









前言
谁是中国首富?这是每年胡润富豪榜发出时大家最关心的话题。但只关注第一位就太未免浪费这份榜单的价值了,事实上这份榜单能挖掘到的信息很多,比如:
- 哪些行业创造财富的能力最强
- 这些大佬的年龄又集中在哪些区间
- 哪些人资产进步最大
本文将从数据获取、数据清洗、数据可视化入手,实现一整套完整的数据分析流程
目标网站:https://www.hurun.net/zh-CN/Rank/HsRankDetails?pagetype=rich

本文数据代码可以在公众号 “数据分析与商业实践” 后台回复「胡润」获取,PS:这是一个零基础入门 python 一个半月并与我联系紧密的读者的来稿,非常励志!
数据获取
初步来看,我们能获得什么信息?
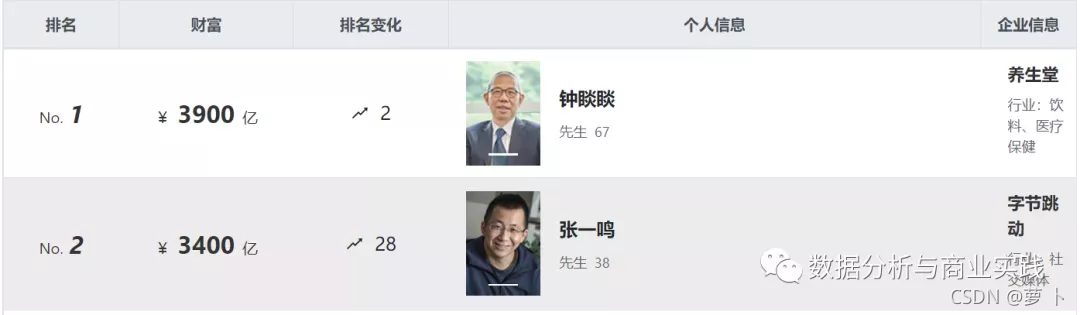
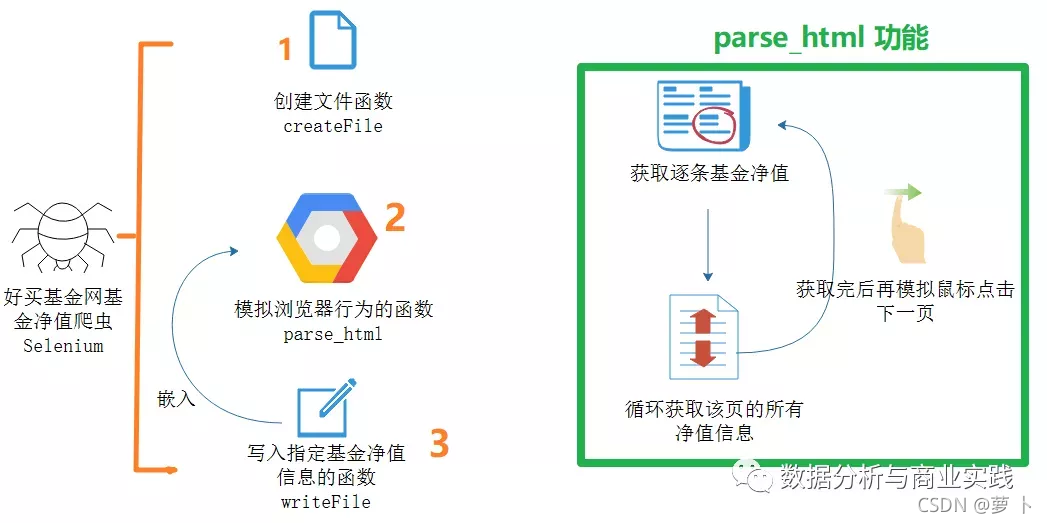
非常直观,这里给出了每位企业家的排名,目前的财富金额,以及对比上次上榜时的排名变化,在个人信息里还展示了性别和年龄,企业信息里展示了旗下公司和行业的信息。为了锻炼能力,我们使用爬虫的 Selenium 自动化测试框架来完成数据获取。代码思路与以往的推文 “技术指导投资:Selenium好买基金网净值爬虫分析” 非常类似,所包含的函数及其功能都可以完全套用(源代码放在后台)。
最后我们就得到了下面这份非常原生的数据。(仅展示10行)
有了这份数据我们能开始数据分析吗?
事实上可以,只要你能忍的了数据中有可能存在的乱码,这性别和年龄杂糅在一起的粗犷感,以及随时有可能出错的数据类型等等的问题。那么进行数据清洗就成为必要的工作了,使得我们经过清洗后能够得到一张干净清爽并且适用性非常高的新表。
我们需要做什么工作?
实际上数据清洗并不复杂,首先通过数据探查发现我们原来的表的一些问题,然后通过一系列的操作把这些问题解决,最后导出就行了。以下是整体的流程,跟着后台代码过一遍,相当于又对 Pandas 常见又经典的数据处理操作复习了一遍。
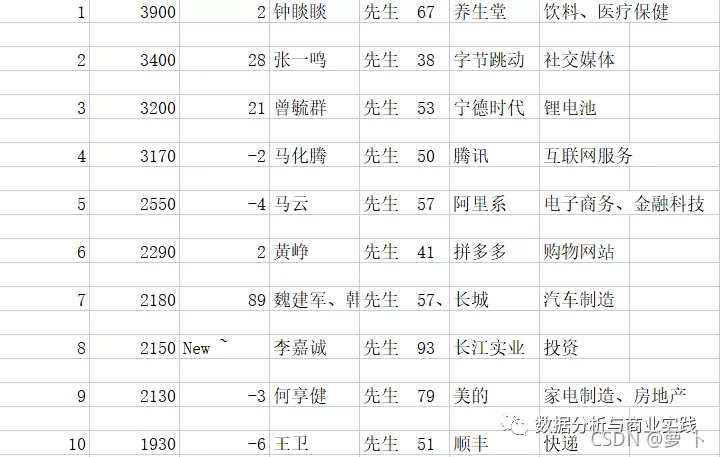
通过数据清洗工作我们就得到了下面这份新的数据表
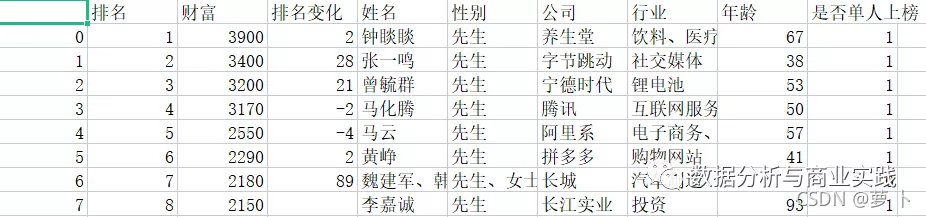
实际上我们还分别导出了多人上榜的数据和单人上榜的数据,这里不予展示。对比上面那张原生的数据表,不得不说这份数据看起来就顺眼的多,不仅如此它还解决了很多问题,为什么这样说?
- 首先富豪姓名列中其实是有组合上榜的,那么如何生成其对应的年龄就成了个问题。
- 其次,对于一些无效的和空的字符干扰,以及字段属性的错误都进行了合适的修正。
可视化
经过上面的一系列努力那么我们终于可以开始我们的可视化分析部分了,关于可视化的代码感兴趣的同学也可以在后台获取,这里仅展示可视化结果。对于排名的话,我们可以来看一下哪些人排名比较靠前。
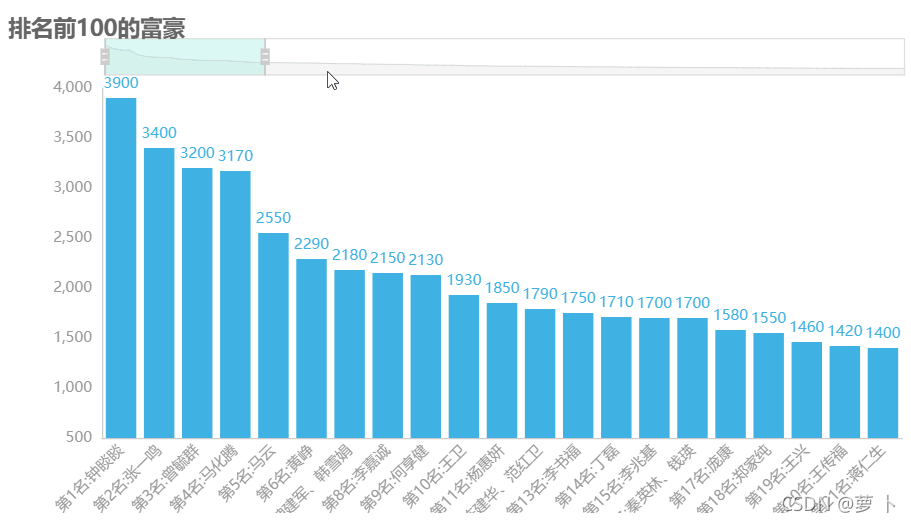
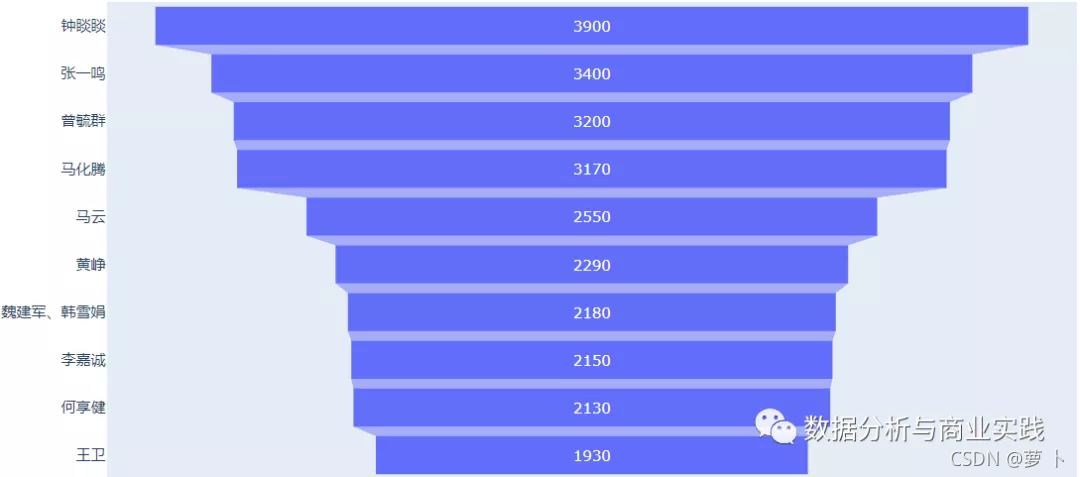
注意哦,这里的数字单位是亿元,默默看了下我的支付宝余额,不得不说人与人之间的差距真大。
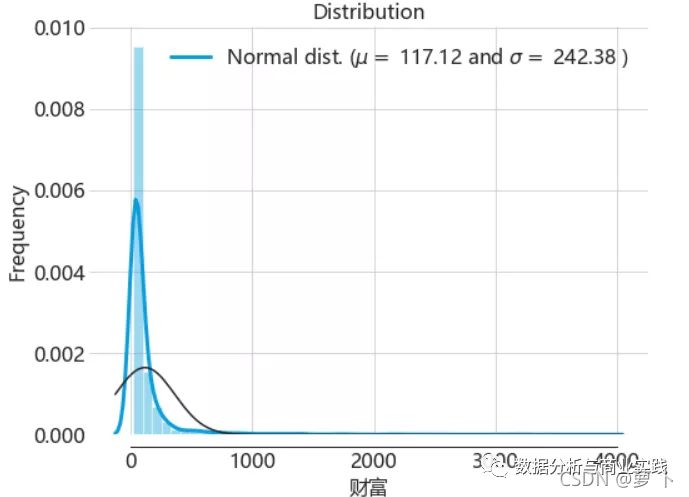
再来看看财富的分布图,可以看出财富大多集中在20亿到500亿这个区间。
财富与年龄的气泡图
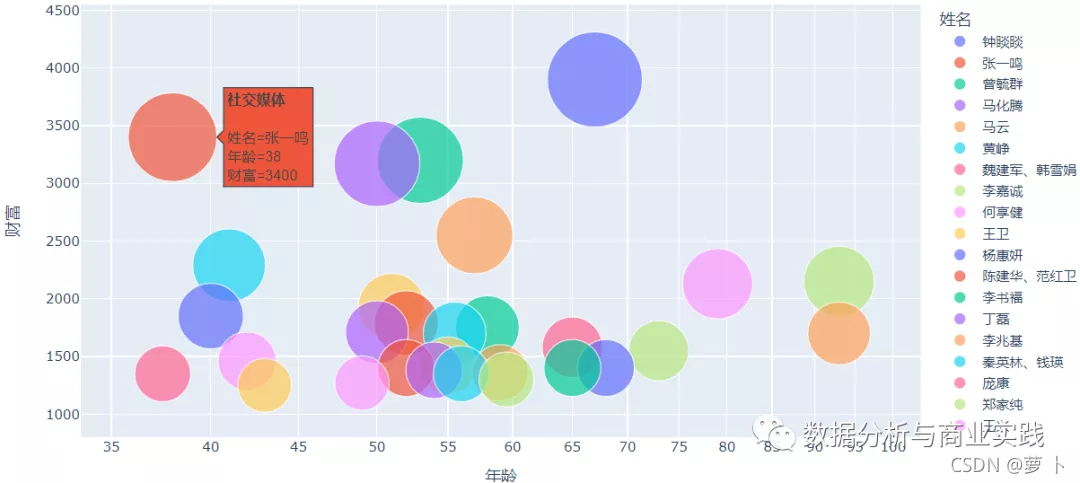
看的出来字节跳动的老板是又年轻又有钱。
我们再来看看排名的变化情况
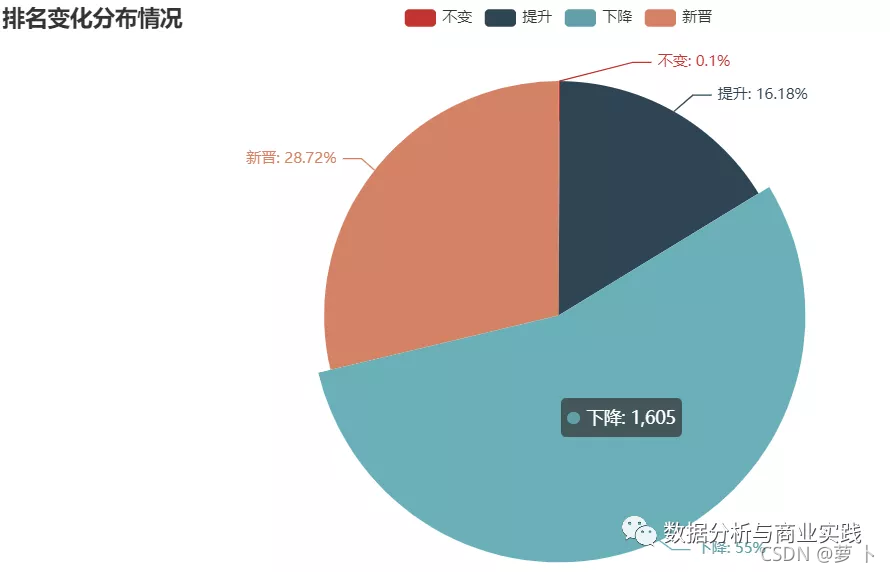
排名下降的人最多,然后新晋的富豪也不少,提升的就相对来说比较少啦,看样子在富豪榜上也是一件逆水行舟不进则退的事情。当然我们可以找出哪些人进步最大,以及哪些人下滑最多。
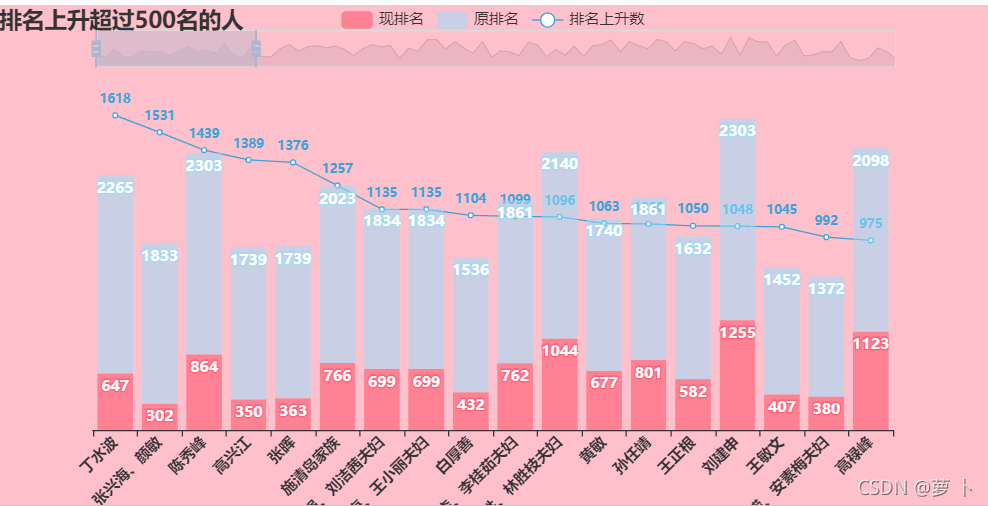
排名上升超过500名的人
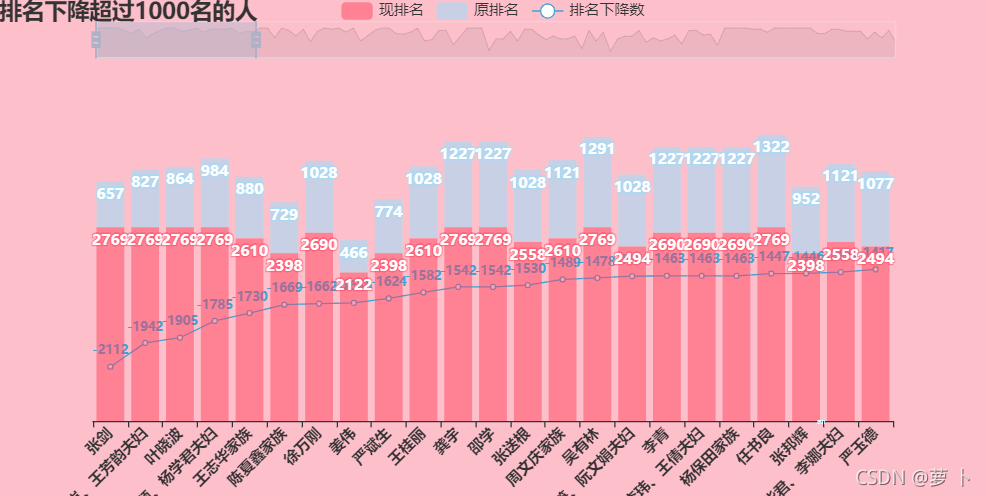
排名下降超过1000名的人
对于性别和年龄,我们可以看看在哪些年龄段富豪比较扎堆呢,以及性别的比例,下面是不同年龄阶段的富豪男女比例。
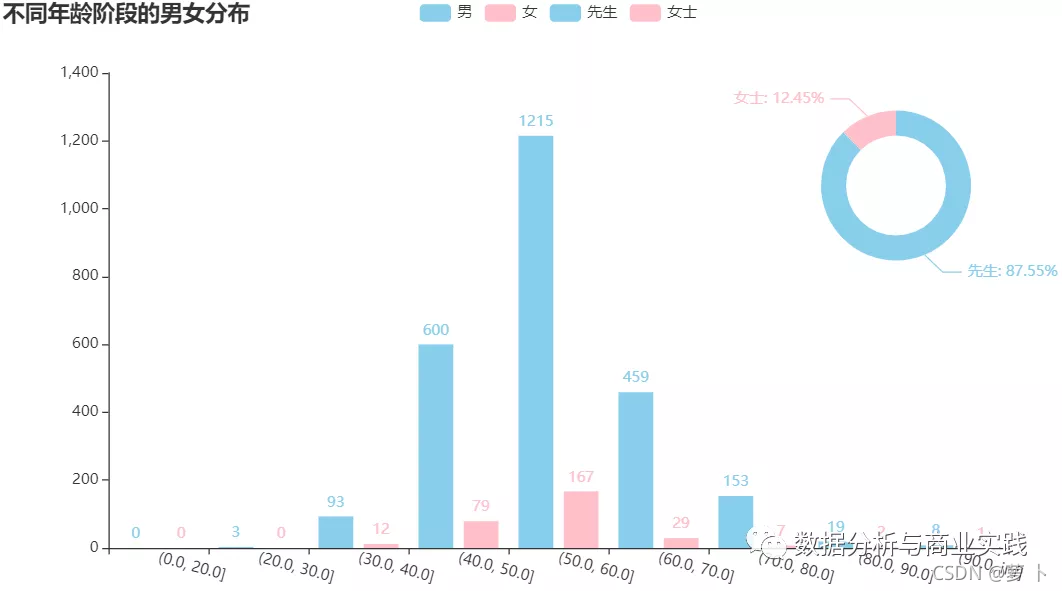
男女比例接近九比一了,此外富豪年龄大多集中在50岁到60岁这个区间。
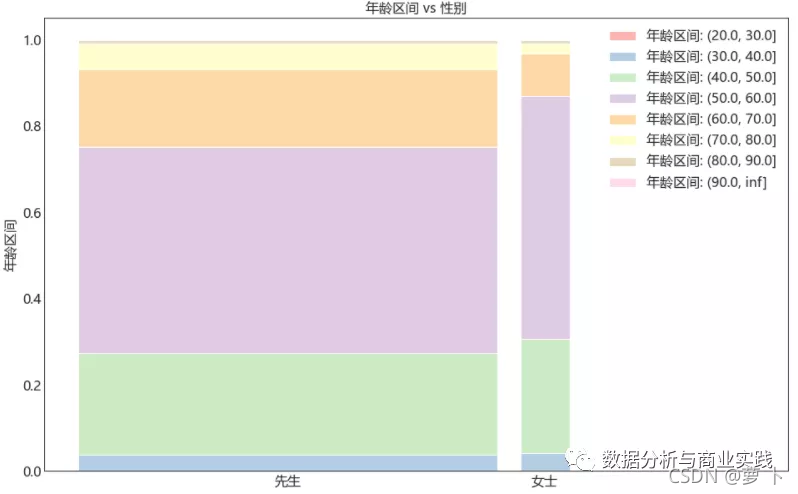
从性别与年龄的关系堆叠图中,也能看出来富豪男女比例的失衡,以及中老年化的总体趋势。(柱子宽度表示数据量大小)
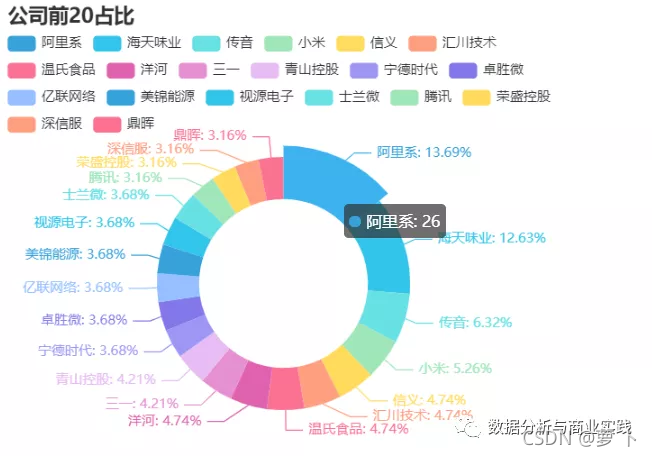
当然对于很多人来说,关心的也许是哪些行业和公司是最赚钱,创造财富是最多的呢,毕竟男怕入错行,女怕嫁错郎。
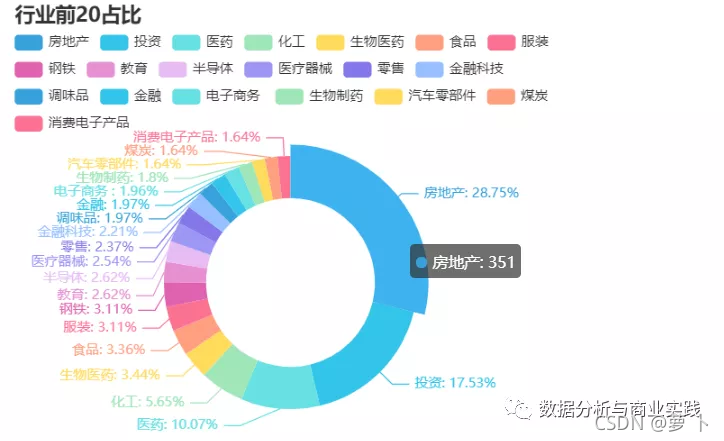
整体看,还是搞房地产的富豪最多,中国的房价上涨有他们一份责任。
下面是我生成的词云,可以看看这些有钱人大多是哪些姓氏,以及哪些姓氏的资产最多。首先以姓氏在榜单上的频率来生成词云。

李王张陈刘,这些姓氏中富豪是最多的,可能有的同学会说,我小马哥呢?现在再以资产额度作为权重来生成词云。

姓李的还是最有钱的,同时由于二马两位大佬,马这个姓氏也变得突出了。
分析到这里有点乏了,当然数据的价值是无穷无尽的,能做出来的东西不止我上面所展示的,能给读者带来启发是我莫大的荣幸。
本人的第一次投稿,同时也很感谢萝卜大佬在我学习路上的帮助和支持!!
本文数据代码可以在公众号 “数据分析与商业实践” 后台回复「胡润」获取,PS:这是一个零基础入门 python 一个半月并与我联系紧密的读者的来稿,非常励志

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









