










1.前言
本文提供了用深度学习去入门一个简单的情感分类模型,讲述从酒店评论数据获取,到如何使用2018年最强的开源代码BERT去训练一个模型,最后对调优做一些讨论:我们如何去获得更好的效果?如何在实际生产上去落地?如果读者想深入了解BERT代码内部究竟发生了什么,是怎样实现分类的,欢迎阅读 BERT run_classifier.py 源码中文注释
2.环境
- python 3.6
- tensorflow 1.14
python 2.7以后的版本中将不再维护,推荐使用目前最稳定的python 3.6
TensorFlow 2.0以上涉及到部分函数的更新,推荐使用TensorFlow 1.14 更稳定
3.数据获取
我们选取ChnSentiCorp_htl_all数据集,里面包含7000 多条酒店评论数据,5000 多条正向评论,2000 多条负向评论,这些评论数据有两个字段:label, review
数据字段:
Label:1表示正向评论,0表示负向评论
Review:评论内容
数据地址是:https://raw.githubusercontent.com/SophonPlus/ChineseNlpCorpus/master/datasets/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv
可以复制粘贴到你的新建文件中
4.数据预处理
1.把以上地址的所有数据复制粘贴到一个文件中: all.csv
2.稍微清洗一下,去除评论内容左右的空格
3.把数据打乱一下,因为原始数据前面几千条全是正向评论,后面几千条全是负面评论,应该shuffle一下
3.把全量数据切分为训练集、验证集和测试集,建议使用jupyter notebook
import pandas as pd
all_data = pd.read_csv('all.csv', dtype=str)
# 删除评论前后空格
all_data = all_data.applymap(lambda x: str(x).strip())
# 打乱数据-shuffle
all_data = all_data.sample(frac=1).reset_index(drop=True)
# 划分数据集 可以计算一下8:1:1是 6212:777:776
train_data = all_data.iloc[:6212]
dev_data = all_data.iloc[6212:6989]
test_data = all_data.iloc[6989:]
# 对于训练模型时,BERT内部数据处理时,要求数据集不要表头
train_data.to_csv('train.tsv', sep='\t', header=False, index=False)
dev_data.to_csv('dev.tsv', sep='\t', header=False, index=False)
test_data.to_csv('test.tsv', sep='\t', header=False, index=False)
5.模型下载
BERT是2018年Google开源的最强大的预训练模型,可以完成多种NLP任务,如文本分类,命名实体识别,序列标注,问答,阅读理解…均在18年刷新了各大榜单
- github 上BERT 训练代码 的地址:https://github.com/google-research/bert
# 训练代码下载
git clone https://github.com/google-research/bert.git
- BERT-base预训练模型下载
点击绿框即可下载 BERT-Base 的中文预训练模型,364M大小的zip包

解压后可以看到几个文件:
一般这几个文件我们 只载入,不改动 - bert_model.ckpt : 负责模型变量载入
- vocab.txt : 训练中文文本所采用的字典
- bert_config.json : BERT在训练时,配置的一些参数
6.模型修改 - 情感分析
这是一个文本分类项目,使用BERT源码里的 run_classifier.py 文件即可训练,在训练之前,还需要根据实际的任务,对模型做以下简单的修改:
1.大概在run_classifier.py的409行后面,加入一个处理情感分析的类:
- 最主要的改动是get_labels()中是二分类就自己定义一个标签列表 [“0”, “1”],是三分类就定义 [“0”, “1”, “2”]
- 然后在_create_examples()中,text_a:实际上就是你输入的一条评论文本,label就是该评论对应的实际标签,是0还是1,是‘开心’还是‘不开心’;评论文本与标签在csv文件中的分隔符应与BERT源码中保持一致,默认为’\t’,有时候碰到解析错误,可以回顾分隔符的问题
class SentimentAnalysisProcessor(DataProcessor):
"""Processor for the sentiment analysis"""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["0", "1"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
# Only the test set has a header
guid = "%s-%s" % (set_type, i)
text_a = tokenization.convert_to_unicode(line[1])
label = tokenization.convert_to_unicode(line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
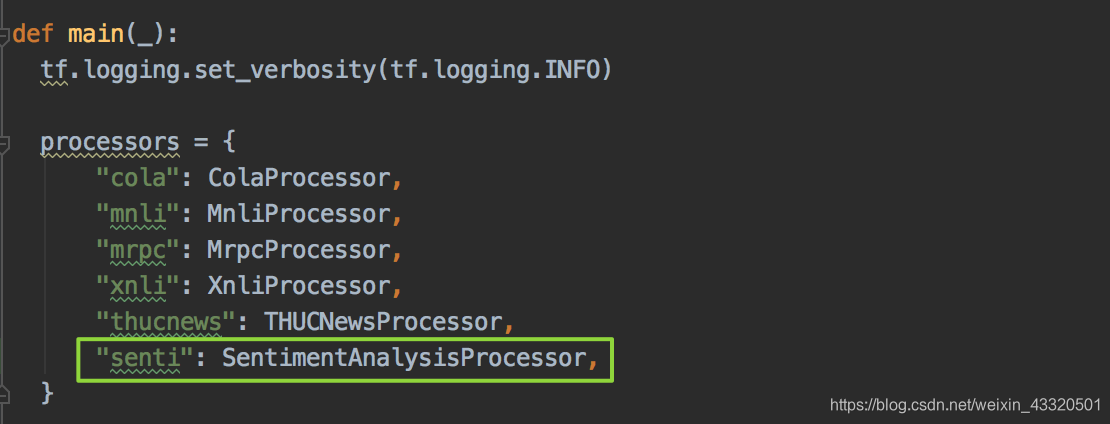
2.在main()函数中,添加这个类:
"senti"这个是任务名称,在这里是什么,那么在训练脚本中的task_name就应该填什么
7.模型训练 -(服务器/本地)
1.新建数据集目录data_set:把前面生成的train.tsv, dev.tsv, test.tsv放到data_set目录下
2.新建模型输出目录output
3.把预训练模型chinese_L-12_H-768_A-12上传
训练脚本:
# 指定你使用哪个GPU,不指定会默认使用所有的GPU
export CUDA_VISIBLE_DEVICES=3
# 指定你的预训练模型位置
export MODEL_PATH=nlp/bert/chinese_L-12_H-768_A-12
# 指定你的输入数据的目录(该目录下,放着前面的三个文件train.tsv, dev.tsv, test.tsv)
export DATA_PATH=nlp/bert/data_set
# 指定你的模型输出目录
export OUTPUT_PATH=nlp/bert/output
nohup python run_classifier.py --vocab_file=$MODEL_PATH/vocab.txt --bert_config_file=$MODEL_PATH/bert_config.json --init_checkpoint=$MODEL_PATH/bert_model.ckpt --data_dir=$DATA_PATH/ --task_name=senti --output_dir=$OUTPUT_PATH/ --do_train=True --do_eval=True --do_predict=True > server.log 2>&1 &
命令:tail -f server.log 查看模型有没有跑起来
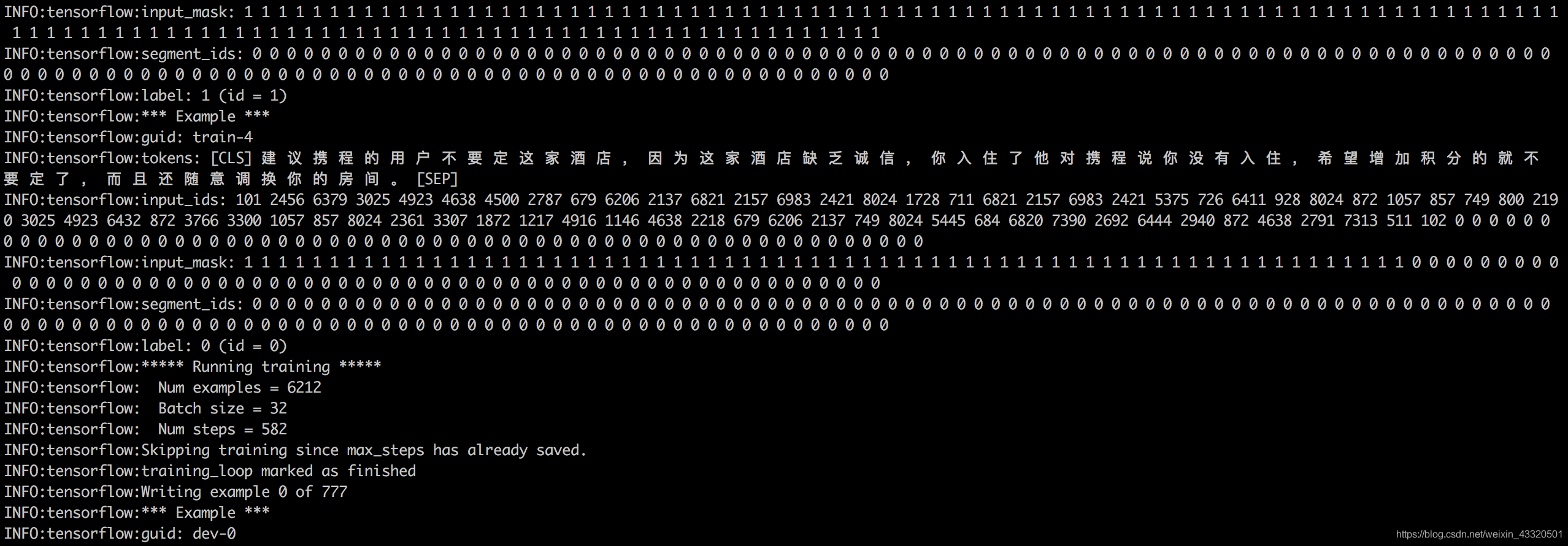
发现,模型已经成功运行起来了,用v100的显卡,模型在GPU上大概10分钟能跑完
8.模型效果
在输出目录:output下可以看到生成了很多文件:
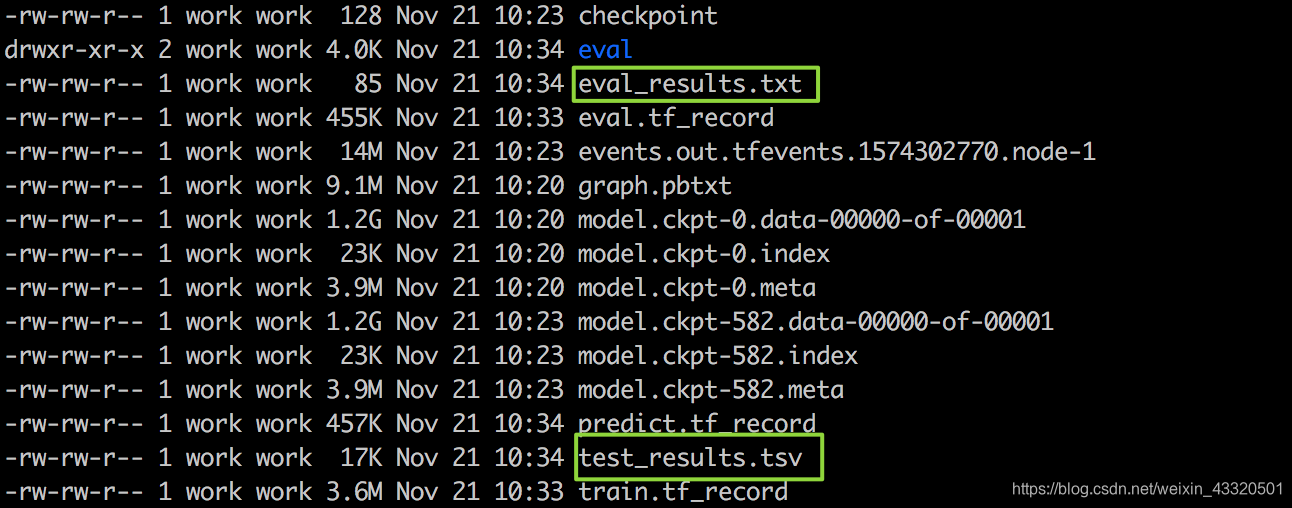
- model.ckpt 这些是模型文件
- eval_results.txt:这个是验证集的评估文件:
可以看到咱们未调参就有 0.907 的准确率,效果棒棒哒

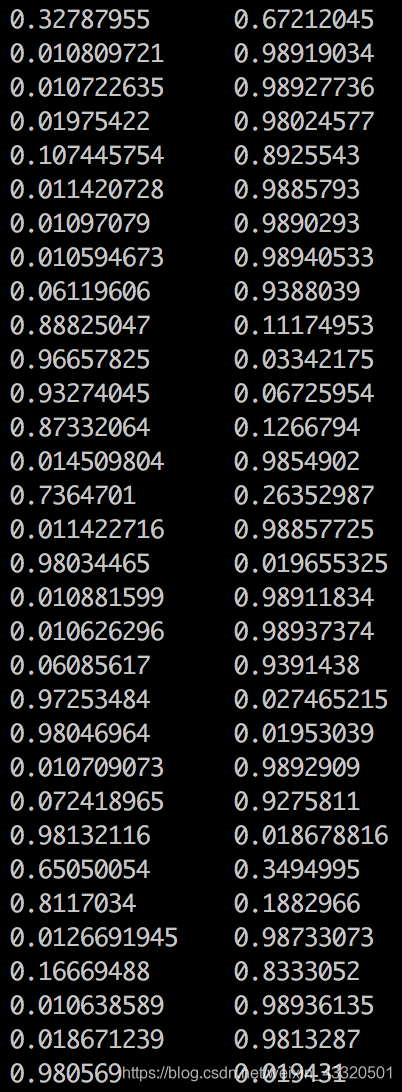
- test_results.tsv: 这个是测试集的评估文件,输出的是测试集每条评论,是正向评论还是负面评论的概率
9.模型优化
本文使用BERT模型的原始参数就获得了0.907的准确率,后续建议读者调试 run_classifier.py 中的以下超参数以获取更好的模型效果:
-
max_seq_length:最大序列长度,超过这个长度的文本会被切割,不足这个长度会被填充,如果文本较长,可以从128调到256,甚至512
-
train_batch_size:如果max_seq_length变大,这个参数就得变小,不然会出现显存资源不足的问题:具体对应关系可以参照:
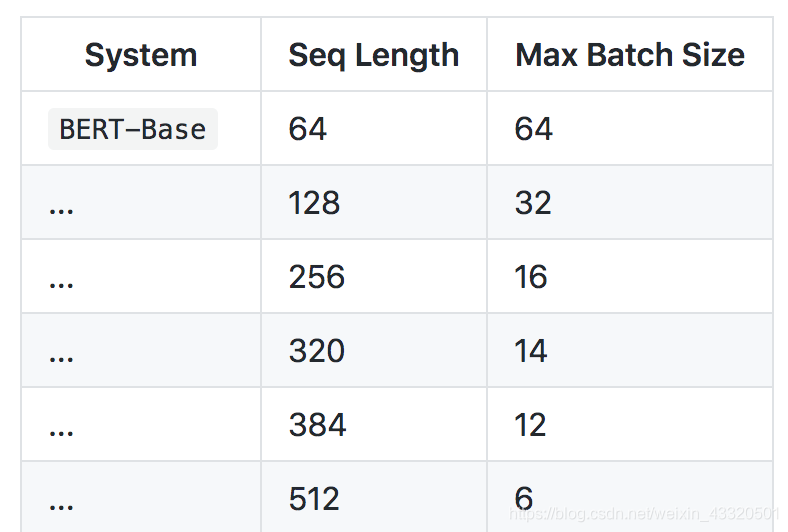
-
learning_rate:学习率, 可以试试3e-3,1e-3等等
-
num_train_epochs: 全体训练集样本训练轮数,可以适当调大些,如:3 -> 5 -> 8,但是不要过大,防止模型过拟合
10.工业级优化
作者在实际项目中的多次尝试,发现,普遍对于情感分类的自然语言处理项目,在实际生产中,最有效提升分类效果的方法是提升数据集的质量,在这里我们的做法是:
- badcase分析:提升分类准确性:诸如百度之类的大厂的一些算法团队用的次数比较多的方法,跑出一批测试集后,我们对预测的结果和它真实对应的标签进行比较,很多时候,会发现,模型预测的结果是对的,但真实标注的类别是模棱两可甚至是错误的,这时候就需要人为对标注错误的数据进行全面核实修改,这也是实际算法迭代开发中时间占比较多的一类工作
- 性能优化:实际BERT推理速度已经非常快乐,要进一步提升性能的话,BERT这些模型完全可以尝试使用TensorRT等做性能优化,实测效果喜人

















 1777
1777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









