







我只是知识的搬运工,偶尔夹带个人的总结和理解。把网上总结比较好的文章集合在一起,方便大家学习。
1.Fliter(过滤器)包含卷积核,通道数与Fliter个数有关。
如何理解卷积神经网络中的通道(channel)_神经网络通道数-CSDN博客
2.视觉注意力机制:
视觉注意力机制其实就是对CNN得到的特征图进行权重分配的操作,增大感兴趣区域的权重,抑制其他区域,从而使得视觉任务有更好的效果,因为卷积操作相当于减少参数量和计算量,如果想要获得更好的效果,添加注意力机制改进视觉任务的效果是一个不错的解决方案之一。
(1)SE视觉注意力(通道注意力): 来自于论文《Squeeze-and-Excitation Networks》
(2)CBAM注意力:CBAM模块同时用到了通道注意力和空间注意力,来自于论文《CBAM: Convolutional Block Attention Module》
(3)视觉自注意力 — Non Local:来自于论文《Non-local Neural Networks》
(4)GCNet:对视觉自注意力Non Local的改进,论文《GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond》
3.训练的超参数(batch_size和learning rate):batch_size比较大时,在显存足够的情况下,训练一个epoch的时间会比batch_size小的快,但是收敛速度可能会慢一些,需要迭代更多次,在训练达到相同loss的情况下,可能比batch_size小的更慢。注意:并不是说batch_size越小越好或者越大越好,batch_size小还有可能一直不收敛咧,所以batch_size会有一个最优值。batch_size和学习率是可以搭配用到,batch_size越大,梯度下降的方向会越准确,但是会稍微平和,梯度下降比较慢,收敛速度慢,所以可以搭配大一点的学习率,加快其收敛速度;相反,batch_size比较小,梯度可能变化会比较剧烈一些,因此可以搭配比较小的学习率,让参数更新稍微缓和一点,避免错过最优的权重参数。
4.1*1卷积核的作用:改变通道数(可以增加也可以减少);可以看作是全连接层(可以增加非线性);
5.python argparse模块:提供了一个和用户交互的内置模块 ,我们在进行深度学习训练时,很多的参数需要设置,比如batch_size,learning rate,数据集位置等等,所以通过这个模块可以将我们在运行代码时,输入训练或推理的参数。
6.数据标准化和归一化:这两种其实是数据特征缩放的方法,是数据预处理的关键步骤。因为不同评价指标往往具有不同的量纲和量纲单位,可以试想一下这个式子:,A和B是权重系数(A+B=1),即使给B的值0.99,但由于
对y的影响起到的作用很小,所以往往会忽略掉
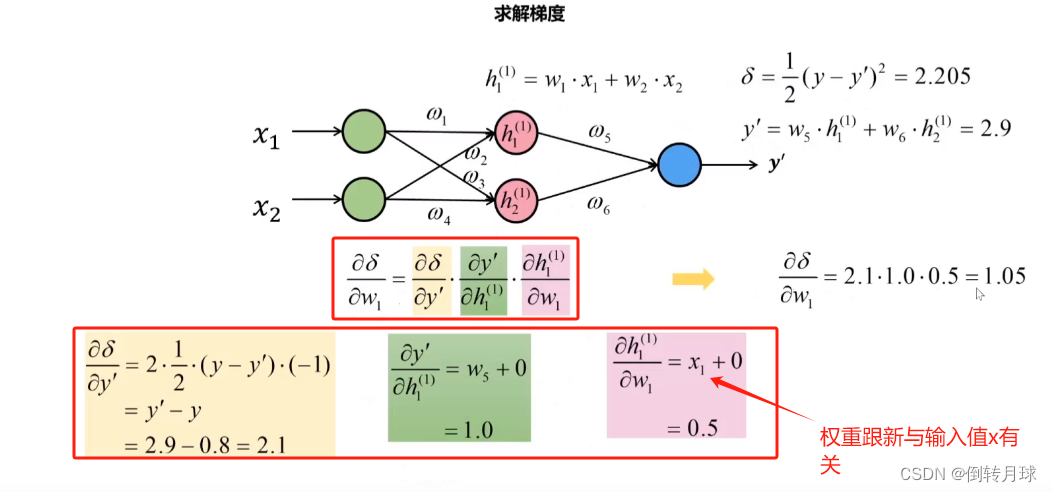
。为了消除指标之间的量纲影响,需要进行数据归一化/标准化处理,以解决数据指标之间的可比性。原始数据经过数据归一化/标准化处理后,各指标处于同一数量级,适合进行综合对比评价。归一化:将数据映射到指定的范围,如:把数据映射到0~1或-1~1的范围之内处理。标准化:将原数据转换为符合均值为0,标准差为1的标准正态分布的新数据。在深度学习领域上,可以结合反向传播,可以分析到归一化和标准化的作用,避免了梯度爆炸和加快收敛速度,因为反向传播需要链式求导,一般的深度学习网络有很多层,因此链式求导往往是十几项累乘,而且如果不做数据归一化和标准化,那么会与很大的x相乘,得到的数将会很大,不利于收敛和容易梯度爆炸。如图分析:对
的更新与
有关,那如果网络深度十几层,即需要累乘十几项,若每一项都大于1,并且
没做归一化,数值到达10000,那乘出来的数即使乘上一个学习率很小的数,数值也会很大,对权重的更新也会一下子很大,容易错过最佳值。
7.批归一化(Batch Normalization)、组归一化(Group Normalization)归一化。批归一化对batch_size要求比较敏感,较大和较小的batch_size都会对训练过程有影响,组归一化适合较小的batch_size。
8.协方差对深度学习的作用是什么?Internal Convariate Shift (内部协变量漂移)?

















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









