







 本文介绍了如何使用Python对Wimbledon网球比赛数据进行预处理,包括时间差计算和缺失值填充。随后,通过可视化展示了球员得分变化和特征间的相关性矩阵。使用了RandomForestClassifier进行分类,并展示了交叉验证和性能评估指标。
本文介绍了如何使用Python对Wimbledon网球比赛数据进行预处理,包括时间差计算和缺失值填充。随后,通过可视化展示了球员得分变化和特征间的相关性矩阵。使用了RandomForestClassifier进行分类,并展示了交叉验证和性能评估指标。
因为一些不可抗力,下面仅展示部分代码(第一问的部分),其余代码看文末
首先导入本题需要的包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from datetime import timedelta
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report读取数据:
match_data_path = './Wimbledon_featured_matches.csv'
match_data = pd.read_csv(match_data_path)
match_data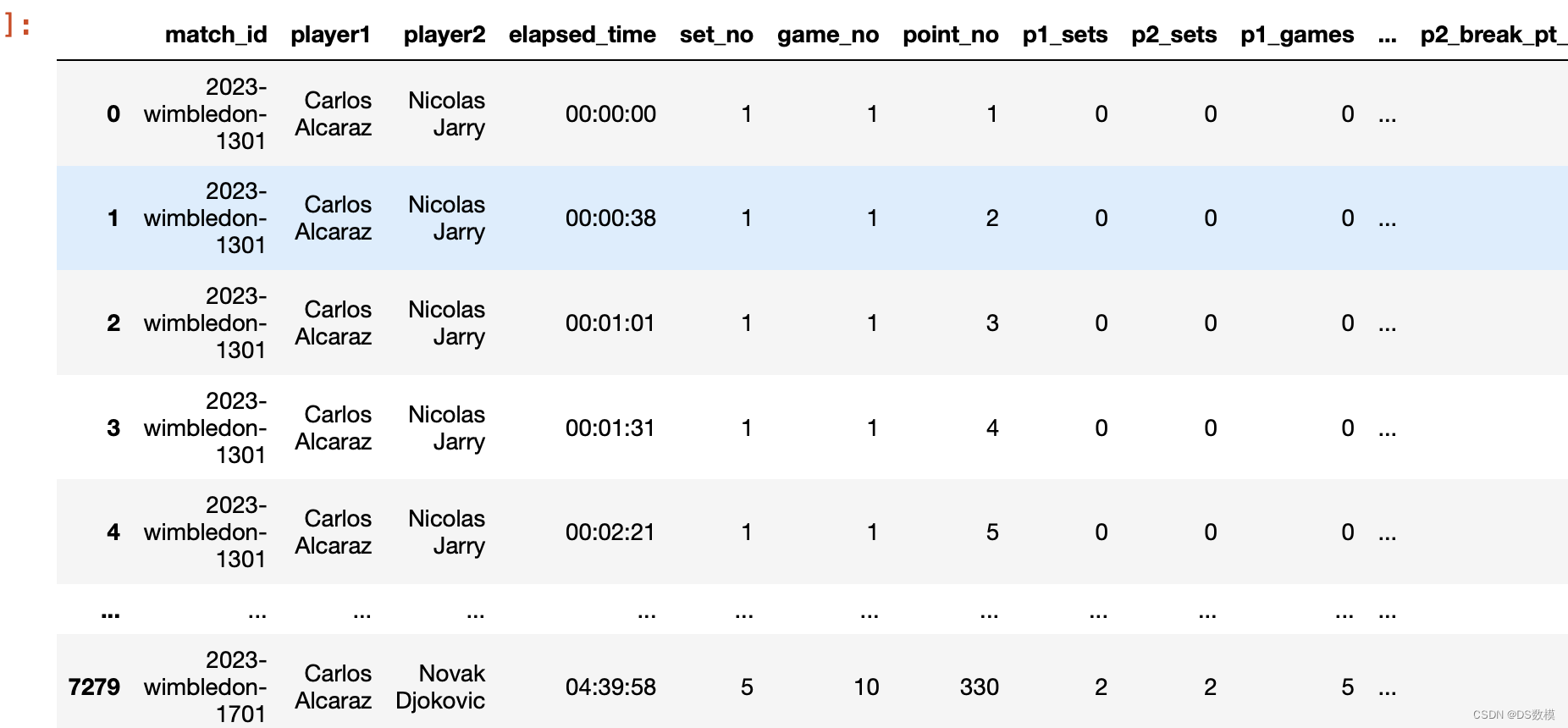
数据预处理(部分):
# 数据预处理
# Convert `elapsed_time` to timedelta
match_data['elapsed_time_td'] = pd.to_timedelta(match_data['elapsed_time'])
# Calculate the time difference in seconds within each match_id group
match_data['time_diff'] = match_data.groupby('match_id')['elapsed_time_td'].diff().dt.total_seconds()
# Fill NaN values with the first elapsed_time value in each group, converted to seconds
match_data['time_diff'] = match_data.groupby('match_id')['time_diff'].fillna(
match_data['elapsed_time_td'].dt.total_seconds()
)
# Show the updated dataframe to verify changes
match_data[['match_id', 'elapsed_time', 'time_diff']].head()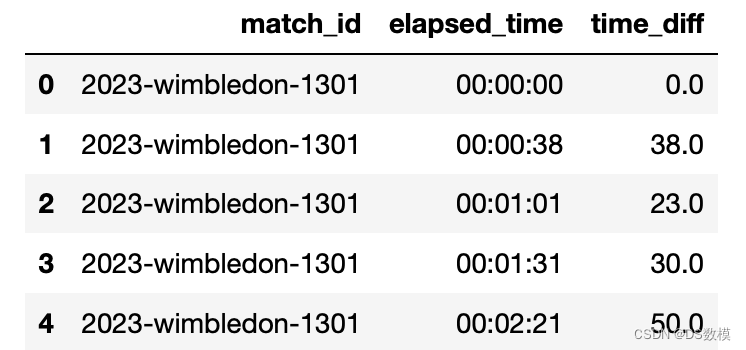
接着来看后面的部分可视化展示:(仅部分代码)
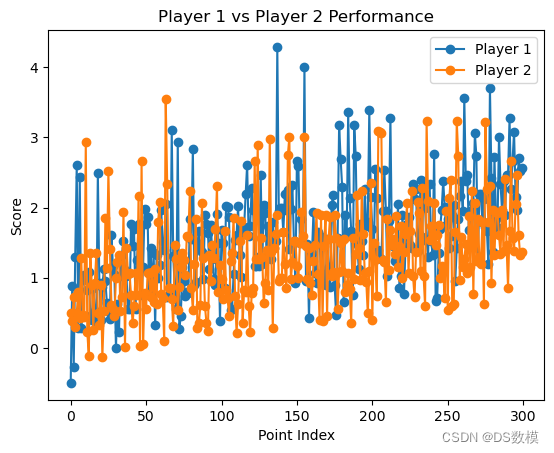
上图代码:
# 假设p1_scores和p2_scores是您计算得到的分数
# 创建一个与分数长度相同的索引列表,以用作X轴
index = list(range(len(p1_scores)))
# 绘制p1和p2的折线图
plt.plot(index, p1_scores, label='Player 1', linestyle='-', marker='o')
plt.plot(index, p2_scores, label='Player 2', linestyle='-', marker='o')
# 添加标签和标题
plt.xlabel('Point Index')
plt.ylabel('Score')
plt.title('Player 1 vs Player 2 Performance')
# 添加图例
plt.legend()
# 显示图形
plt.show()
添加图片注释,不超过 140 字(可选)
correlation_matrix = match_data.iloc[:,[1,2,]].corr()
# 可视化相关性矩阵
plt.figure(figsize=(20, 16))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
# 设置热图的标题
plt.title('Correlation Matrix')
# 显示图形
plt.show()

添加图片注释,不超过 140 字(可选)
有关思路、相关代码、讲解视频、参考文献等相关内容可以点击下方群名片哦!















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









