Count to everything
1.代码的讲解
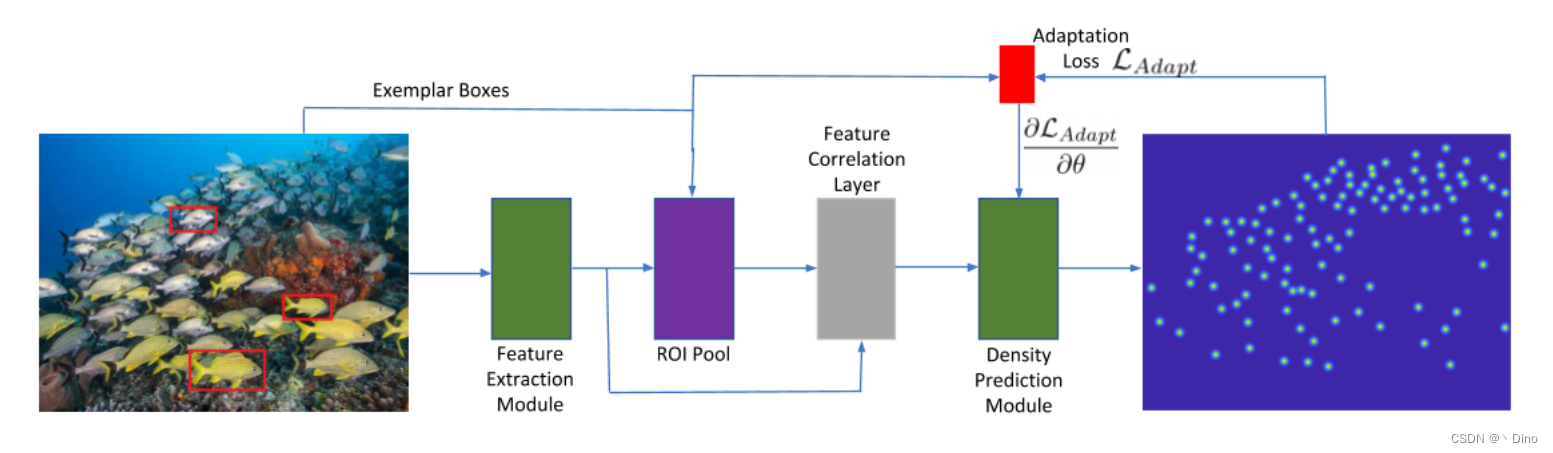
1.backbone:Resnet50FPN
通过resnet 网络提取特征 feat ,使用 map3, map4 两层。
class Resnet50FPN(nn.Module):
def __init__(self):
super(Resnet50FPN, self).__init__()
self.resnet = torchvision.models.resnet50(pretrained=True)
children = list(self.resnet.children())
self.conv1 = nn.Sequential(*children[:4])
self.conv2 = children[4]
self.conv3 = children[5]
self.conv4 = children[6]
def forward(self, im_data):
feat = OrderedDict()
feat_map = self.conv1(im_data)
feat_map = self.conv2(feat_map)
feat_map3 = self.conv3(feat_map)
feat_map4 = self.conv4(feat_map3)
feat['map3'] = feat_map3
feat['map4'] = feat_map4
return feat
2.巧妙利用“卷积核”进行特征提取
1.将三个特征框进行resize 相同的框
image,lines_boxes,density = sample['image'], sample['lines_boxes'],sample['gt_density']
W, H = image.size
if W > self.max_hw or H > self.max_hw:
scale_factor = float(self.max_hw)/ max(H, W)
new_H = 8*int(H*scale_factor/8)
new_W = 8*int(W*scale_factor/8)
resized_image = transforms.Resize((new_H, new_W))(image)
resized_density = cv2.resize(density, (new_W, new_H))
orig_count = np.sum(density)
new_count = np.sum(resized_density)
if new_count > 0: resized_density = resized_density * (orig_count / new_count)
else:
scale_factor = 1
resized_image = image
resized_density = density
boxes = list()
for box in lines_boxes:
box2 = [int(k*scale_factor) for k in box]
y1, x1, y2, x2 = box2[0], box2[1], box2[2], box2[3]
boxes.append([0, y1,x1,y2,x2])
boxes = torch.Tensor(boxes).unsqueeze(0)
resized_image = Normalize(resized_image)
resized_density = torch.from_numpy(resized_density).unsqueeze(0).unsqueeze(0)
sample = {'image':resized_image,'boxes':boxes,'gt_density':resized_density}
return sample
2.利用三个特征框当作“卷积核”进行特征提取
def extract_features(feature_model, image, boxes,feat_map_keys=['map3','map4'], exemplar_scales=[0.9, 1.1]):
N, M = image.shape[0], boxes.shape[2]
"""
Getting features for the image N * C * H * W
"""
Image_features = feature_model(image)
"""
Getting features for the examples (N*M) * C * h * w
"""
for ix in range(0,N):
boxes = boxes[ix][0]
cnter = 0
Cnter1 = 0
for keys in feat_map_keys:
image_features = Image_features[keys][ix].unsqueeze(0)
if keys == 'map1' or keys == 'map2':
Scaling = 4.0
elif keys == 'map3':
Scaling = 8.0
elif keys == 'map4':
Scaling = 16.0
else:
Scaling = 32.0
boxes_scaled = boxes / Scaling
boxes_scaled[:, 1:3] = torch.floor(boxes_scaled[:, 1:3])
boxes_scaled[:, 3:5] = torch.ceil(boxes_scaled[:, 3:5])
boxes_scaled[:, 3:5] = boxes_scaled[:, 3:5] + 1
feat_h, feat_w = image_features.shape[-2], image_features.shape[-1]
boxes_scaled[:, 1:3] = torch.clamp_min(boxes_scaled[:, 1:3], 0)
boxes_scaled[:, 3] = torch.clamp_max(boxes_scaled[:, 3], feat_h)
boxes_scaled[:, 4] = torch.clamp_max(boxes_scaled[:, 4], feat_w)
box_hs = boxes_scaled[:, 3] - boxes_scaled[:, 1]
box_ws = boxes_scaled[:, 4] - boxes_scaled[:, 2]
max_h = math.ceil(max(box_hs))
max_w = math.ceil(max(box_ws))
for j in range(0,M):
y1, x1 = int(boxes_scaled[j,1]), int(boxes_scaled[j,2])
y2, x2 = int(boxes_scaled[j,3]), int(boxes_scaled[j,4])
if j == 0:
examples_features = image_features[:,:,y1:y2, x1:x2]
if examples_features.shape[2] != max_h or examples_features.shape[3] != max_w:
examples_features = F.interpolate(examples_features, size=(max_h,max_w),mode='bilinear')
else:
feat = image_features[:,:,y1:y2, x1:x2]
if feat.shape[2] != max_h or feat.shape[3] != max_w:
feat = F.interpolate(feat, size=(max_h,max_w),mode='bilinear')
examples_features = torch.cat((examples_features,feat),dim=0)
"""
Convolving example features over image features
"""
h, w = examples_features.shape[2], examples_features.shape[3]
features = F.conv2d(
F.pad(image_features, ((int(w/2)), int((w-1)/2), int(h/2), int((h-1)/2))),
examples_features
)
combined = features.permute([1,0,2,3])
for scale in exemplar_scales:
h1 = math.ceil(h * scale)
w1 = math.ceil(w * scale)
if h1 < 1:
h1 = h
if w1 < 1:
w1 = w
examples_features_scaled = F.interpolate(examples_features, size=(h1,w1),mode='bilinear')
features_scaled = F.conv2d(F.pad(image_features, ((int(w1/2)), int((w1-1)/2), int(h1/2), int((h1-1)/2))),
examples_features_scaled)
features_scaled = features_scaled.permute([1,0,2,3])
combined = torch.cat((combined,features_scaled),dim=1)
if cnter == 0:
Combined = 1.0 * combined
else:
if Combined.shape[2] != combined.shape[2] or Combined.shape[3] != combined.shape[3]:
combined = F.interpolate(combined, size=(Combined.shape[2],Combined.shape[3]),mode='bilinear')
Combined = torch.cat((Combined,combined),dim=1)
cnter += 1
if ix == 0:
All_feat = 1.0 * Combined.unsqueeze(0)
else:
All_feat = torch.cat((All_feat,Combined.unsqueeze(0)),dim=0)
return All_feat
3.使用卷积进行预测数量
class CountRegressor(nn.Module):
def __init__(self, input_channels,pool='mean'):
super(CountRegressor, self).__init__()
self.pool = pool
self.regressor = nn.Sequential(
nn.Conv2d(input_channels, 196, 7, padding=3),
nn.ReLU(),
nn.UpsamplingBilinear2d(scale_factor=2),
nn.Conv2d(196, 128, 5, padding=2),
nn.ReLU(),
nn.UpsamplingBilinear2d(scale_factor=2),
nn.Conv2d(128, 64, 3, padding=1),
nn.ReLU(),
nn.UpsamplingBilinear2d(scale_factor=2),
nn.Conv2d(64, 32, 1),
nn.ReLU(),
nn.Conv2d(32, 1, 1),
nn.ReLU(),
)
def forward(self, im):
num_sample = im.shape[0]
if num_sample == 1:
output = self.regressor(im.squeeze(0))
if self.pool == 'mean':
output = torch.mean(output, dim=(0),keepdim=True)
return output
elif self.pool == 'max':
output, _ = torch.max(output, 0,keepdim=True)
return output
else:
for i in range(0,num_sample):
output = self.regressor(im[i])
if self.pool == 'mean':
output = torch.mean(output, dim=(0),keepdim=True)
elif self.pool == 'max':
output, _ = torch.max(output, 0,keepdim=True)
if i == 0:
Output = output
else:
Output = torch.cat((Output,output),dim=0)
return Output
2.总结
1.很巧妙的利用所标记的框,当作卷积核 进行特征提取
2.使用卷积操作进行回归预测总体数量
3.但是存在很多不足的地方,如果🐟的方向或者说物体的方向不一样,预测可能就有很大误差。























 8896
8896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









