









python数据分析及可视化
涉及内容
(1)Pandas的Series数据类型的定义及相关操作函数;
(2)Pandas的DataFtame数据类型的定义及相关操作函数;
(3)Pandas的统计功能;
(4)Pandas的合并连接和排序;
(5)Pandas的帅选和过滤功能;
(6)Pandas的数据导入和导出功能。
Pandas库入门
}
1.生成一维数组
import numpy as np
import pandas as pd
x = pd.Series([1, 3, 5, np.nan])
x
0 1.0
1 3.0
2 5.0
3 NaN
dtype: float64pd.Series(range(5)) # 把Python的range对象转换为一维数组
0 0
1 1
2 2
3 3
4 4
dtype: int32pd.Series(range(5),
index=list(‘abcde’)) # 指定索引
a 0
b 1
c 2
d 3
e 4
dtype: int32
2.二维数组DataFrame的操作
(1)生成二维数组
pd.DataFrame(np.random.randn(12,4), # 数据
index=dates, # 索引
columns=list(‘ABCD’)) # 列名
A B C D
2018-01-31 1.060900 0.697288 -0.058990 -0.487499
2018-02-28 -0.353329 1.160652 -0.277649 1.076614
2018-03-31 2.323984 -0.435853 -0.591344 -0.754395
2018-04-30 -0.077860 -0.432890 1.318615 0.125510
2018-05-31 -0.993383 -1.064773 -0.430447 -3.073572
2018-06-30 -0.390067 -1.549639 0.984916 1.046770
2018-07-31 1.699242 1.088068 1.531813 -0.430381
2018-08-31 0.044789 0.602462 -1.990035 -0.450742
2018-09-30 -0.200117 -0.656987 -0.198375 -0.018999
2018-10-31 -0.326242 -0.105304 -1.512876 0.166772
2018-11-30 -0.057293 -1.153748 -0.875683 1.784142
2018-12-31 -0.285507 0.937567 -0.891066 0.135078
df = pd.DataFrame({‘A’:np.random.randint(1, 100, 4),
‘B’:pd.date_range(start=‘20180301’, periods=4, freq=‘D’),
‘C’:pd.Series([1, 2, 3, 4],
index=[‘zhang’, ‘li’, ‘zhou’, ‘wang’],
dtype=‘float32’),
‘D’:np.array([3] * 4,dtype=‘int32’),
‘E’:pd.Categorical([“test”,“train”,“test”,“train”]),
‘F’:‘foo’})df
A B C D E F
zhang 60 2018-03-01 1.0 3 test foo
li 36 2018-03-02 2.0 3 train foo
zhou 45 2018-03-03 3.0 3 test foo
wang 98 2018-03-04 4.0 3 train foo
(2)查看二维数组数据
df.head() # 默认显示前5行,不过这里的df只有4行数据
A B C D E F
zhang 60 2018-03-01 1.0 3 test foo
li 36 2018-03-02 2.0 3 train foo
zhou 45 2018-03-03 3.0 3 test foo
wang 98 2018-03-04 4.0 3 train foodf.head(3) # 查看前3行
A B C D E F
zhang 60 2018-03-01 1.0 3 test foo
li 36 2018-03-02 2.0 3 train foo
zhou 45 2018-03-03 3.0 3 test foodf.tail(2) # 查看最后2行
A B C D E F
zhou 45 2018-03-03 3.0 3 test foo
wang 98 2018-03-04 4.0 3 train foo
(3)查看二维数组数据的索引、列名和值
df.index # 查看索引
Index([‘zhang’, ‘li’, ‘zhou’, ‘wang’], dtype=‘object’)df.columns # 查看列名
Index([‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’], dtype=‘object’)df.values # 查看值
array([[60, Timestamp(‘2018-03-01 00:00:00’), 1.0, 3, ‘test’, ‘foo’],
[36, Timestamp(‘2018-03-02 00:00:00’), 2.0, 3, ‘train’, ‘foo’],
[45, Timestamp(‘2018-03-03 00:00:00’), 3.0, 3, ‘test’, ‘foo’],
[98, Timestamp(‘2018-03-04 00:00:00’), 4.0, 3, ‘train’, ‘foo’]], dtype=object)
(4)查看二维数组数据的统计信息
df.describe() # 平均值、标准差、最小值、最大值等信息
A C D
count 4.000000 4.000000 4.0
mean 59.750000 2.500000 3.0
std 27.354159 1.290994 0.0
min 36.000000 1.000000 3.0
25% 42.750000 1.750000 3.0
50% 52.500000 2.500000 3.0
75% 69.500000 3.250000 3.0
max 98.000000 4.000000 3.0
(5)对二维数组进行排序操作
df.sort_index(axis=0, ascending=False) # 对索引进行降序排序
A B C D E F
zhou 45 2018-03-03 3.0 3 test foo
zhang 60 2018-03-01 1.0 3 test foo
wang 98 2018-03-04 4.0 3 train foo
li 36 2018-03-02 2.0 3 train foodf.sort_index(axis=0, ascending=True) # 对索引升序排序
A B C D E F
li 36 2018-03-02 2.0 3 train foo
wang 98 2018-03-04 4.0 3 train foo
zhang 60 2018-03-01 1.0 3 test foo
zhou 45 2018-03-03 3.0 3 test foodf.sort_index(axis=1, ascending=False) # 对列进行降序排序
F E D C B A
zhang foo test 3 1.0 2018-03-01 60
li foo train 3 2.0 2018-03-02 36
zhou foo test 3 3.0 2018-03-03 45
wang foo train 3 4.0 2018-03-04 98df.sort_values(by=‘A’) # 按A列对数据进行升序排序
A B C D E F
li 36 2018-03-02 2.0 3 train foo
zhou 45 2018-03-03 3.0 3 test foo
zhang 60 2018-03-01 1.0 3 test foo
wang 98 2018-03-04 4.0 3 train foodf.sort_values(by=[‘E’, ‘C’]) # 先按E列升序排序
# 如果E列相同,再按C列升序排序
# 可以使用ascending=[True,False]指定顺序
A B C D E F
zhang 60 2018-03-01 1.0 3 test foo
zhou 45 2018-03-03 3.0 3 test foo
li 36 2018-03-02 2.0 3 train foo
wang 98 2018-03-04 4.0 3 train foo
(7)二维数组数据的选择与访问
df[‘A’] # 选择某一列数据
zhang 60
li 36
zhou 45
wang 98
Name: A, dtype: int3260 in df[‘A’] # df[‘A’]是一个类似于字典的结构
# 索引类似于字典的键
# 默认是访问字典的键,而不是值
False
60 in df[‘A’].values # 测试60这个数值是否在A列的值中
Truedf[0:2] # 使用切片选择多行
A B C D E F
zhang 60 2018-03-01 1.0 3 test foo
li 36 2018-03-02 2.0 3 train foodf.loc[:, [‘A’, ‘C’]] # 选择多列
A C
zhang 60 1.0
li 36 2.0
zhou 45 3.0
wang 98 4.0df.loc[[‘zhang’, ‘zhou’], [‘A’, ‘D’, ‘E’]] # 同时指定多行和多列
A D E
zhang 60 3 test
zhou 45 3 testdf.loc[‘zhang’, [‘A’, ‘D’, ‘E’]] # 查看’zhang’的三列数据
A 60
D 3
E test
Name: zhang, dtype: object
(8)二维数组的数据修改
df.iat[0, 2] = 3 # 修改指定行、列位置的数据值
df.loc[:, ‘D’] = np.random.randint(50, 60, 4)
# 修改某列的值
df[‘C’] = -df[‘C’] # 对指定列数据取反
df # 查看上面三个修改操作的最终结果
A B C D E F
zhang 60 2018-03-01 -3.0 52 test foo
li 36 2018-03-02 -2.0 52 train foo
zhou 45 2018-03-03 -3.0 59 test foo
wang 98 2018-03-04 -4.0 54 train foo
(9)二维数组数据预处理
二维数组缺失值的处理。
df1 = df.reindex(columns=list(df.columns)+[‘G’])
# 增加一列,列名为G
df1 # 其中NaN表示缺失值
A B C D E F G
zhang 60 2018-03-01 9.0 52 test foo NaN
li 36 2018-03-02 4.0 52 train foo NaN
zhou 45 2018-03-03 9.0 59 test foo NaN
wang 98 2018-03-04 16.0 54 train foo NaN
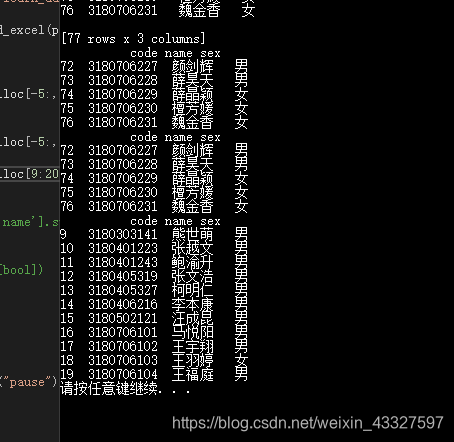
1.打开当前目录下“2018数据科学名册.XLS”文件进行如下操作:
(1)查看头3行,倒数5行,中间的10-20行的数据;删除已经留级的同学;
代码:
path1=“C:/learn_data/learn_d/2018数据科学名册.xlsx”
df=pd.read_excel(path1,names=[‘code’,‘name’,‘sex’])
print(df)
print(df.iloc[:3,:])
print(df.iloc[-5:,:])
print(df.iloc[9:20,:])
执行结果:
(2)查看索引,查看列名,查看值;
代码:
print(df.columns,df.index,df.values)
执行结果:

(3)查找所有“张“姓”同学;
代码:
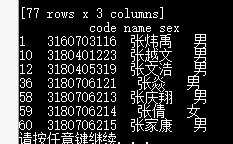
bool=df[‘name’].str.contains(“张”)
print(df[bool])
执行结果:
(4)统计所有男生和女生并计数;
代码:
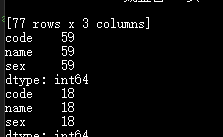
bool=df[‘sex’].str.contains(“男”)
print(df[bool].count())
bool=df[‘sex’].str.contains(“女”)
print(df[bool].count())
执行结果:
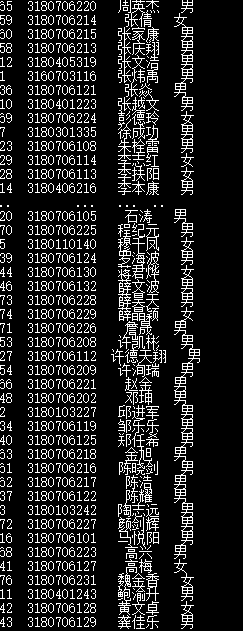
(5)按姓名排序;
代码:
print(df.sort_values(by=‘name’,ascending=True))
执行结果:
(6)按“学号”查找自己的信息;
代码:
print(df[df[‘code’]==3180706223])
执行结果:
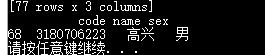
(7)增加“数据库”“python数据分析”两列及成绩;
代码:
df[‘数据库’]=np.random.randint(60,100,len(df))
df[‘python数据分析’]=np.random.randint(60,100,len(df))
执行结果:

(8)对(7)的成绩进行降序排序并进行统计;
代码:
print(df.sort_values([‘数据库’, ‘python数据分析’], ascending=[False,True]))
执行结果:

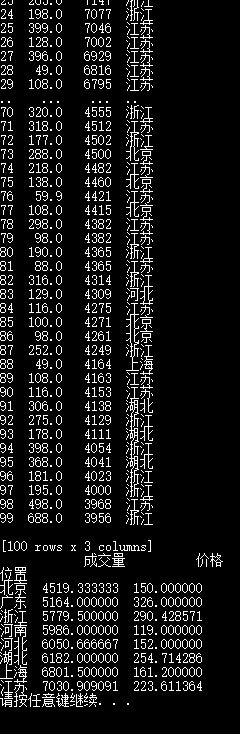
2.利用pandas内置函数read_csv读取并显示taobao_data.csv中的数据。
(1)丢弃“宝贝”和“卖家”两列,按“位置”进行分组,求“价格”和“成交量”的均值,并按照“成交量”的降序排列。
代码:
path1=“C:/learn_data/learn_d/taobao_data.csv”
df=pd.read_csv(path1)
print(df)
df=df.drop([‘宝贝’,‘卖家’],axis=1)
print(df.loc[:,[‘成交量’,‘价格’]].groupby([df[‘位置’]]).mean().sort_values(‘成交量’,ascending=False))
执行结果:
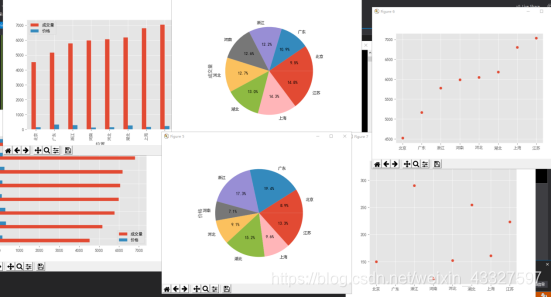
(2)以“位置”为X轴,分别以“价格”和“成交量”为Y轴,绘制出“各省 份的平均价格”和“各省份的平均成交量”的横向柱状图、纵向柱状图、饼图和散点图。
代码:
df.plot.bar()
plt.figure()
df.plot.barh()
plt.figure()
df[‘成交量’].plot.pie(autopct=’%1.1f%%’)
plt.figure()
df[‘价格’].plot.pie(autopct=’%1.1f%%’)
plt.figure()
plt.scatter(x=df.index,y=df[‘成交量’])
plt.figure()
plt.scatter(x=df.index,y=df[‘价格’])
plt.show()
执行结果:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









