导入相关库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
%matplotlib inline
数据预处理
df = pd.read_csv(r'...\data\titanic_train.csv')
df['Age'] = df['Age'].fillna(df['Age'].median())
df['Fare'] = df['Fare'].fillna(df['Fare'].median())
df['Sex'] = 1 * (df['Sex'] == 'female')
df['Embarked'] = df['Embarked'].fillna('S')
df['Embarked'] = df['Embarked'].map({'S': 0, 'C': 1, 'Q': 2})
1. 使用线性回归预测
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import KFold
predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
lr = LinearRegression()
fold = KFold(n_splits=5)
predictions = []
for train, test in fold.split(titanic):
train_predictors = df[predictors].iloc[train, :]
train_target = df['Survived'][train]
lr.fit(train_predictors, train_target)
test_predictions = lr.predict(df[predictors].iloc[test, :])
predictions.append(test_predictions)
predictions = np.concatenate(predictions,axis=0)
predictions = 1 * (predictions > 0.5)
scores = np.equal(predictions, df['Survived']).mean()
print(scores).mean()
0.7878787878787878
2. 使用逻辑回归预测
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(random_state=0, solver='liblinear')
scores = cross_val_score(lr, df[predictors], df['Survived'], cv=5).mean()
print(scores)
0.7890151277383717
3. 使用随机森林算法
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn.ensemble import RandomForestClassifier
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
rf = RandomForestClassifier(n_estimators=50, random_state=0, min_samples_split=2, min_samples_leaf=1)
fold = KFold(n_splits=5)
scores = cross_val_score(rf, df[predictors], df['Survived'], cv=fold)
print(scores.mean())
0.8058753373925052
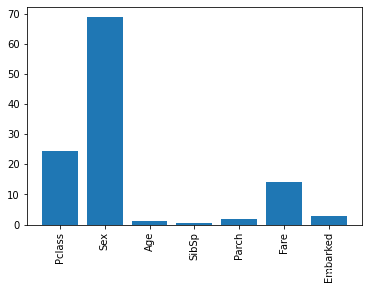
4. 特征重要性
from sklearn.feature_selection import SelectKBest, f_classif
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
selector = SelectKBest(f_classif, k=5)
selector.fit(df[predictors], df['Survived'])
scores = -np.log10(selector.pvalues_)
plt.bar(range(len(predictors)), scores)
plt.xticks(range(len(predictors)), predictors, rotation='vertical')
plt.show()
5. 集成算法
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
algorithms = [
[GradientBoostingClassifier(random_state=1, n_estimators=50, max_depth=3), predictors],
[LogisticRegression(random_state=1, solver='liblinear'), predictors]
]
fold = KFold(n_splits=3)
predictions = []
for train, test in fold.split(df):
train_target = df['Survived'][train]
all_test_predictions = []
for alg, predictors in algorithms:
alg.fit(df[predictors].iloc[train, :], train_target)
test_predictions = alg.predict_proba(df[predictors].iloc[test, :])[:, 1]
all_test_predictions.append(test_predictions)
test_predictions = (all_test_predictions[0] + all_test_predictions[1]) / 2
test_predictions = 1 * (test_predictions > 0.5)
predictions.append(test_predictions)
predictions = np.concatenate(predictions, axis=0)
scores = np.equal(predictions, df['Survived']).mean()
print(scores)
0.8058361391694725






















 800
800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









