







目录
概述
贝叶斯算法是一种概率分类算法,朴素贝叶斯算法是贝叶斯分类中最简单一种。
分类原理:
假设所有特征之间是统计独立的,利用贝叶斯公式根据某特征的先验概率计算出其后验概率,选择具有最大后验概率的类作为该特征所属的类。
贝叶斯公式
P
(
A
i
∣
B
)
=
P
(
A
i
)
P
(
B
∣
A
i
)
∑
i
=
1
n
P
(
A
i
)
P
(
B
∣
A
i
)
P(A_i|B) = P(A_i)\frac{P(B|A_i)}{\sum_{i=1}^nP(A_i)P(B|A_i)}
P(Ai∣B)=P(Ai)∑i=1nP(Ai)P(B∣Ai)P(B∣Ai)
注:
1)
P
(
A
i
)
P(A_i)
P(Ai) 为先验概率,即B事件发生之前,对A事件概率的判断
2)
P
(
A
i
∣
B
)
P(A_i|B)
P(Ai∣B) 为后验概率,即B事件发生之后,对A事件概率的重新评估
3)
P
(
B
∣
A
i
)
∑
i
=
1
n
P
(
A
i
)
P
(
B
∣
A
i
)
\frac{P(B|A_i)}{\sum_{i=1}^nP(A_i)P(B|A_i)}
∑i=1nP(Ai)P(B∣Ai)P(B∣Ai)为可能性函数,是一个调整因子,使预估概率更接近真实概率。
4)
后验概率 = 先验概率 * 调整因子
调整因子 > 1:先验概率增强,事件A发生的可能性变大
调整因子 = 1:B事件无法判断A的可能性
调整因子 < 1:先验概率被削弱,事件A发生的可能性变小
朴素贝叶斯种类
1 GaussianNB
先验为高斯分布(即正态分布)的朴素贝叶斯,假设每个标签的数据都服从简单的正态分布。
P
(
X
j
=
x
j
∣
Y
=
C
k
)
=
1
2
Π
σ
k
2
e
−
(
x
j
−
μ
k
)
2
2
σ
k
2
P(X_j =x_j|Y=C_k) = \frac{1}{\sqrt{2Π\sigma_k^2}}e^{-\frac{(x_j - \mu_k)^2}{2\sigma_k^2}}
P(Xj=xj∣Y=Ck)=2Πσk21e−2σk2(xj−μk)2
C
k
C_k
Ck是第k类的类别。
μ
k
\mu_k
μk和
σ
k
2
\sigma_k^2
σk2是从训练集估计的量。
import pandas as pd
import numpy as np
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
#获取数据
from sklearn import datasets
iris = datasets.load_iris()
#划分训练集和测试集
Xtrain,Xtest,ytrain,ytest = train_test_split(iris.data,iris.target,random_state=17)
#建模
clf = GaussianNB()
clf.fit(Xtrain,ytrain)
#在测试集上执行预测,proba导出的是每个样本属于某类的概率
clf.predict(Xtest)# 预测的是类别
clf.predict_proba(Xtest)#每一类的概率
accuracy_score(ytest,clf.predict(Xtest))#准确率
2 MultinominalNB
先验为多项式分布的朴素贝叶斯,假设特征是由一个简单多项式分布生成的。可以描述各种类型样本出现的概率,适合用于描述出现次数或者出现次数比例的特征。该类型常用于文本分类,特征表示次数。
P
(
X
j
=
x
j
l
∣
Y
=
C
k
)
=
x
j
l
+
λ
m
k
+
n
λ
P(X_j =x_{jl}|Y=C_k) = \frac{x_{jl}+\lambda}{m_k+n\lambda}
P(Xj=xjl∣Y=Ck)=mk+nλxjl+λ
λ:防止概率为零的情况出现。
3 BernoulliNB
先验为伯努利分布的朴素贝叶斯,假设特征的先验概率为二元伯努利分布。
P
(
X
j
=
x
j
l
∣
Y
=
C
k
)
=
P
(
j
∣
Y
=
C
k
)
x
j
l
+
(
1
−
P
(
j
∣
Y
=
C
k
)
(
1
−
x
j
l
)
)
P(X_j =x_{jl}|Y=C_k) = P(j|Y=C_k)x_{jl} + (1 - P(j|Y=C_k)(1 - x_{jl}))
P(Xj=xjl∣Y=Ck)=P(j∣Y=Ck)xjl+(1−P(j∣Y=Ck)(1−xjl))
x
j
l
x_{jl}
xjl只能取0或1。
在伯努利模型中,每个特征的取值是布尔型的,即true和false,或者1和0。在文本分类中,就是一个特征有没有在一个文档中出现。
应用
- 如果样本特征的分布大部分是连续值,使用GaussianNB
- 如果样本特征的分布大部分是多元离散值,使用MultinomialNB
- 如果样本特征是二元离散值或者很稀疏的多元离散值,使用BernoulliNB。
应用1:朴素贝叶斯之鸢尾花数据
import numpy as np
import pandas as pd
import random
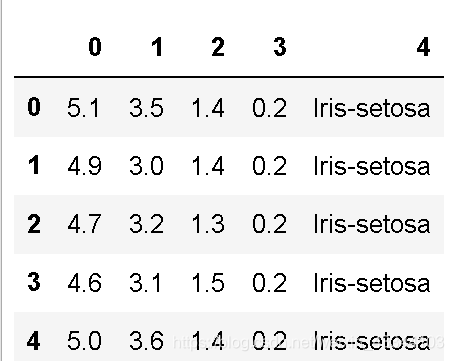
dataSet =pd.read_csv('iris.txt',header = None)
dataSet.head()
# 2 切分数据集和训练集
def randSplit(dataSet,rate):
l = list(dataSet.index) #提取出索引
random.shuffle(l) #随机打乱索引,只改变索引,不改变原数据
dataSet.index = l #将打乱后的索引重新赋值给原数据集
n = dataSet.shape[0] #总行数
m = int(n * rate) #训练集的数量
train = dataSet.loc[range(m), :] #提取前m个记录作为训练集
test = dataSet.loc[range(m, n), :] #剩下的作为测试集
dataSet.index = range(dataSet.shape[0]) #更新原数据集的索引
test.index = range(test.shape[0]) #更新测试集的索引
return train, test
train,test = randSplit(dataSet,0.8)
train

# 3 构建分类器
def gnb_classify(train,test):
labels = train.iloc[:,-1].value_counts().index #提取训练集的标签种类
mean =[] #存放每个类别的均值
std =[] #存放每个类别的方差
result = [] #存放测试集的预测结果
for i in labels:
item = train.loc[train.iloc[:,-1]==i,:] #分别提取出每一种类别
m = item.iloc[:,:-1].mean() #当前类别的平均值
s = np.sum((item.iloc[:,:-1]-m)**2)/(item.shape[0]) #当前类别的方差
mean.append(m) #将当前类别的平均值追加至列表
std.append(s) #将当前类别的方差追加至列表
means = pd.DataFrame(mean,index=labels) #变成DF格式,索引为类标签
stds = pd.DataFrame(std,index=labels) #变成DF格式,索引为类标签
for j in range(test.shape[0]):
iset = test.iloc[j,:-1].tolist() #当前测试实例
iprob = np.exp(-1*(iset-means)**2/(stds*2))/(np.sqrt(2*np.pi*stds)) #正态分布公式
prob = 1 #初始化当前实例总概率
for k in range(test.shape[1]-1): #遍历每个特征
prob *= iprob[k] #特征概率之积即为当前实例概率
cla = prob.index[np.argmax(prob.values)] #返回最大概率的类别
result.append(cla)
test['predict']=result
acc = (test.iloc[:,-1]==test.iloc[:,-2]).mean() #计算预测准确率
print(f'模型预测准确率为{acc}')
return test
gnb_classify(train,test)

应用2:文档分类
- loadDataSet:创建实验数据集
- createVocabList:生成词汇表
- setOfWords2Vec:生成词向量
- get_trainMat:所有词条向量列表
- trainNB:朴素贝叶斯分类器训练函数
- classifyNB:朴素贝叶斯分类器分类函数
- testingNB:朴素贝叶斯测试函数
1 创建数据集
#1 创建数据集
def loadDataSet():
dataSet=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop',
'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] #切分好的词条
classVec = [0,1,0,1,0,1] #类别标签向量,1代表侮辱性词汇,0代表非侮辱性词汇
return dataSet,classVec
dataSet,classVec=loadDataSet()
dataSet,classVec #数据和分类标签

2 构建不重复词汇表
# 2 构建词汇表:将切分的样本词条整理成不重复的词汇表
def createVocabList(dataSet):
vocabSet = set() #创建一个空的集合
for doc in dataSet: #遍历dataSet中的每一条言论
vocabSet = vocabSet | set(doc) #取并集
vocabList = list(vocabSet)
return vocabList
vocabList = createVocabList(dataSet)
print(vocabList) #返回列表

3 生成词向量
# 3 获得训练集向量
# 3.1 生成词向量:词条向量化,根据词汇表将切分好的词条向量化,向量的每个元素为1或2
'''
参数:
vocabList:词汇表
inputSet:切分好的词条列表中的一条
返回:
returnVec:文档向量,词集模型
'''
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList) # 创建一个其中所含元素都为0的向量
for word in inputSet: # 遍历每个词条
if word in vocabList: # 如果词条存在于词汇表中,则变为1
returnVec[vocabList.index(word)] = 1
else:
print(f" {word} is not in my Vocabulary!" )
return returnVec
4 生成词条向量列表
# 3.2生成训练集向量列表:词条向量列表
'''
参数说明:
dataSet:切分好的样本词条
返回:
trainMat:所有的词条向量组成的列表
'''
def get_trainMat(dataSet):
trainMat = [] #初始化向量列表
vocabList = createVocabList(dataSet) #生成词汇表
for inputSet in dataSet: #遍历样本词条中的每一条样本
returnVec=setOfWords2Vec(vocabList, inputSet) #将当前词条向量化
trainMat.append(returnVec) #追加到向量列表中
return trainMat
trainMat = get_trainMat(dataSet)
print(trainMat)

5 朴素贝叶斯分类器训练函数
# 4 修正后的朴素贝叶斯分类器(拉普拉斯平滑函数)
'''
参数:
trainMat: 训练文档矩阵
classVec: 训练类别标签向量(分类好的标签)
返回:
p0V: 非侮辱类的条件概率数组
p1V: 侮辱类的条件概率数组
pAb: 文档属于侮辱类的概率
'''
import numpy as np
def trainNB(trainMat,classVec):
n = len(trainMat) #计算训练的文档数目
m = len(trainMat[0]) #计算每篇文档的词条数
pAb = sum(classVec)/n #文档属于侮辱类的概率
p0Num = np.ones(m) #词条出现数初始化为1,避免后续计算分类概率的时候出现0,影响判断
p1Num = np.ones(m) #词条出现数初始化为1,避免后续计算分类概率的时候出现0,影响判断
p0Denom = 2 #分母初始化为2,避免后续计算分类概率的时候出现0,影响判断
p1Denom = 2 #分母初始化为2,避免后续计算分类概率的时候出现0,影响判断
for i in range(n): #遍历每一个文档
if classVec[i] == 1: #统计属于侮辱类的条件概率所需的数据
p1Num += trainMat[i]
p1Denom += sum(trainMat[i])
else: #统计属于非侮辱类的条件概率所需的数据
p0Num += trainMat[i]
p0Denom += sum(trainMat[i])
p1V = np.log(p1Num/p1Denom)
p0V = np.log(p0Num/p0Denom)
return p0V,p1V,pAb #返回属于非侮辱类,侮辱类和文档属于侮辱类的概率
p0V,p1V,pAb = trainNB(trainMat,classVec)
p0V,p1V,pAb

6 测试分类器
# 5 测试朴素贝叶斯分类器
'''
参数说明:
vec2Classify:待分类的词条数组
p0V:非侮辱类的条件概率数组
p1V:侮辱类的条件概率数组
pAb:文档属于侮辱类的概率
返回:
0:属于非侮辱类
1:属于侮辱类
'''
from functools import reduce
def classifyNB(vec2Classify, p0V, p1V, pAb):
p1 = sum(vec2Classify * p1V) + np.log(pAb) #对应元素相乘
p0 = sum(vec2Classify * p0V) + np.log(1- pAb) #对应元素相乘
print('p0:',p0)
print('p1:',p1)
if p1 > p0:
return 1
else:
return 0
测试应用
# 测试样本
def testingNB(testVec):
dataSet,classVec = loadDataSet() #创建实验数据
vocabList = createVocabList(dataSet) #创建词汇表
trainMat = get_trainMat(dataSet) #生成词条向量列表
p0V,p1V,pAb = trainNB(trainMat,classVec) #训练朴素贝叶斯分类器,得到分类结果
thisone = setOfWords2Vec(vocabList, testVec) #生成词向量
if classifyNB(thisone,p0V,p1V,pAb) == 1: #判断分类结果
print(testVec,'属于侮辱类') #执行分类并打印分类结果
else:
print(testVec,'属于非侮辱类')
#测试样本1
testVec1 = ['love', 'my', 'dalmation']
testingNB(testVec1)

#测试样本2
testVec2 = ['stupid', 'garbage']
testingNB(testVec2)
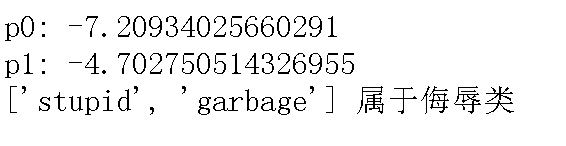















 3259
3259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









