







 本文记录了使用Bert模型参加DataFountain的‘疫情期间网民情绪识别’挑战赛的过程,通过数据预处理、Bert模型训练,最终达到Top5%的成绩。讨论了数据不平衡、情感趋势和模型选择,提出Bert模型的优势以及未来优化方向。
本文记录了使用Bert模型参加DataFountain的‘疫情期间网民情绪识别’挑战赛的过程,通过数据预处理、Bert模型训练,最终达到Top5%的成绩。讨论了数据不平衡、情感趋势和模型选择,提出Bert模型的优势以及未来优化方向。
问题描述
之前参加了DataFountain上的‘疫情期间网民情绪识别’的挑战赛,最终成绩是Top5%。达到了0.734的成绩,挑战赛主要内容是分析疫情期间的用户微博极性,分为消极-1,中性0以及积极1三种。本篇文章主要是对数据进行一定分析和做一个通过以该数据为基础的bert实战记录。相信通过这篇文章,使用bert等工具也可以轻车熟路。
数据分析
数据来源:疫情期间网民情绪识别-DataFountain:数据包括俩个部分:
- 训练集:包括微博id等7个列,数据量为10w行:

- 测试集:除情感倾向为空外的6个列,数据量为1w行;
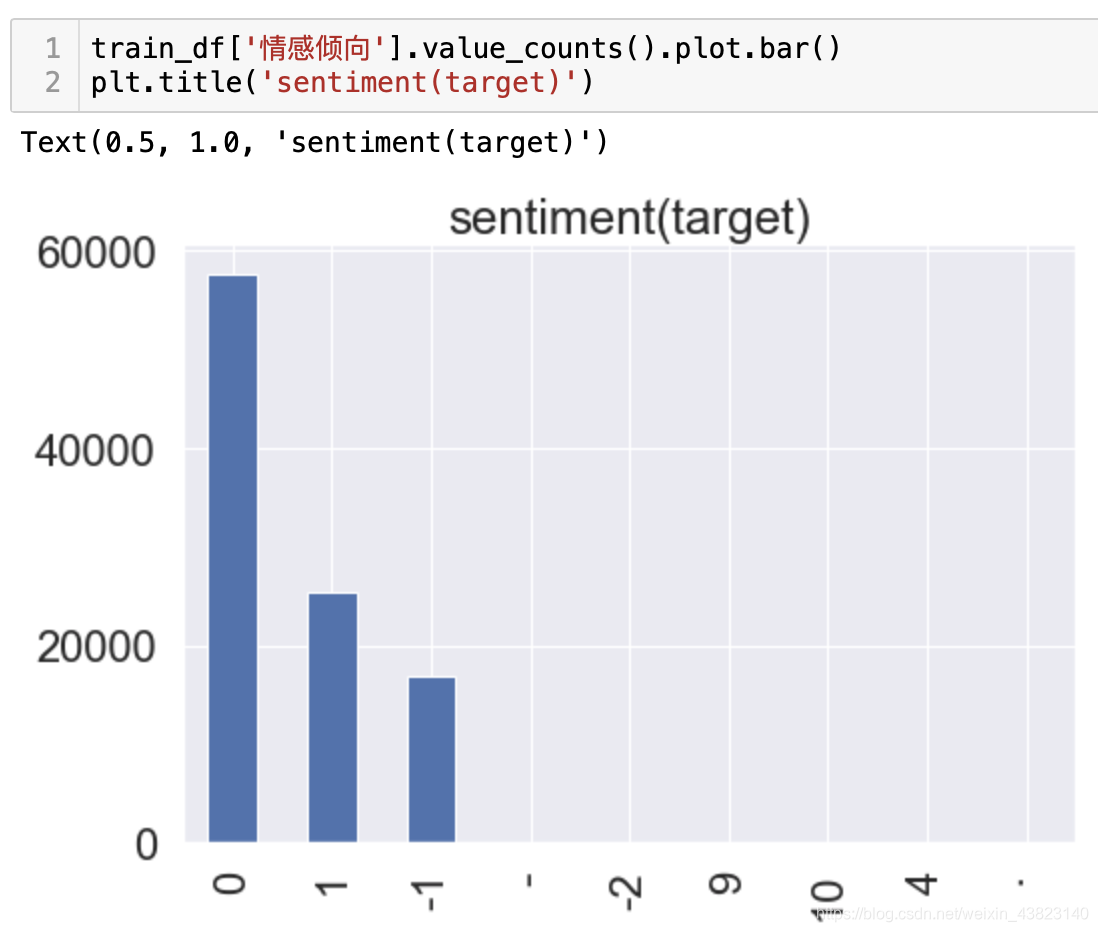
对于训练集我做了一些简单的数据预处理与分析,首先是用户情感倾向,是否有-1,0,1之外的其他噪声数据,通过观察我们发现确实存在一些噪声数据,并进行了消除;同时发现用户数据还具有一定的不平衡性,中性数据较多,如果判别标准是正确率的话,平衡影响并不大,但如果是F1作为评测标准的话,还是需要一定的trick作为修正的,这在之后会讲到,该赛题就是以F1作为评测标准的。
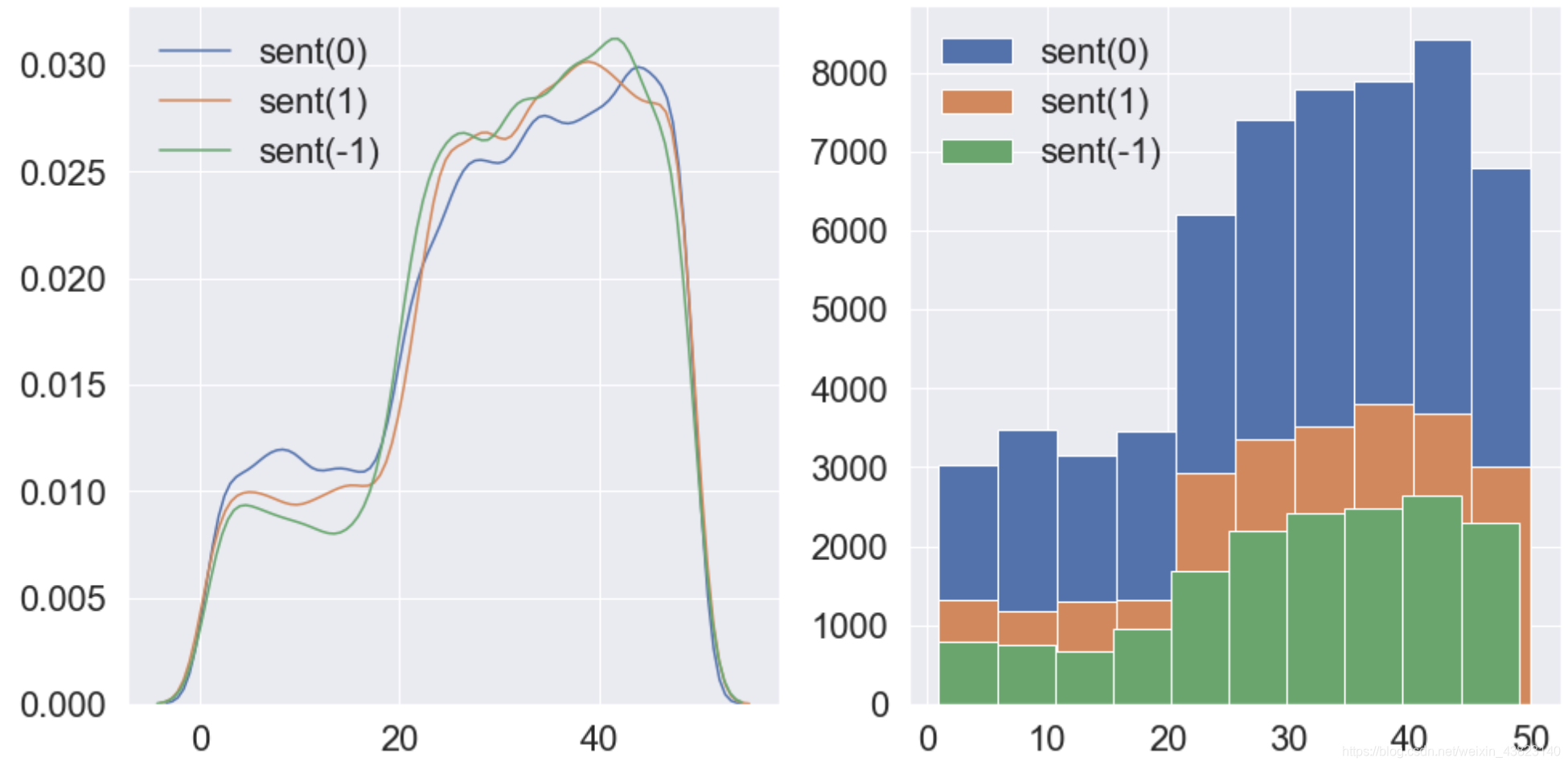
用户情感变化与时间关系:在这里我们发现在40天左右(大约2月6日,这里将年月日改成了天数做分析)网民情绪最激烈。
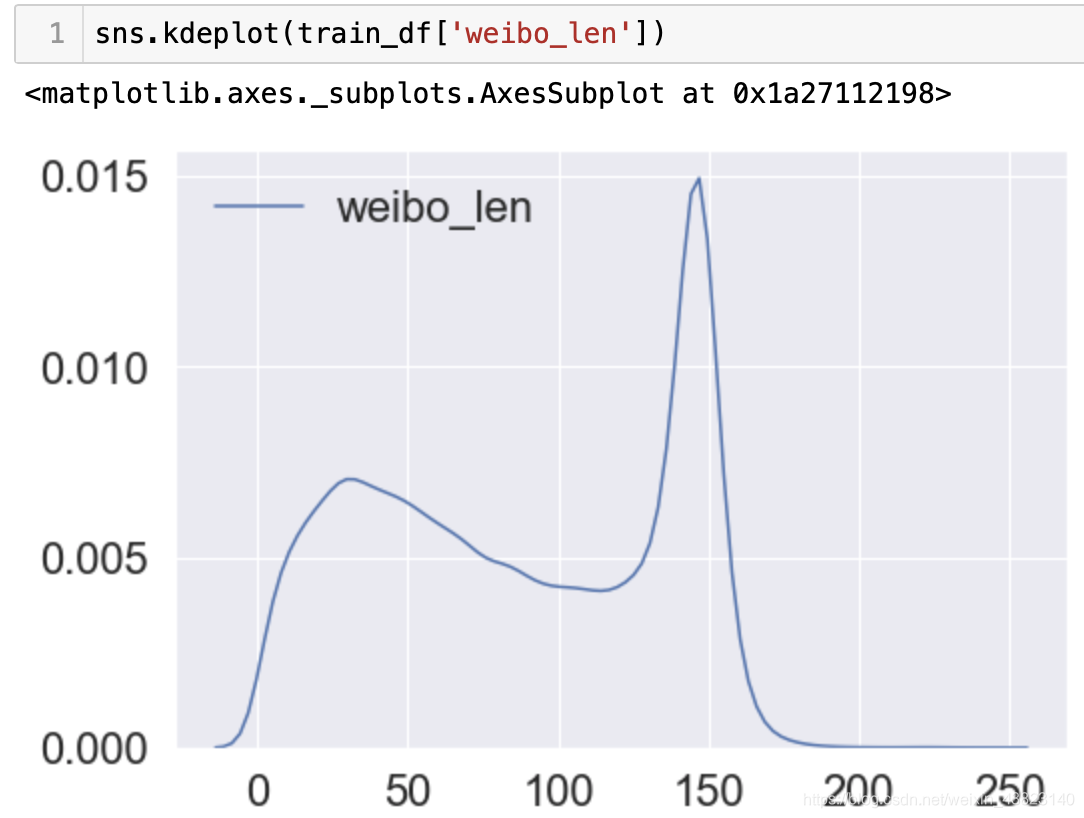
最后还有对用户的文本做分析,判断文本长度,这对于后面bert使用的文本截断有很重要的参考作用;我们发现,文本长度普遍小于150字。
Bert简述与使用
有了数据,并对数据做了一些预处理之后,就开始使用各种各样的模型对数据做训练了,尝试了SVM,TextCNN,LSTM以及最后的Bert,XLnet等,明显发现Bert等明显做情感分类的训练效果要更好,这里我们要清楚,我们使用Bert模型做训练,实际是一种微调,因为Bert将任务分为了上游任务预训练,训练处一个中文或者英文模型,和下游任务微调,对训练出来的模型匹配自己的场景,做微调,实际上,上游段一般是不需要我们参赛者考虑的,已经有很多优秀的公司做了中文的文库及Bert,Xlnet等模型的预训练,包括科大讯飞以及哈工大一些高校。这里推荐两个预训练模型库:
Xlnet预训练模型
Bert及相关预训练模型
对于里面的模型,我们可以轻易的转存到Google Drive,之所以使用Google Drive是因为其拥有比较丰富的GPU,例如P100,T4,P4等,至于Google Drive中的Colab如何使用,相信csdn以及知乎已经有很多人介绍过了,很容易上手类似于Jupyter,也很容易piao到GPU,重要的是完全免费
对于模型使用,进入上述两个网站,点击下面图片的红框部分,就可以轻松上传到Google Drive中,是不是特别简单呢hh。


Bert训练过程
对于Bert等预训练模型,加载他们的模型库在github也有明确写道
依托于Huggingface-Transformers 2.2.2,可轻松调用以上模型
所以想使用这些预训练模型,需要pip一个transformers库,实际上,使用pytorch_pretrained_bert库也可以,bert我用的是这个库,在之后使用xlnet时我使用的是transformers库,这个库特别好,不论是理解bert模型本身,还是调用它,实现一个自己做的Transformer都十分不错,代码逻辑清晰。
代码部分讲解:
首先是安装必要库,因为colab对于pytorch已经完全实现安装,所以你需要安装的只有预训练bert代码库;
!pip install pytorch_pretrained_bert
安装完成后就是引用必要的代码库
import torch
import pandas as pd
import numpy as np
from pytorch_pretrained_bert import BertTokenizer
from tqdm import tqdm
import torch.utils.data.dataloader as dataloader
from sklearn.metrics import accuracy_score,recall_score,f1_score
from pytorch_pretrained_bert import BertForSequenceClassification,BertModel
from pytorch_pretrained_bert import BertAdam
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
from sklearn.metrics import accuracy_score,recall_score,f1_score
from sklearn.model_selection import StratifiedKFold
import time
import random
首先是对一些必要字段的定义,如batch_size,seq_len等
MAX_SEQUENCE_LENGTH = 140
batch_size = 64
epochs = 9
input_categories = '微博中文内容'
output_categories = '情感倾向'
之后是对数据集的引入,包括训练集和测试集
train_df = pd.read_csv('nCoV_100k_train.labled.csv',header=0)
test_df = pd.read_csv('nCov_10k_test.csv',header=0)
train_df1 = train_df.copy()
train_df1=train_df1[~train_df1['情感倾向'].isin(['9','-','·'])]
train_df1 = train_df1.fillna(10)
train_df1=train_df1[~train_df1['情感倾向'].isin(['-2','10','4',10])]
当然,对于我们第一次引入的bert预训练模型也要解压
import zipfile
f = zipfile.ZipFile("chinese_roberta_wwm_ext_pytorch.zip",'r')
for file in f.namelist( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2909
2909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









