







https://blog.csdn.net/zwq912318834/article/details/79571110 还是跟着大佬学习的使用方法。
https://cn.tophatter.com/ 我要爬取这个拍卖网站 登陆的话使用账号密码,
第一步:还是登陆一个账号和密码错误的,看计算机response是什么鬼。

返回的是.json格式的内容。
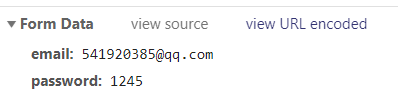
拉倒最下面,可以看到传递的数据格式。
第二步:将参数出入到request的post请求中
import requests
import http.cookiejar as cookielib
Chinatophatter=requests.session() #维持会话 实例化对象
Chinatophatter.cookies = cookielib.LWPCookieJar(filename = "tophatterCookies.txt") #将cookie保存到本地的TXT文件
userAgent='Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
header={
'Referer': 'https://cn.tophatter.com/',
'User-Agent': userAgent,
}
'''登陆函数,传入账号和密码'''
def Login():
print("开始模拟登录大礼帽网站")
postUrl = "https://cn.tophatter.com/api/v1/users/authenticate.json"
postData = {
"email": '输入你的账号',
"password": '输入你的密码',
}
# 使用session直接post请求
responseRes = Chinatophatter.post(postUrl, data = postData, headers = header)
# 无论是否登录成功,状态码一般都是 statusCode = 200
print(f"statusCode = {responseRes.status_code}")
print(f"text = {responseRes.text}")
Chinatophatter.cookies.save() #保存cookies到本地
return
from scrapy.selector import Selector
if __name__ == '__main__':
'''账户密码 633900 3900'''
Login() #运行,直接登陆
Chinatophatter.cookies.load(ignore_discard=True) #读取cookies
infoUrl = 'https://cn.tophatter.com/seller/insights/categories'
responseJCI = Chinatophatter.get(infoUrl, headers=header, allow_redirects=False)
if responseJCI.status_code != 200:
url = responseJCI.headers['Location'] # 没登录上,需要再次登陆 cookies失效了
print(url)
else:
print(responseJCI.text)
'''使用xpath,直接将response传入'''
selector = Selector(responseJCI)
第三步:
解析网站

















 4925
4925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











