转换和数据访问。
虚拟存储器是一种将程序的虚拟地址空间映射到机器物理地址空间的机制。
访问多端口存储器的方法:通过地址索引查找、通过标签相联查找和通过组相联寄存器(即用索引又用相联查找)。
4.3 存储器数据流技术
存储器指令负责在存储器和寄存器文件之间传递数据。
存储器数据流指令的执行步骤:生成存储器地址、存储器地址转换和数据访问。
虚拟存储器是一种将程序的虚拟地址空间映射到机器物理地址空间的机制。
访问多端口存储器的方法:通过地址索引查找、通过标签相联查找和通过组相联寄存器(即用索引又用相联查找)。
















 1762
1762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











