






1. 原理
1.1 基本思想
什么是协同过滤(Collaborative Filtering)
协同过滤是一种利用群体行为数据的推荐算法,通过分析用户的历史行为(如评分、点击等),协同过滤通过分析用户行为数据,找到相似的用户(UserCF)并推荐他们喜欢的物品,或找到相似的物品(ItemCF)并推荐给喜欢过同类物品的用户,从而预测目标用户可能感兴趣的内容。
其核心思想是“相似的用户喜欢相似的物品”(UserCF)或“相似的物品被相似的用户喜欢”(ItemCF),通过协同大家的反馈和意见,从海量信息中筛选出目标用户可能感兴趣的内容。
1.2 数据准备
用户-物品评分矩阵:构建一个矩阵,其中行表示用户,列表示物品,矩阵中的值表示用户对物品的评分。
例如:
| 用户\物品 | 物品A | 物品B | 物品C |
|---|---|---|---|
| 用户1 | 5 | 3 | 0 |
| 用户2 | 4 | 0 | 1 |
| 用户3 | 1 | 2 | 5 |
- 其中
0表示用户未对该物品评分。 - 稀疏性问题:用户-物品评分矩阵通常非常稀疏,因为用户只会对少数物品评分。
1.3 相似度计算
相似度计算是协同过滤的核心步骤,用于衡量用户之间或物品之间的相似性。常用的方法包括余弦相似度和皮尔逊相关系数,具体内容见 **第3节**。
1.4 预测评分
- UserCF:对于目标用户未评分的物品,利用与其相似用户的评分进行加权平均,预测目标用户对该物品的评分。
- ItemCF:对于目标用户未评分的物品,利用与该物品相似物品的评分进行加权平均,预测目标用户对该物品的评分。
1.5 生成推荐列表
根据预测评分,为目标用户推荐评分最高的物品。
2. UserCF(基于用户的协同过滤)
2.1 核心思想
UserCF 的核心思想是:找到与目标用户相似的用户,推荐这些相似用户喜欢的物品。
例如,如果用户A和用户B都喜欢电影X和Y,而用户A还喜欢电影Z,那么可以推荐电影Z给用户B。
2.2 预测评分
对于目标用户 ( u ) 和未评分的物品 ( i ),预测评分的公式为:
- 其中:
- Nu 表示与用户 u最相似的 K个用户。
- r_u和 r_v 分别表示用户u和用户v的平均评分。
3. ItemCF(基于物品的协同过滤)
3.1 核心思想
- ItemCF 的核心思想是:找到与目标物品相似的物品,推荐这些相似物品给用户。
- 例如,如果用户喜欢电影X,而电影X和电影Y非常相似,那么可以推荐电影Y给用户。
3.2 预测评分
对于目标用户 ( u ) 和未评分的物品 ( i ),预测评分的公式为:
- 其中:
- Ni表示与物品i 最相似的 K 个物品。
- ri 和 rj 分别表示物品 i和物品j 的平均评分。
3.3 生成推荐列表
根据预测评分,为目标用户推荐评分最高的物品。
4. 相似度计算方法
4.1 余弦相似度
公式:
-
参数解释:
- r_ui 表示用户 ( u ) 对物品 ( i ) 的评分。
- I_uv 表示用户 ( u ) 和用户 ( v ) 共同评分的物品集合。
-
适用场景:
- 适用于评分数据较为稠密的情况。
- 对用户的评分尺度不敏感。
4.2 皮尔逊相关系数
公式:
-
参数解释:
- r_u 和 r_v 分别表示用户 ( u ) 和用户 ( v ) 的平均评分。
-
适用场景:
- 适用于评分数据存在偏差(如用户评分习惯不同)的情况。
- 对用户的评分尺度敏感,能够消除用户评分偏差。
5. 代码实现
以下我们以 MovieLens 100K 数据集为例,演示如何实现基于用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。
5.1 加载数据集
import pandas as pd
from surprise import Dataset
# 加载MovieLens数据集
data = Dataset.load_builtin('ml-100k')
df = pd.DataFrame(data.raw_ratings, columns=['user_id', 'item_id', 'rating', 'timestamp'])
df = df[['user_id', 'item_id', 'rating']] # 只保留用户、物品、评分三列
# 查看数据
print(df.head())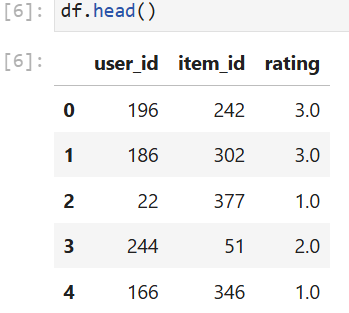
5.2 构建用户-物品评分矩阵
# 构建用户-物品评分矩阵
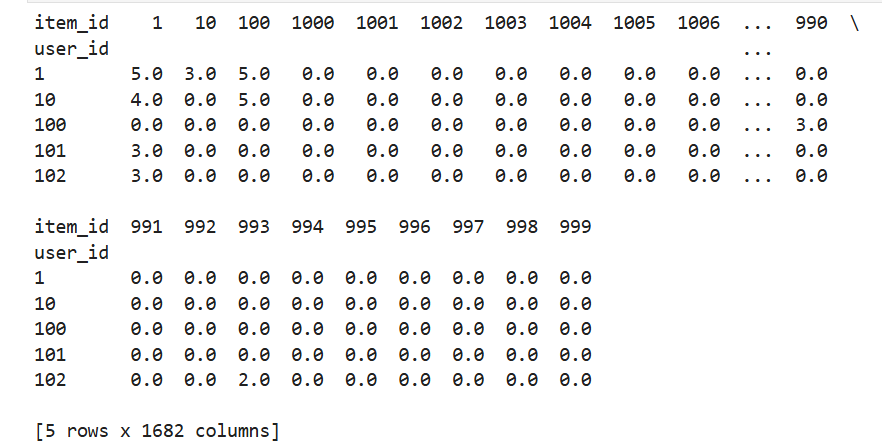
user_item_matrix = df.pivot(index='user_id', columns='item_id', values='rating').fillna(0)
print(user_item_matrix.head())-
行:每个用户(
user_id)。 -
列:每个物品(
item_id)。 -
值:用户对物品的评分,未评分的部分用
0填充。
5.3 计算用户相似度(UserCF)
from sklearn.metrics.pairwise import cosine_similarity
# 计算用户相似度矩阵(余弦相似度)
user_similarity_cosine = cosine_similarity(user_item_matrix)
user_similarity_cosine_df = pd.DataFrame(user_similarity_cosine, index=user_item_matrix.index, columns=user_item_matrix.index)
print(user_similarity_cosine_df.head())
5.4 计算物品相似度(ItemCF)
# 计算物品相似度矩阵(余弦相似度)
item_similarity_cosine = cosine_similarity(user_item_matrix.T)
item_similarity_cosine_df = pd.DataFrame(item_similarity_cosine, index=user_item_matrix.columns, columns=user_item_matrix.columns)
print(item_similarity_cosine_df.head())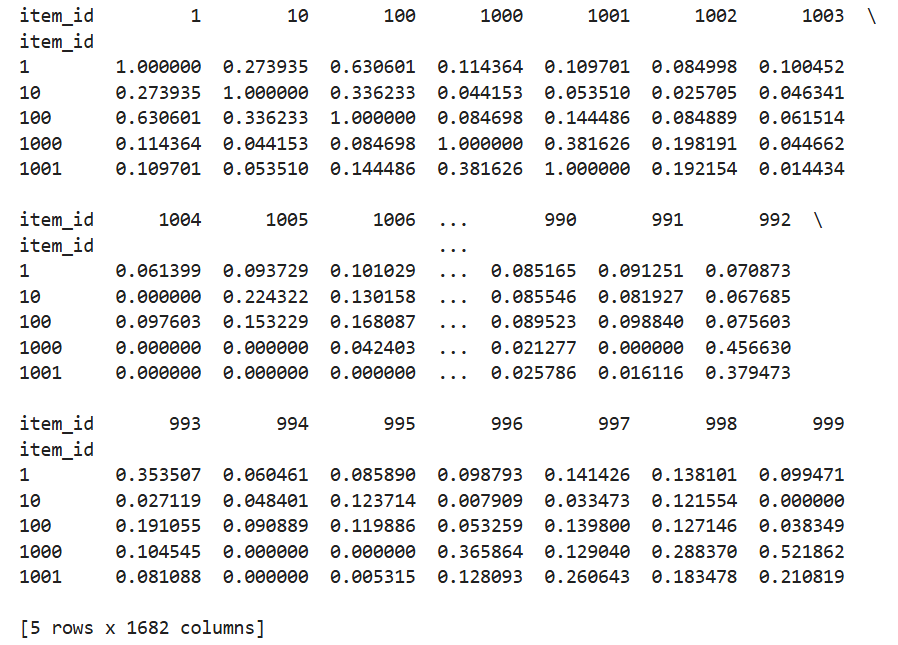
5.5 预测评分与生成推荐列表(UserCF)
def predict_rating_user_cf(user_id, item_id, user_item_matrix, user_similarity_matrix, k=5):
"""
基于 UserCF 预测用户对物品的评分
:param user_id: 目标用户 ID
:param item_id: 目标物品 ID
:param user_item_matrix: 用户-物品评分矩阵
:param user_similarity_matrix: 用户相似度矩阵
:param k: 最相似的 K 个用户
:return: 预测评分
"""
# 获取目标用户的平均评分
user_mean_rating = user_item_matrix.loc[user_id].mean()
# 找到与目标用户最相似的 K 个用户
similar_users = user_similarity_matrix[user_id].sort_values(ascending=False)[1:k+1]
# 计算加权评分
weighted_sum = 0
similarity_sum = 0
for similar_user, similarity in similar_users.items():
if user_item_matrix.loc[similar_user, item_id] != 0: # 仅考虑已评分的用户
similar_user_mean_rating = user_item_matrix.loc[similar_user].mean()
weighted_sum += similarity * (user_item_matrix.loc[similar_user, item_id] - similar_user_mean_rating)
similarity_sum += abs(similarity)
if similarity_sum == 0:
return user_mean_rating # 如果没有相似用户评分,返回用户平均评分
# 预测评分
predicted_rating = user_mean_rating + (weighted_sum / similarity_sum)
return predicted_rating
def recommend_items_user_cf(user_id, user_item_matrix, user_similarity_matrix, k=5, top_n=10):
"""
基于 UserCF 生成推荐列表
:param user_id: 目标用户 ID
:param user_item_matrix: 用户-物品评分矩阵
:param user_similarity_matrix: 用户相似度矩阵
:param k: 最相似的 K 个用户
:param top_n: 推荐列表的长度
:return: 推荐物品列表
"""
# 找到目标用户未评分的物品
unrated_items = user_item_matrix.columns[user_item_matrix.loc[user_id] == 0]
# 预测未评分物品的评分
predictions = {}
for item_id in unrated_items:
predicted_rating = predict_rating_user_cf(user_id, item_id, user_item_matrix, user_similarity_matrix, k)
predictions[item_id] = predicted_rating
# 按预测评分排序,生成推荐列表
recommended_items = sorted(predictions.items(), key=lambda x: x[1], reverse=True)[:top_n]
return recommended_items
# 示例:为用户 1 生成推荐列表
user_id = '1'
recommendations = recommend_items_user_cf(user_id, user_item_matrix, user_similarity_cosine_df, k=5, top_n=10)
print(f"为用户 {user_id} 推荐的物品列表:{recommendations}")
5.6 预测评分与生成推荐列表(ItemCF)
代码与5.5UserCF几乎一致,只有两点区别:
- 相似度矩阵不同,UserCF使用5.3的user_similarity_cosine_cf,ItemCF使用5.4的item_similarity_cosine_df;
- 加权评分的计算方式不同,详见4中公式区别,ItemCF在计算加权评分时,通常不需要减去物品的平均评分,用户需要减去是因为用户有个人偏好,可能会对所有商品都评分偏高或偏低。
6. 常见面试考点
-
协同过滤的原理是什么?UserCF和ItemCF的区别?
协同过滤是一种基于用户行为数据的推荐算法。它通过用户的历史行为(如评分、点击、购买等)来预测用户对未评分或未接触的物品的兴趣。
用户协同过滤(UserCF):通过找出与目标用户兴趣相似的用户,基于这些相似用户的评分来预测目标用户对物品的评分。UserCF具有更强的社交特性,适合偏好性强的场景,如新闻推荐。
物品协同过滤(ItemCF):通过找出与目标物品相似的物品,基于目标用户对这些物品的评分来预测用户对未评分物品的评分。ItemCF更适用于兴趣变化较为稳定的应用,比如电商推荐、电影推荐等,因为用户在一个时间段内更倾向于寻找一类商品;对观看的电影、电视剧兴趣较为稳定。
-
协同过滤的优缺点是什么?如何解决冷启动问题?
优点:
简单直观,容易实现。
无需物品的额外信息(如内容特征),只需用户的历史行为数据。
缺点:
冷启动问题:对于新用户或新物品,由于缺乏足够的数据,协同过滤无法做出有效推荐。
稀疏矩阵问题:评分矩阵通常非常稀疏,很多用户没有对大部分物品评分,导致推荐效果下降。
扩展性问题:随着用户和物品数量的增加,计算相似度和推荐的复杂度也会大幅上升
-
相似度计算方法有哪些?各自的适用场景?
余弦相似度
使用场景:计算用户或物品之间的相似度,常用于稀疏矩阵。
理由:适合评估相对频繁评分的用户或物品,忽略评分的绝对值,只关注评分模式。
皮尔逊相关系数
使用场景:计算用户之间或物品之间的相似度,适用于有评分偏差的情况。
理由:能够消除用户评分偏差,衡量用户或物品间的线性相关性。
Jaccard 相似度
使用场景:适用于二元行为数据(如是否点击)。
理由:计算物品或用户间是否具有共同的偏好,适用于稀疏数据或二分类问题。
-
协同过滤的计算复杂度如何优化?
- 使用稀疏矩阵:只计算非零评分项,避免全矩阵计算。
- 降维技术:如SVD,压缩评分矩阵,减少计算量。
- 近似最近邻(ANN):使用近似算法加速相似度计算。
- 分布式计算:在大规模数据集上使用分布式计算框架加速。
- 基于模型的协同过滤:使用矩阵分解等模型减少计算复杂度。

















 8809
8809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









