







一、背景
- 背景:常见NLP模型训练tricks
- 目标群体:Trainer
- 技术应用场景:仅适用于深度学习(狭义)模型训练,未涉及机器学习模型
- 整体思路:按训练前、训练中、训练后三个阶段划分
二、模型训练常见tricks
假定数据、算力给定,如何提高模型的泛化性和鲁棒性?
2.1 模型训练前
1. 数据增强 (EDA,Easy Data Augmention)
- 定义:一个用于提高文本分类任务性能的简单数据增强技术
- 构成:同义词替换、随机插入、随机交换和随机删除
- 同义词替换(Synonyms Replace SR):随机从句子中抽取 n 个词 (抽取时不包括停用词),然后随机找出抽取这些词的同义词,用同义词将原词替换。例如将句子 “我比较喜欢猫” 替换成 “我有点喜好猫”。通过同义词替换后句子大概率还是会有相同的标签的;
- 随机插入(Randomly Insert RI):随机从句子中抽取 1 个词 (抽取时不包括停用词),然后随机选择一个该词的同义词,插入原来句子中的随机位置,重复这一过程 n 次。例如将句子 “我比较喜欢猫” 改为 “我比较喜欢猫有点”;
- 随机交换(Randomly Swap RS):在句子中,随机交换两个词的位置,重复这一过程 n 次。例如将句子 “我比较喜欢猫” 改为 “喜欢我猫比较”;
- 随机删除(Randomly Delete RD):对于句子的每一个单词,都有 p (=α) 的概率会被删除。例如将句子 “我比较喜欢猫” 改为 “我比较猫”。
- 参数:句子中单词修改比例 α,生成句子的个数 n_aug
- 收益:EDA 对于小数据集的结果提升明显;平均而言,仅使用≈50% 的训练集进行 EDA训练,便能达到使用全量数据进行正常训练相同的准度。
- 建议:控制样本数量,少量学习,不能扩充太多,因为EDA操作太过频繁可能会改变语义,从而降低模型性能。推荐的参数组合:

2. 数据增强 (mixup)
- 定义:mixup对两个样本-标签数据对按比例相加后生成新的样本-标签数据
- 构成:给定(x_i, y_i),(x_j, y_j),具体实现方法见附录一
x' = ∂x_i + (1 - ∂)x_j ,x为输入向量
y' = ∂y_i + (1 - ∂)y_j , y为标签的one-hot编码
∂ in [0, 1]是概率值,∂~Beta(a, a),即 ∂ 服从参数a的Beta分布
- 参数:a
- 收益:
- 泛化性:mixup在语音、文本、表格等数据上表现良好,平均而言,mixup能够取得1.2~1.5%的精确率收益;
- 鲁棒性:含噪声标签的数据和对抗样本攻击等场景皆适用;
- 建议:a = 0.2 ~ 2,大样本数据集下,a = 0.2 ~0.4;
- 进阶:使用mixup以后训练抖动会大一些,训练没有base稳定,改进:cutMix, manifold mixup,patchUp,puzzleMix, saliency Mix,fMix,co-Mix。
3. 长文本处理
- 常见方法:英文限定query max_sequence_length长度
- 截取,截取前510或后510或前128+后182(共记510)+ [cls]和[sep]补齐512;
- 滑动窗口(slide window),切分文本到若干重复段,分别作为输入,最后整合多个输出;
- 分段,段数=文本长度/510,对切分的各段做整合;常见整合方法:concat或mean_sqrt或max或加attention/lstm映射。
- 建议:
- 单句NLP任务,适当长度的截断文本的信息量足够涵盖文本语义;
2.2 模型训练中
1. focal loss
- 数据不平衡造成的模型性能问题,以二分类问题为例,损失函数可以写为

其中m为正样本个数,n为负样本个数,N为样本总数,m+n=N。
当样本分布失衡时,在损失函数L的分布也会发生倾斜,如m<<n时,负样本就会在损失函数占据主导地位。由于损失函数的倾斜,模型训练过程中会倾向于样本多的类别,造成模型对少样本类别的性能较差。
2. focal loss对交叉熵损失函数做优化,解决数据不平衡造成的模型性能问题 [3]:

可简写为:

- 原理:p_t反映与真实标签 y 的接近程度,越大说明越接近类别 y,即分类越准确(越易分);
- 对于分类准确(易分)的样本 p_t -> 1,(1 - p_t) ^ r 趋近于0;
- 对于分类不准确(难分)的样本 1-p_t -> 1,(1 - p_t) ^ r 趋近于1;
- 相比交叉熵损失,focal loss对于分类不准确(难分)的样本,损失没有改变;对于分类准确(易分)的样本,损失会变小。 整体而言,相当于增加分类不准确(难分)样本在损失函数中的权重,难分类样本占主导,因此学习过程更加聚焦难分类样本。
- 参数:r > 0
- 建议:r = 2 ~ 5
2. 对抗训练(Adversarial Training)
-
定义:原始输入样本 x 上加一个扰动 r_adv ,得到对抗样本后,用其进行训练。简单抽象为:

-
优化目标:

- 内部损失函数的最大化:找到worst-case的扰动(攻击),其中 L 为损失函数,r_adv 为扰动的范围空间;
- 外部经验风险的最小化:基于该攻击方式,找到最鲁棒的模型参数(防御),其中 D 是输入样本的分布。
-
扰动方法:
-
FGM(Fast Gradient Method)

-
PGD(Projected Gradient Descent)

-
-
参数:epsilon,alpha
-
收益:
- 平均而言,对抗训练能够取得2 ~ 3%的精确率收益,但通常提升不稳定且训练速度慢几倍;
-
推荐:epsilon=1 ~ 3(扰动因子),alpha=0.1 ~ 0.5(步长)
3. 对抗训练(Adversarial Training)
- 定义:类别/标签一致的前提下,使用训练好的模型权重来对模型进行初始化,然后只在新增数据集上训练,区别于加载开源预训练模型的checkpoint对全量数据做训练;
4. R-Drop
-
定义:同样的输入,同样的模型,分别走过两个 Dropout 得到的将是两个不同的分布,近似将这两个路径网络看作两个不同的模型网络

-
优化目标:

-
原理:假如目标类为第一个类别,预测结果是[0.5,0.2,0.3]或[0.5,0.3,0.2]
- 对交叉熵损失函数来说没区别;
- 对于KL散度项来说就不一样:每个类的得分都要参与计算,[0.5,0.2,0.3]或[0.5,0.3,0.2]有非零损失;
-
参数:a
-
收益:
- R-Drop帮助模型关注非目标类的稳定性,提高模型的鲁棒性,但会增加部分训练时间,不会增加推理时间;
-
推荐:a = 1 ~ 10
5. AMP混合精度
- 定义:混合精度通常指在训练期间在模型中同时使用16位和32位浮点类型,以使其运行更快并使用更少的内存;此外,也可在神经网络推理过程中,针对不同的层,采用不同的数据精度进行计算,从而实现节省显存和加快速度的目的 。
- 支持:
- Tesla P100,Tesla V100、Tesla A100、GTX 20XX 和RTX 30XX等;
- TensorFlow ≥ 2.1,torch ≥ 1.7;
- 收益:损失精度可接受的范围内,AMP通常带来明显的内存节省和训练时长或推理时延收益
- 训练时显存占用减少≥20%,训练时长减少≥1%;
- 推理时显存占用减少≥25%,推理时延减少≥2%。
2.3 模型训练后
1. 模型平均(Stochastic Weight Averaging)
- 定义:SWA定义为对训练过程中的多个checkpoints进行平均,以提升模型的泛化性能
- 原理:记训练过程第 i 个epoch的checkpoint为 w_i,
- 一般情况下我们会选择训练过程中最后的一个epoch的模型 w_n 或者在验证集上效果最好的一个模型 w_i_* 作为最终模型;
- SWA一般在最后采用较高的固定学习速率或者周期式学习速率额外训练一段时间,取多个checkpoints的平均值;
- 参数:SWA学习率lr_s
- 收益:SWA有助于模型收敛到loss平坦区域的中心,提升模型的泛化能力
- 推荐:lr_s = 0.05 ~ 0.1
2. 异构模型融合
- 原理:K折交叉,做模型预测的logits平均;
- 推荐:考虑集成模型的异构性;
3. 推理时内存按需增长
- 原理:加载tensorflow模型时,默认一次性加载打满显存,设置按需分配显存有效减少显存占用
physical_devices = tf.config.list_physical_devices('GPU')
try:
tf.config.experimental.set_memory_growth(physical_devices[0], True)
except:
# Invalid device or cannot modify virtual devices once initialized.
pass and go on inference
三、总结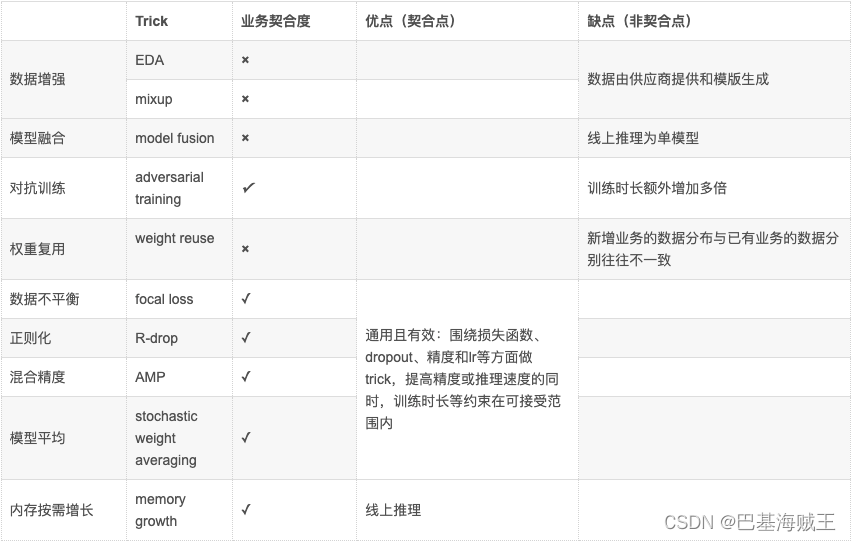
1. 技术经验
- 视不同业务场景,不同tricks通常组合使用:如比较通用的组合有mixup+amp+swa;
- tricks选定时,往往基于经验和穷举排列组合,启发性占主导;
- 模型的效果实际上仍是数据占主导,tricks只是辅助,验证trick是否生效的过程需要反复做正反向验证;
2. 亟待提升
- 思考多个trick叠加是否会产生负作用;
- “拍脑门”式trick往往取得很好的效果,是否能在“拍脑门”决策时与实际业务场景契合;
- 🤔
四、附录
1. 数据增强 (mixup) 的实现方法
- 思路:把损失函数也修改成线性组合的形式
- 实现方法(即插即用):
criterion = nn.CrossEntropyLoss()
for x, y in train_loader:
x, y = x.cuda(), y.cuda()
# Mixup inputs.
lam = np.random.beta(alpha, alpha)
index = torch.randperm(x.size(0)).cuda()
mixed_x = lam * x + (1 - lam) * x[index, :]
# Mixup loss.
pred = model(mixed_x)
loss = lam * criterion(pred, y) + (1 - lam) * criterion(pred, y[index])
optimizer.zero_grad()
loss.backward()
optimizer.step()
2. 遗留问题:AD和R-drop一起使用,总是没有单独一个效果好?
- AD+r-drop一起使用,结果经常不理想,不如单个好用;
- 单独使用AD时也不太好用,训练时长太长,但没理解是哪个环节增加的复杂度。
引用
- https://arxiv.org/abs/1901.11196
- https://github.com/jasonwei20/eda_nlp
- https://zhuanlan.zhihu.com/p/266023273
- https://zhuanlan.zhihu.com/p/91269728
- https://zhuanlan.zhihu.com/p/391881979
- https://blog.csdn.net/Jiana_Feng/article/details/123573686
- https://zhuanlan.zhihu.com/p/418305402
- https://blog.csdn.net/hxxjxw/article/details/119798535
- https://blog.csdn.net/a362682954/article/details/104774539/
- https://arxiv.org/abs/1710.09412
- https://arxiv.org/abs/1710.09412
- https://blog.csdn.net/sophicchen/article/details/120432083
- https://github.com/facebookresearch/mixup-cifar10















 1232
1232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









