






来自2023年的新论文,提出了Wanda这一无需再训练和权重更新的低成本剪枝方法。
论文链接:https://arxiv.org/pdf/2306.11695v2
代码链接:GitHub - locuslab/wanda: A simple and effective LLM pruning approach.
摘要(Abstract):
关于现存的大模型LLMs的剪枝方法,即尽量保持性能的情况下去掉一部分权重。要么需要再训练——难以负担巨大的计算成本;要么需要依赖二阶信息的重建,也意味着计算成本过高。而Wanda是一种基于权重和激活进行剪枝的方法,通过剪除权重乘以输入激活最小的权重,以减少预训练大语言模型中的稀疏性,而无需再训练或权重更新。
介绍(Introduction)
近年来大模型的规模随着性能提示,参数也在持续增加,带来了很大的计算负担。目前很多研究集中在模型量化上,通过将参数量化为较低精度来表示(尽管会带来精度损失),而模型剪枝作为应用较少的常见压缩方法值得更深的研究。
模型剪枝通过移除特定权重来减小网络规模,通常需要再训练或复杂的权重更新(如SparseGPT),这些方法都有高计算需求,限制了其应用。现有的较为著名的剪枝方法有:
- 传统网络剪枝(LeCun et al., 1989; Hassibi et al., 1993; Han et al., 2015):通过移除模型中的特定权重来减小网络规模,通常将这些权重设置为零。
-
幅度剪枝(Magnitude Pruning,Han et al., 2015):基于权重的绝对值进行剪枝,移除幅度较小的权重。
-
再训练需求(Liu et al., 2019; Blalock et al., 2020):许多现有的剪枝方法需要剪枝后对模型进行再训练,以恢复或保持模型性能。
-
从随机初始化开始训练(Zhu & Gupta, 2017; Louizos et al., 2018; Gale et al., 2019):这些方法需要从随机初始化开始进行剪枝和训练。
-
复杂的迭代过程(Frankle & Michael, 2019; Renda et al., 2020):例如Lottery Ticket Hypothesis假设存在一个子网络可以通过剪枝和再训练达到与原始网络相近的性能,需多次剪枝和再训练的迭代过程。
-
SparseGPT(Frantar & Alistarh, 2023):这种方法不需要传统的再训练,但仍然需要复杂的权重更新过程。
Wanda是基于权重幅度(Weight Magnitude)的剪枝方法,即在Magnitude Pruning基础上,结合对应的激活来决定剪掉哪些权重。
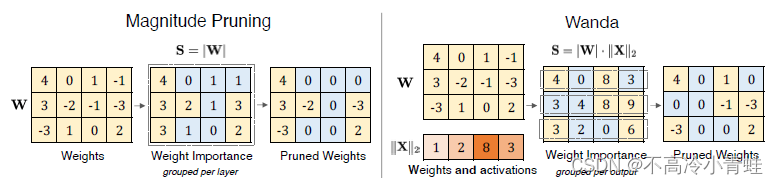
左图Magnitude Pruning选取了50%最小的权重并全部赋值0;
右图Wanda在计算了权重和激活
相乘后的结果
,再选取50%最小的
位置并将对应位置的权重赋值为0。
关于Wanda
基础概念
Wanda的灵感来源——突现的大幅度特征(Emergent Large Magnitude Features)(Dettmers et al. (2022)):一旦大语言模型(LLMs)达到一定规模,隐藏状态特征的一小部分会显示出显著大于其他特征的幅度。这些特征对模型的性能至关重要,归零这些特征会导致显著的性能下降。
传统的Magnitude Pruning可能会错误地剪掉一些重要特征,尽管这些特征的权重很小,但在模型中起到的作用很大,而Wanda的改进能够识别并保留那些尽管权重较小但因激活值较大而对模型性能至关重要的特征。
Wanda在每个输出节点上局部进行比较,而不是像传统剪枝这样在每一层内或整个网络中比较权重,这样可以更精细地控制稀疏性,且实验表明局部化剪枝比逐层剪枝效果更好,但仅在大语言模型中,在图像分类模型并没有观察到此类趋势(论文中没有给到具体实验数据)。
代码
Wanda的PyTorch代码如下
# W: weight matrix (C_out, C_in)
# X: input matrix (N * L, C_in)
# s: desired sparsity, between 0 and 1
def prune(W, X, s):
metric = W.abs() * X.norm(p=2, dim=0)
_, sorted_idx = torch.sort(metric, dim=1)
pruned_idx = sorted_idx[:, :int(C_in * s)]
W.scatter_(dim=1, index=pruned_idx, src=0)
return W
-
输入参数:
-
计算剪枝指标:
- 计算每个权重的绝对值乘以对应输入激活的
范数,得到剪枝指标
-
排序和选择要剪除的权重:
- 对指标进行排序
- 选择需要剪除的权重索引
-
执行剪枝:
- 根据选择的索引将相应的权重设置为零
-
返回剪枝后的权重矩阵:
结构化稀疏(Structured N:M Sparsity)
非结构化稀疏性:在非结构化稀疏性中,权重是独立选择的,可以任意位置为零。
结构化稀疏性:每M个连续权重中最多只有N个权重是非零的。这种稀疏模式可以利用NVIDIA的稀疏张量核心在实际中加速矩阵乘法。
Wanda最初是为非结构化稀疏性开发的,但它可以轻松扩展到结构化稀疏性——在每M个连续权重中使用相同的剪枝指标进行比较,并剪除多余的权重。
实验
Wanda在两个广泛采用的LLM模型系列上评估Wanda方法:LLaMA 7B/13B/30B/65B (Touvron et al., 2023a) 和 LLaMA-2 7B/13B/70B (Touvron et al., 2023b),在WikiText (Merity et al., 2016) 数据集的验证集上评估困惑度。
Wanda会与Magnitude pruning和SparseGPT作比较,主要关注剪枝线性层(跳过第一个嵌入层和最后一个分类层,这些层占总LLM参数量的约99%),且为所有线性层施加统一的稀疏性:非结构化稀疏性、结构化的4:8和2:4稀疏性。

















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









