










基于词频统计的聚类算法(kmeans)
数据集是三个政府报告文件,这里就不做详细描述了,就是简单的txt文件。
实验过程主要分为如下几步:
1.读取数据并进行停用词过滤
2.统计词频
3.基于三篇文章词频统计的层次聚类
4.基于三篇文章词频统计的k-means
代码如下:
#词频统计模块
import jieba
##########文件操作##########
#读取文本
f = open(r"D:\dataset\文件1.txt","r",encoding='UTF-8')
text = f.read()#读取文件
f.close()#关闭文件
#读取停用词
f_stop = open(r"D:\dataset\中文停用词表.txt","r",encoding='utf-8')
stop = f_stop.read()#读取文件
f_stop.close()#关闭文件
##########文件操作##########
#删除停用词
for s in stop:
text = text.replace(s, "");
text = text.replace(' ', '')
list = jieba.lcut(text)
dict = {}
final_dict = {}
for l in list:
dict[l] = list.count(l);#获取单词数目
if l in final_dict:
final_dict[l][0] = list.count(l)
else:
final_dict[l] = [0 for _ in range(3)]
final_dict[l][0] = list.count(l)
d = sorted(dict.items(),reverse = True,key = lambda d:d[1]); #排序
cnt = 0
for i in d:
cnt += i[1]
print("该文章单词总频率 : ", cnt)
print("前20个单词出现频率为:")
for i in range(20):
print(d[i][0]," : ",d[i][1], '/', cnt);
import pandas as pd
pd.DataFrame(data = d).to_csv('count1.csv',encoding = 'utf-8')
#保存为.csv格式
##########文件操作##########
#读取文本
f = open(r"D:\dataset\文件2.txt","r",encoding='UTF-8')
text = f.read()#读取文件
f.close()#关闭文件
#删除停用词
for s in stop:
text = text.replace(s, "");
text = text.replace(' ', '')
list = jieba.lcut(text)
dict = {}
for l in list:
dict[l] = list.count(l);#获取单词数目
if l in final_dict:
final_dict[l][1] = list.count(l)
else:
final_dict[l] = [0 for _ in range(3)]
final_dict[l][1] = list.count(l)
d = sorted(dict.items(),reverse = True,key = lambda d:d[1]); #排序
cnt = 0
for i in d:
cnt += i[1]
print("该文章单词总频率 : ", cnt)
print("前20个单词出现频率为:")
for i in range(20):
print(d[i][0]," : ",d[i][1], '/', cnt);
pd.DataFrame(data = d).to_csv('count2.csv',encoding = 'utf-8')
#保存为.csv格式
##########文件操作##########
#读取文本
f = open(r"D:\dataset\文件3.txt","r",encoding='UTF-8')
text = f.read()#读取文件
f.close()#关闭文件
#删除停用词
for s in stop:
text = text.replace(s, "");
text = text.replace(' ', '')
list = jieba.lcut(text)
dict = {}
for l in list:
dict[l] = list.count(l);#获取单词数目
if l in final_dict:
final_dict[l][2] = list.count(l)
else:
final_dict[l] = [0 for _ in range(3)]
final_dict[l][2] = list.count(l)
d = sorted(dict.items(),reverse = True,key = lambda d:d[1]); #排序
cnt = 0
for i in d:
cnt += i[1]
print("该文章单词总频率 : ", cnt)
print("前20个单词出现频率为:")
for i in range(20):
print(d[i][0]," : ",d[i][1], '/', cnt);
pd.DataFrame(data = d).to_csv('count3.csv',encoding = 'utf-8')
f_dict = sorted(final_dict.items(), reverse = True, key = lambda d:d[1][0] + d[1][1] + d[1][2])
final_dict_cpy = final_dict.copy()
#保存为.csv格式
pd.DataFrame(data = f_dict).to_csv('count_whole.csv', encoding = 'utf-8')
pd.DataFrame(data = final_dict).to_csv('all_data.csv', encoding = 'utf-8')
#按总频数排序,前二十个对象。
print("前二十个总频率最大的对象:")
for i in range(20):
print(f_dict[i][0], " : ", f_dict[i][1])
print(final_dict)
import numpy as np
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram,linkage
import xlrd as xr
import pandas as pd
from sklearn import preprocessing
from sklearn.cluster import AgglomerativeClustering
#数据处理
# Reading the csv file
df_new = pd.read_csv('all_data.csv')
# saving xlsx file
GFG = pd.ExcelWriter('all_data.xlsx')
df_new.to_excel(GFG, index=False)
GFG.save()
file_location="all_data.xlsx"
data=xr.open_workbook(file_location)
sheet = data.sheet_by_index(0)
#形成数据矩阵
lie=sheet.ncols
hang=sheet.nrows
stats = [[sheet.cell_value(c,r) for c in range(1,sheet.nrows)] for r in range(1,sheet.ncols)]#得到所有行列值
stats = pd.DataFrame(stats)
#输出聚类过程
stats_frame=pd.DataFrame(stats)
normalizer=preprocessing.scale(stats_frame)
stats_frame_nomalized=pd.DataFrame(normalizer)
print(stats_frame)
print(stats_frame_nomalized)
#输出数据矩阵结果
print("_____________")
import numpy as np
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram
from scipy.cluster.hierarchy import linkage, dendrogram
#z=linkage(stats,"average",metric='euclidean',optimal_ordering=True)
#print(z)
#print("_____________")
## average=类平均法,ward=离差平方和法,sin=最短距离法,com=最长距离法,med=中间距离法,cen=重心法,fle=可变类平均法
#fig, ax = plt.subplots(figsize=(20,20))
#dendrogram(z, leaf_font_size=1) #画图
##plt.axhline(y=4) #画一条分类线
##plt.show()
##可视化输出
print(stats)
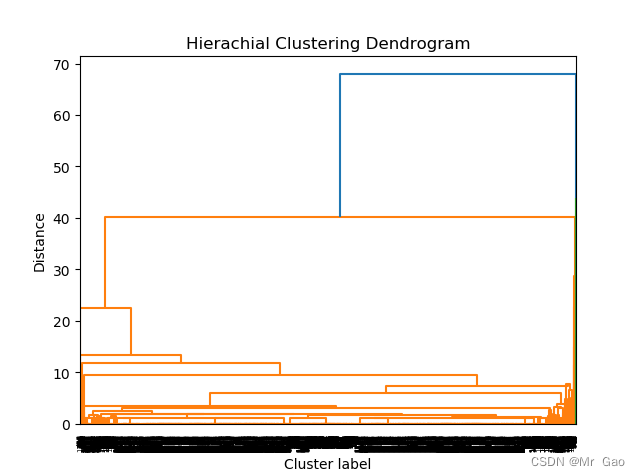
Z = linkage(stats, method='median', metric='euclidean')
p = dendrogram(Z, 0)
plt.title("Hierachial Clustering Dendrogram")
plt.xlabel("Cluster label")
plt.ylabel("Distance")
plt.show()
cluster = AgglomerativeClustering(n_clusters=3, affinity='euclidean', linkage='average')
#linkage模式可以调整,n_cluser可以调整
print(cluster.fit_predict(stats))
for i in cluster.fit_predict(stats):
print(i, end=",")
plt.figure(figsize=(10, 7))
plt.scatter(stats_frame[0],stats_frame[1], c=cluster.labels_)
plt.show()
#保存结果
# print(final_dict)
cnt = 0
res = cluster.fit_predict(stats)
final_item = final_dict.items()
# print(final_item)
for i in final_item:
i[1].append(res[cnt])
cnt += 1
# print(final_dict)
pd.DataFrame(data = final_dict).to_csv('result_hierarchicalClustering.csv', encoding = 'utf-8')
import numpy as np
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
colo = ['b', 'g', 'r', 'c', 'm', 'y', 'k']
# print(x)
x = []
for i in final_dict_cpy.items():
x.append(i[1])
# print(x)
x = np.array(x)
fig = plt.figure(figsize=(12, 8))
ax = Axes3D(fig, elev=30, azim=20)
shape = x.shape
sse = []
score = []
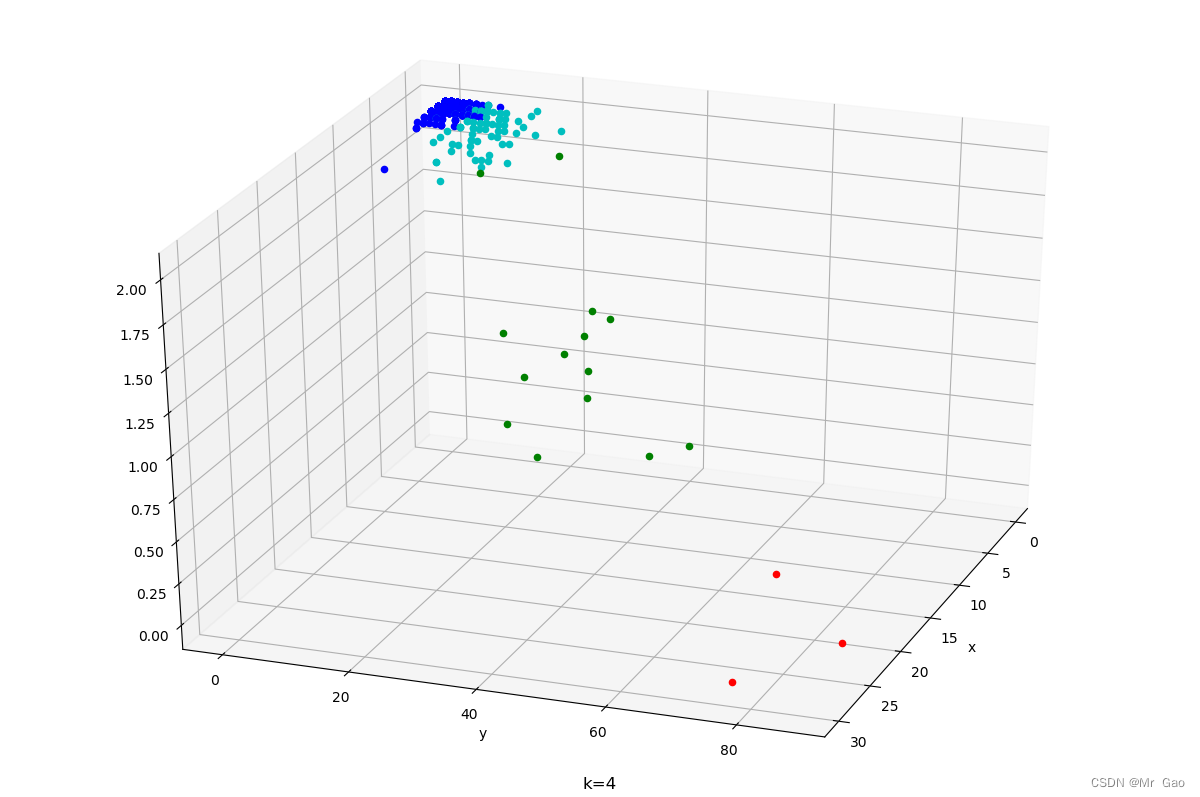
K = 4 # 分为K类
for k in [K]:
clf = KMeans(n_clusters=k)
clf.fit(x)
sse.append(clf.inertia_)
lab = clf.fit_predict(x)
score.append(silhouette_score(x, clf.labels_, metric='euclidean'))
for i in range(shape[0]):
plt.xlabel('x')
plt.ylabel('y')
plt.title('k=' + str(k))
ax.scatter(x[i, 0],x[i, 1], x[i, -1], c=colo[lab[i]])
plt.show()
# 保存结果
cnt = 0
res = clf.fit_predict(x)
final_item = final_dict_cpy.items()
for i in final_item:
i[1].append(res[cnt])
cnt += 1
pd.DataFrame(data = final_dict_cpy).to_csv('result_k-means.csv', encoding = 'utf-8')
运行结果如下:
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









