






业务背景
信贷资产质量监控中,Vintage 分析犹如风险管理的"体检表和时光望远镜",能够透过时间维度观察不同放款批次的生命周期表现(成熟期、变化规律等)。本文力求以通俗简洁的文风来介绍 Vintage 分析的概念、计算逻辑和业务应用,希望能对大家有所帮助。
目录
Part 1. 什么是 Vintage 分析?
Part 2. Vintage 分析的意义
Part 3. 脱敏数据解读
Part 4. Python 构建 Vintage 分析表
Part 5. 延展 & 注意事项
参考资料
版权声明
本文含7000字,建议阅读 8~12 分钟
Part 1.什么是 Vintage 分析
同期群分析(Cohort Analysis),是一种上到互联网巨头做用户行为分析,下到地铁口出摊卖炒粉的阿姨阿叔,都能用到的接地气分析思路。
其核心是将用户按初始行为的发生时间划分为不同群组,追踪群体行为的长期演变规律。而 Vintage分析 则是同期群分析在金融风控领域的垂直应用,聚焦于资产质量与风险表现的动态评估。
先来看同期群分析的表现形式:
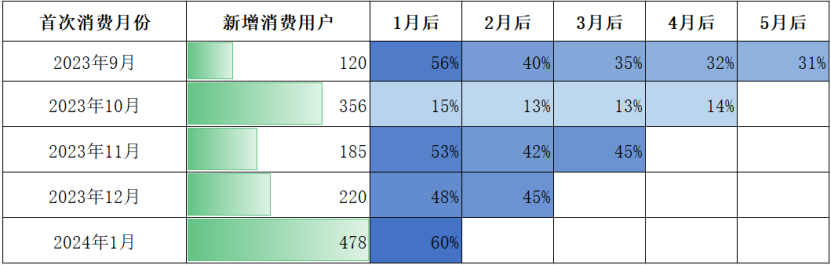
数据来源于笔者朋友在广东开的一家火锅烧烤餐厅,我把他每个月门店的新增客户数据进行记录,并统计他们在之后几个月份的再次光顾的情况:
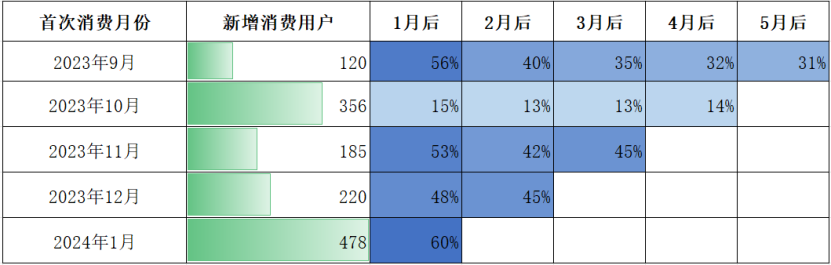
- 横向上看:可以知晓每个月的新增客户在其之后月份的留存情况。2023 年 9、11、12 月消费的用户,第二个月再次消费的概率在 50% 左右,随后依次递减,最终稳定在30%~35%。
- 纵向上看:可以对比不同月份的新增和留存情况。2023 年 10 月和 2024 年 1 月的新增购买用户数成倍增长(分别由上个月的 120 涨到 356、220 涨到 478),但与此同时,2023 年 10 月之后的留存率直线下滑,只有15%。
再来看金融风控的垂直应用(Vintage):

数据来源于某银行 2024 年3月-9月的放款资产池,统计各批次贷款在放款后 1-10 个月内逾期>30天的金额占比:
- 横向规律:各月放款资产在前2个月逾期率均低于0.2%,从第3个月开始逐步爬升,峰值多出现在6-8个月后(如2024-03批次:7月后达1.91%)。
- 纵向上看:2024-03 批次的逾期率在7月后突破1.9%,显著高于其他批次同期水平(如2024-04批次7月后仅0.85%)。2024-09 批次虽仅有5个月数据,但5月后逾期率已达1.33%,远超历史同期(如2024-05批次5月后为0.30%)
Part 2.Vintage 分析的意义
仅知晓每个月用户行为的笼统数字(新增用户 or 放贷行为),对于拉长时间线去观察生命周期绝对是一头雾水,更别提识别早期风险信号或挖掘长期价值。
回到笔者朋友开的餐厅的新增用户同期群分析图:
追溯横纵向波动较大的月份背后的数据进一步探索后,发现
- 季节调整影响:2023年12月因主推火锅(广东入冬较晚),新增用户小幅上涨,留存未受显著波动。
- 促销副作用:2023年10月(中秋国庆5.5折线上套餐)与2024年1月(春节旺季)新增用户激增2~3倍(如10月:120→356),但次月留存率暴跌至15%(常规留存一般 45%~56%);而且促销用户价值低:10月新增356人中仅53人复购,反而低于9月自然新增的67人复购(120×56%)。
- 节假日的特殊性:2024年1月新增 478 人(主推火锅+春节流量),但假期未结束时留存数据虚高,后续需继续观察。
不难发现,同期群分析使我们能够对同一用户群在未来时段的波动根源进行定位和分析(季节因素、节假日高峰),又能验证运营策略的长期有效性(新品上线,促销活动)。笔者对朋友餐厅的用户做了同期分析之后,给予的建设性意见放在 Part5 的末尾。
对应到 Vintage 分析,同样能起到深挖波动原因和验证策略的作用:

- 外部环境归因:
- 2024-03 批次逾期率居高不下(7月后 1.91%),需回溯该时段风控宽松政策或目标客群偏移(如降低准入标准)。
- 2024-09 批次早期逾期飙升(5月后1.33%),可能与同期区域失业率上升或某行业集中逾期相关。
- 内部策略验证:
- 2024-06 至 2024-08 批次在相同账龄内逾期率整体低于早期(如 6 月后:2024-03 为 0.89% vs 2024-08 为0.80%),反映收紧授信规则或模型迭代的有效性。
- 第 6-8 个月为风险集中释放期,即本来就不打算还款的贷款用户都“不装了,我摊牌了”(如2024-03批次7月后1.91%),需针对性加强贷中监控频率与催收资源投放。
当然还可以继续深挖很多其他东西,但因为涉及的业务术语和知识点较多,留着以后的文章再讲。
Part 3.脱敏数据解读
本文用到的脱敏数据集如下(2024 年 1~6 月的贷款数据,节选前 5 行):
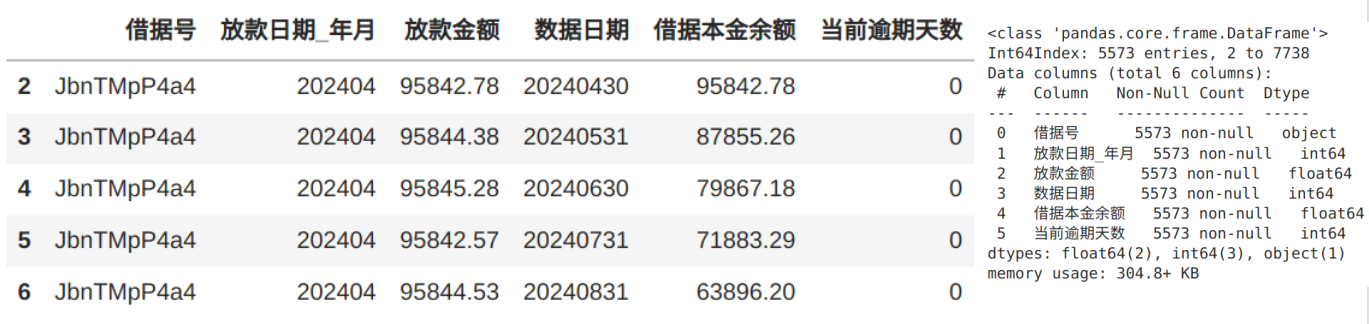
- 借据号:唯一标识每笔贷款借据的编号,用于追踪具体借款记录
- 放款日期_年月:以YYYYMM格式存储的整数(int64),表示贷款实际发放的年月时间点
- 放款金额:初始发放的贷款本金数额
- 数据日期:以YYYYMMDD格式存储的整数(int64),代表数据快照的观测时点(类似 SQL 的 load_dt 分区),用于标记当前数据状态对应的业务日期,这份数据是取每个月月底。
- 借据本金余额:截至数据日期时,借款人尚未偿还的剩余本金金额
- 当前逾期天数:数据日期对应的最新逾期状态,数值为 0 表示正常还款(或还没到应还日期),>0 的程度则反映逾期严重程度
| 关于数据日期和类型的特别说明:
- 数据日期 ≥ 放款日期:数据日期 这个字段的本质含义为产生这行数据的时间,所以必须要晚于放款时间才能观测到贷款表现。
- 日期字段均设为 int64(这一点很重要!):
① 避免复杂的日期格式转换(如字符串转 datetime 对象)
② 便于快速计算时间周期(例如:(数据日期÷100 - 放款日期_年月)可直接得到贷款存续月份数)
③ 兼容不同系统导出的原始数据格式,减少预处理步骤 当然,
实际数据肯定不止这么几列,这里只是展示常规的 Vintage 分析所需的最关键的列。
Part 4. Python 构建 Vintage 分析表
读入数据后,以防万一最好检查一下数据日期和放款日期两者的关系是否正确(数据日期 ≥ 放款日期),有误的话可能就需要联系后台人员重新取数。
import pandas as pd
import numpy as np
df = pd.read_excel('脱敏数据.xlsx')
# 查看 放款日期 和 数据日期 的范围
print("放款日期范围:", df['放款日期_年月'].min(), "~", df['放款日期_年月'].max())
print("数据日期范围:", df['数据日期'].min(), "~", df['数据日期'].max())
# 检查 放款日期 和 数据日期 的关系
if (df['数据日期']/100 >= df['放款日期_年月']).sum() == df.shape[0]:
print('数据日期均大于等于放款日期,取数正确!')
# 输出结果 ------------------------------------------------------
## 放款日期范围: 202401 ~ 202406
## 数据日期范围: 20240131 ~ 20241231
## 数据日期均大于等于放款日期,取数正确!
再来看下 Vintage 分析表的最终形式:

我们需要统计各批次贷款在放款后 n 个月内逾期>30天的金额占比。
肯定有读者会觉得,这还不简单,直接根据放款日期和数据日期来分组,再转置(打横)一下,拼起来不就完事儿了??
# Step 1:各月放款总金额
putout_month_total = df.groupby('放款日期_年月')['放款金额'].sum() \
.reset_index(name='总放款金额')
# Step 2:逾期天数 30 天以上的余额总和,按照放款年月分组
df_over_30 = df[ df['当前逾期天数']>30 ]
df_result = df_over_30.groupby(['放款日期_年月', '数据日期'])['借据本金余额'].sum()
.reset_index(name='逾期金额总和')
# Step 3:按“放款日期_年月”关联两份数据
merged_df = pd.merge(df_result, putout_month_total,
on='放款日期_年月', how='left')
merged_df['逾期金额占比'] = (merged_df['逾期金额总和'] / merged_df['总放款金额'] * 100)
.round(2).astype(str) + '%' ## 计算逾期占比,并格式化为百分比字符串(保留两位小数)
# Step 4:生成宽表
# 生成宽表,保留原始日期作为列名
pivot_df = merged_df.pivot(
index='放款日期_年月',
columns='数据日期',
values='逾期金额占比'
)
pivot_df.columns.name = None
pivot_df = pivot_df.reset_index() # 将索引转换为普通列
# 按日期升序重新排列列
date_columns = sorted([col for col in pivot_df.columns if col != '放款日期_年月'], key=lambda x: int(x))
pivot_df = pivot_df[['放款日期_年月'] + date_columns]
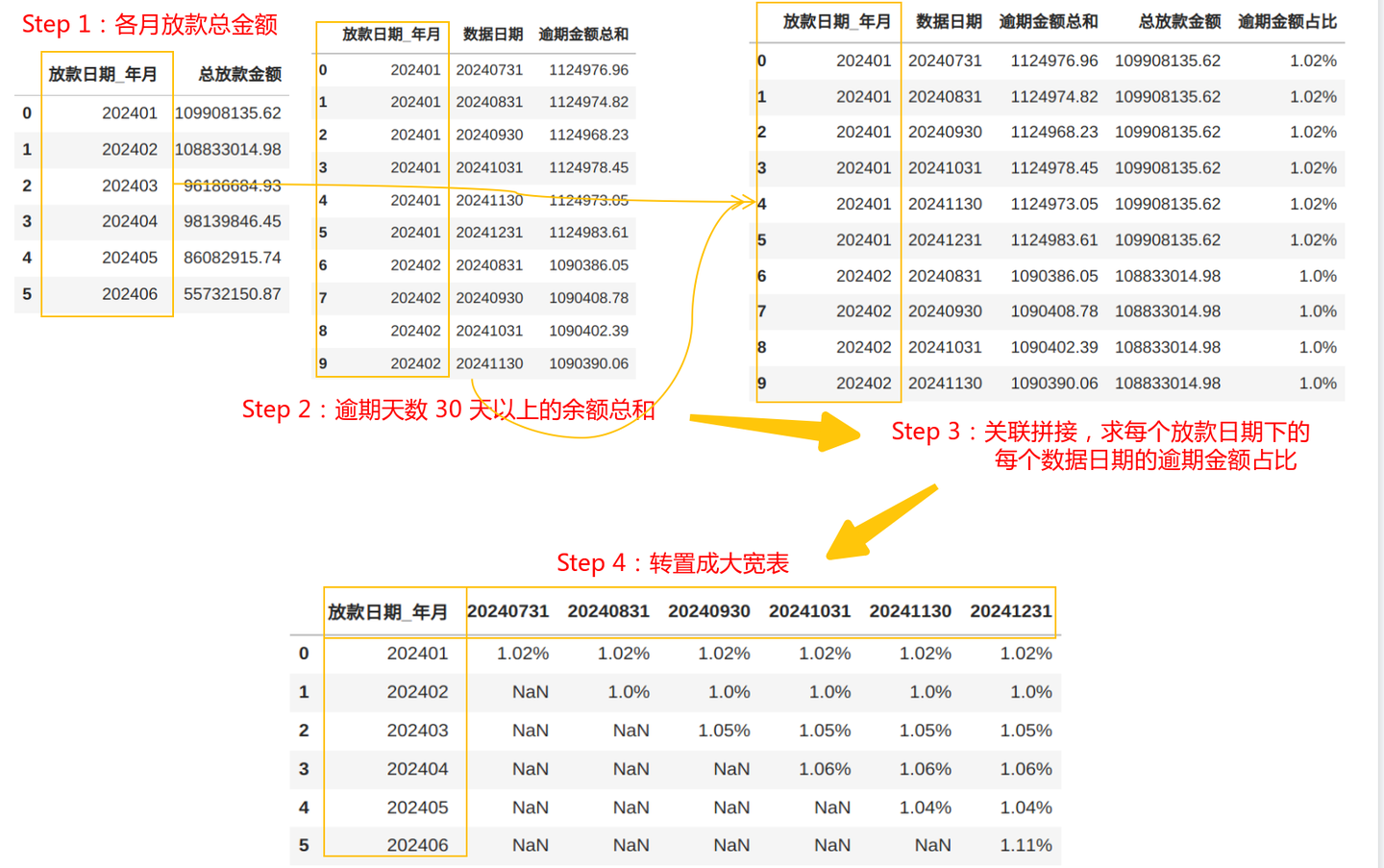
确实,使用 groupby+pivot 直接生成宽表的这种做法的确很简洁明朗,但业务可读性弱:
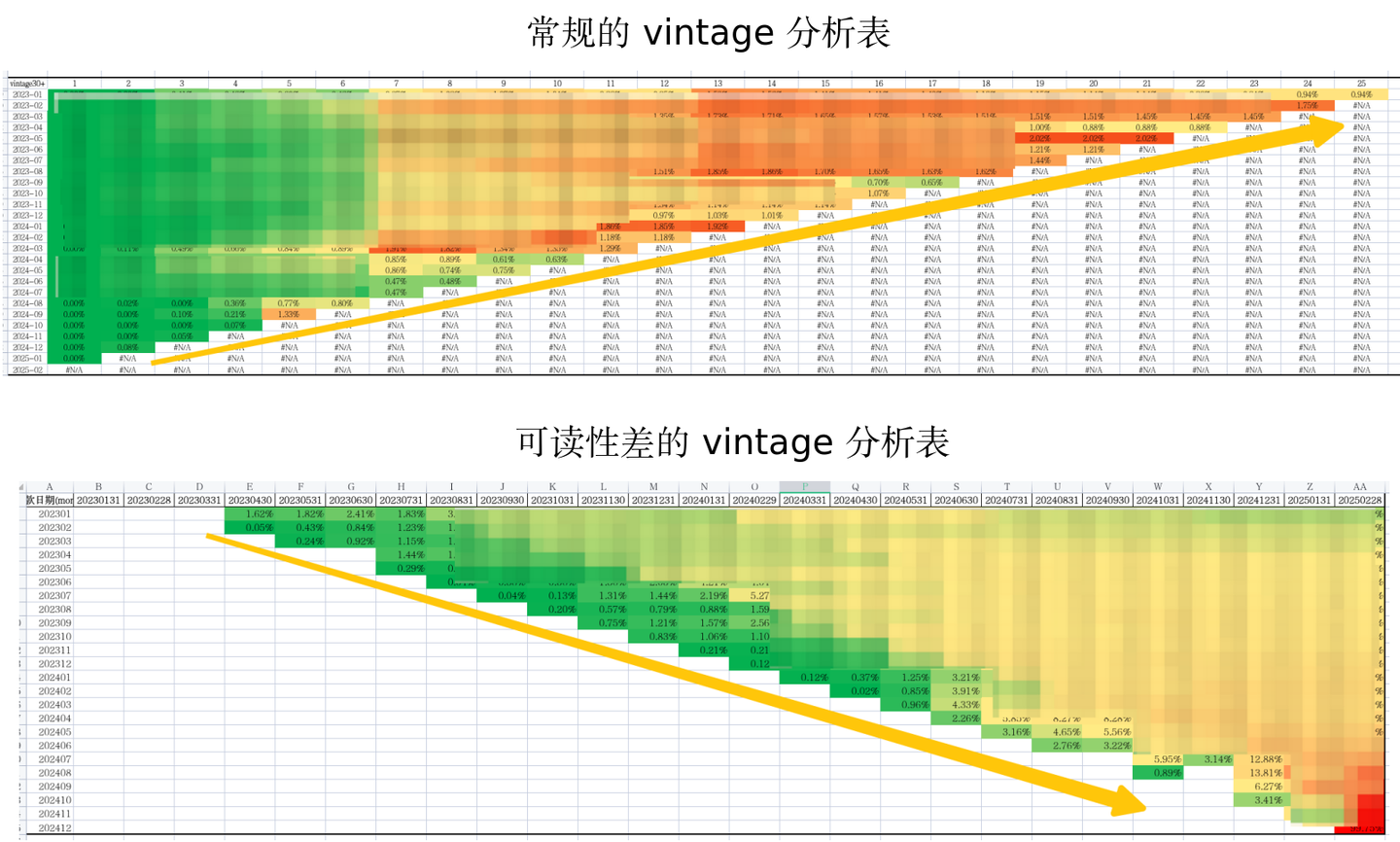
- 列名为具体日期时,需人工计算放款后的账龄月数(如 202401 放款,20240731 是第6个月),不利于直接分析账龄(如 +0月、+1月…)。而且数据量一旦大起来,比如我要追踪放款日期为 202301,数据日期为 202503 放款情况,该大宽表就会呈现类似“反向三角”的结构,可读性非常差。
- 而且未覆盖的日期显示为 NaN,需业务方二次理解(是数据未取到还是无逾期)。
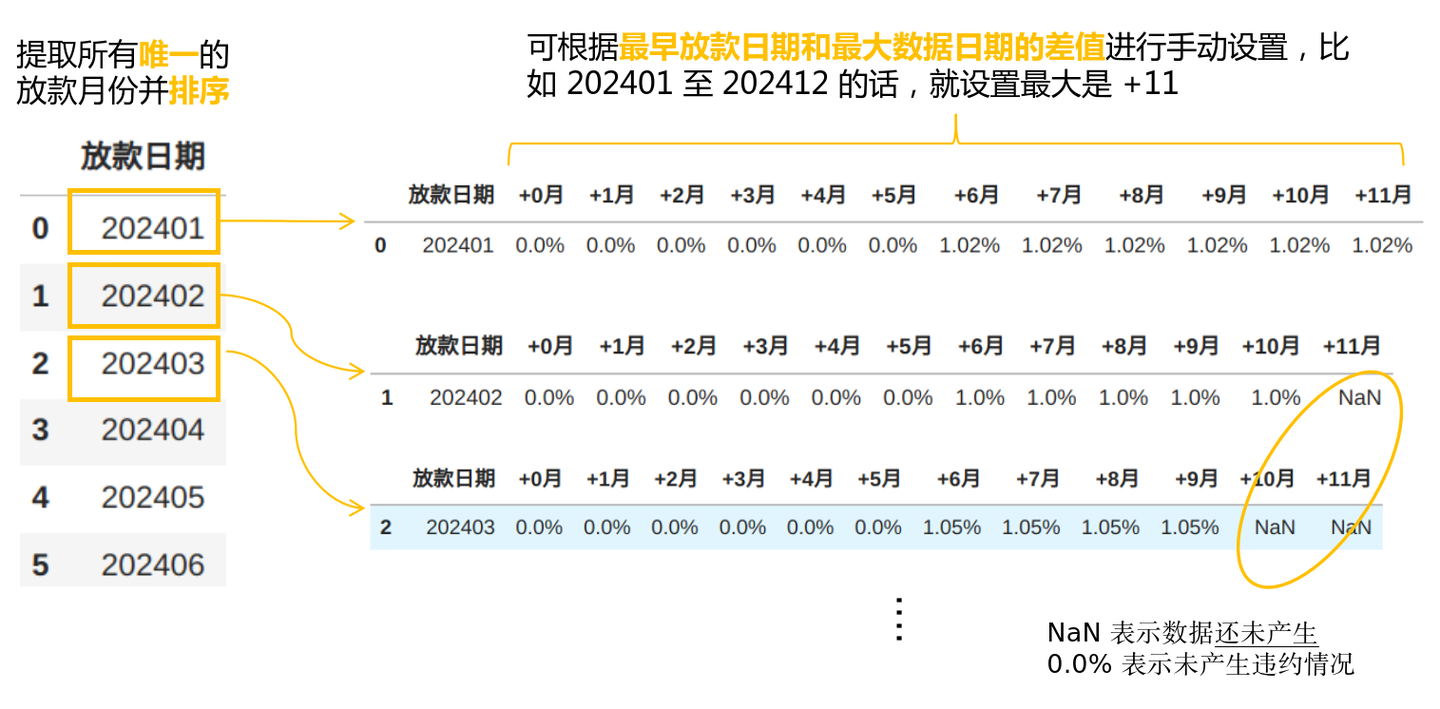
所以,我们最好能够找到一种方法,能够计算每个放款月份在不同观察窗口(0-n个月) 的逾期率金额占比。伪代码思路如下:
1. 数据准备阶段:
- 提取所有唯一的放款月份并排序 → loan_months
- 获取最大数据日期,为放款月份~最大日期之间的循环最准备
→ max_data_date(保持整数格式如20241231)
2. 结果容器初始化:
- 创建空列表 result_list 存放最终结果
3. 遍历每个放款月份:
for loan_month in loan_months:
a. 过滤数据集:
仅保留当前放款月份的数据 → df_filtered
b. 初始化结果字典(用来存储 DataFrame):
results = {}
c. 日期格式转换:
将整数年月转换为月初日期对象(如202401→2024-01-01)
4. 计算 n 个月观察窗口(可人为设置):
for 偏移量 in 0到11:
a. 计算理论观察日期:
月初 + 偏移月数 → 月末最后一天(动态计算闰年等)
转换为与原数据一致的整数格式(如2024-02-28→20240228)
b. 有效性检查:
if 理论日期 > 最大数据日期:
标记为nan(数据尚未产生)
continue
c. 计算逾期金额:
过滤同时满足两个条件的数据:
- 数据日期 == 理论日期
- 当前逾期天数 > 30天
逾期率 = 逾期本金总额 / 放款总金额 *100%
d. 结果格式化:
保留两位小数并添加%符号(如25.37%)
5. 结果汇总:
将每个放款月份的结果字典存入result_list
最终转换为二维表格 → pd.DataFrame
觉得上面这段伪代码复杂的话,也可以用看下面这张图来辅助理解:
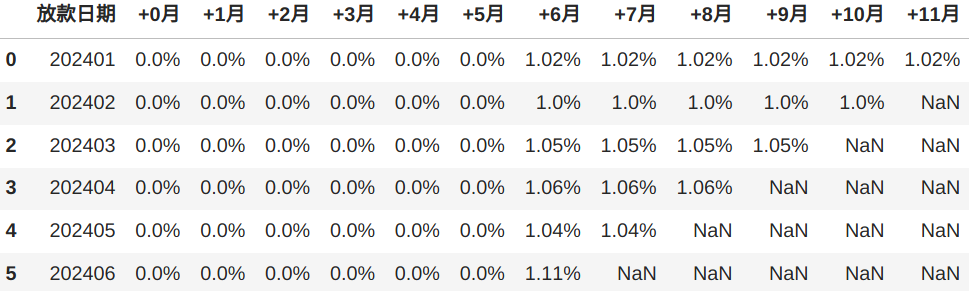
完整代码和结果如下:
loan_months = sorted(df['放款日期_年月'].unique().tolist())
# 确保 max_data_date 是整数(与原数据中的日期格式一致)
max_data_date = df['数据日期'].max() # 这里直接保留为整数,例如 20241231
result_list = []
for loan_month in loan_months:
# 过滤特定的放款日期
df_filtered = df[df["放款日期_年月"] == loan_month] # 确保列名和数据类型正确
# 计算 +0月、+1月、+2月的实际最后一天
results = {}
offset = list(range(12))
labels = [f"+{i}月" for i in range(12)] # "+0月", "+1月", ..., "+12月"
# 将月份转换为日期对象(月初)
month_start = pd.to_datetime(str(loan_month), format='%Y%m')
for offset, label in zip(offset, labels): ## zip 的作用是起到动态后移
# 动态计算月末日期
end_date = (month_start + pd.DateOffset(months=offset)).replace(day=1) + pd.offsets.MonthEnd(1)
# 转换为与原数据日期一致的整数格式(如20241031)
period_int = int(end_date.strftime('%Y%m%d'))
# 检查是否在数据范围内(比较整数)
if period_int <= max_data_date:
## 日期比较统一使用整数(如 20241031 和 20241231),直接比较大小。无需依赖 Timestamp 类型,避免混合类型比较错误
## filtered 记录了行为,可根据实际业务修改
filtered = df_filtered[
(df_filtered['数据日期'] == period_int) &
(df_filtered['当前逾期天数'] > 30)
]
results[label] = round(filtered['借据本金余额'].sum() / 10000, 2) / round(df_filtered['放款金额'].sum() / 10000, 2)
# 将计算结果转为百分比字符串(例如 0.85 → "85.00%")
results[label] = f"{round(results[label] * 100, 2)}%"
else:
results[label] = np.nan # 数据未到期
result_list.append({"放款日期": str(loan_month), **results})
final_result = pd.DataFrame(result_list)
Part 5. 延展 & 注意事项
本文案例的数据日期都是取月末,即计算每个放款月份在不同的月末观察窗口的逾期金额占比。这里有两个可以延展的地方:
- 观察窗口:如果想自定义成每个月的任意一天,可修改代码
# 动态计算月末日期
end_date = (month_start + pd.DateOffset(months=offset)).replace(day=1) + pd.offsets.MonthEnd(1)
# 修改成:
# 动态计算月中固定日期(例如每月15号)
end_date = (month_start + pd.DateOffset(months=offset)).replace(day=15)
- 用户行为的定义:本案例的逾期率其实就是一种用户行为,定义为“当前逾期天数>30”的借据本金余额占放款总金额的比例。换成其他行为的话,也许会得到另几个分析视角:

分析视角还有很多,这里就不一一列举了。不同行为对应的代码改造也不难,都是在 Part 4 代码中计算动态时间窗口的小循环里面进行修改。组合不同行为的 Vintage 分析表,对理解风险全貌非常有帮助。
就像笔者帮朋友的餐厅做的同期群分析,如果组合留存率和客单价(即每位顾客在一次购买中平均消费的金额)这两个视角,能综合得到的信息就更多。
- 留存率视角
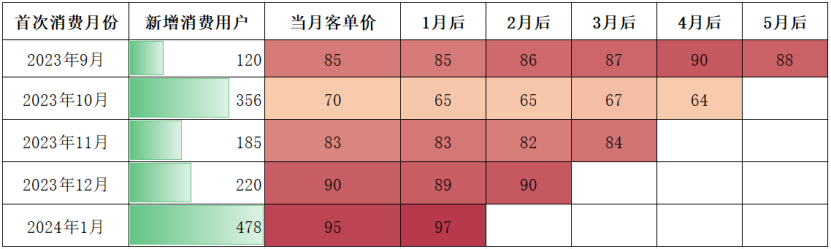
- 客单价视角
最终该餐厅的数据分析报告如下:
一、用户质量与促销活动的关联
促销用户的低质量特征:
- 2023年10月(中秋国庆 5.5 折活动):新增用户 356 人,次月留存率仅 15%(常规留存 45%~56%),且后续客单价持续低于常规水平(65元 vs 常规 83~90元)。
- 复购用户价值对比:10月促销用户的复购人数53人(356×15%),人均贡献约65元/月,远低于9月自然用户的 67 人复购(120×56%),人均贡献85元/月。
- 结论: 促销活动吸引了大量价格敏感型用户,其消费频次和客单价均显著低于自然增长用户,长期价值较低。
- 建议设计分层促销: 针对新老用户设置差异化优惠(如新用户首单5折,老用户满减券),避免低价策略稀释用户质量。
二、留存率与客单价的正相关关系
- 高留存伴随高客单价稳定性:
- 2023年9月:留存率56%→40%→35%→32%→31%,客单价稳定在85~90元,波动仅±3%。
- 2023年12月(火锅季):新增用户220人,留存率48%→45%,客单价90元→89元→90元,留存与客单价双稳。
- 低留存伴随客单价疲软:2023年10月:留存率15%→13%→13%→14%,客单价65元→65元→67元→64元,始终低于常规水平。
结论: 自然增长或产品驱动的用户(如火锅季)留存率高且消费稳定,促销用户则两者均弱。
建议:
- 强化核心产品的吸引力: 将火锅等季节性畅销品常态化(如推出“四季火锅”概念),维持用户兴趣。
留存用户专属权益: 对连续消费3个月的用户赠送高价值菜品券,增强粘性。
三、节假日活动的优化策略
- 春节(2024年1月):新增用户478人,当月客单价95元(历史最高),但1月后留存率60%需谨慎看待(假期未结束可能导致数据虚高)。
- 风险:若后续留存率快速下降(类似2023年10月),则春节用户可能成为“一次性流量”。
建议:
- 节后唤醒:在春节后1个月内推出“返工套餐”或“家庭聚餐券”,延长用户的生命周期。
- 客单价锚定:利用春节高客单价(95元)设定价格锚点,后续活动中强调“日常超值体验”(如“春节品质,日常价格”)。
参考资料
版权声明
转载分享,请在文章中注明作者和原文链接,感谢您对知识的尊重和对本文的肯定。
原文作者:萝卜(CSDN ID)
⚠️著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处,侵权转载将追究相关责任。

















 2263
2263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









