









图神经网络(三)GCN的变体与框架(4)GNN的通用框架
3.4 GNN的通用框架
在介绍完GNN的集中变体后,本节我们来看看GNN的通用框架。所谓通用框架,是对多种变体GNN网络结构的一般化总结,也是GNN变成的通用范式,研究它能够帮助我们更加清晰地横向对比各类GNN模型,同时也为GNN模型的灵活拓展提供了方向。
下面我们介绍3类通用框架:消息传播神经网络(Message Passing Neural Network,MPNN)、非局部神经网络(Non-Local Neural Network,MPNN)、图网络(Graph Network,GN)。MPNN从聚合与更新的角度归纳总结了GNN模型的几种变体,NLNN是对给予注意力机制的GNN模型的一般化总结,在这两种框架之上,GN做到了对GNN模型更全面化的总结。
3.4.1 MPNN
在引文 [8] 中提出了MPNN,通过消息传播机制对多种GNN模型做出了一般化总结。其基本思路为:节点的表示向量都是通过消息函数
M
M
M(Message)和更新函数
U
U
U(Update)进行
K
K
K 轮消息传播机制的迭代后得到的,消息传播的过程如下:
m
i
(
k
+
1
)
=
∑
v
j
∈
N
(
v
i
)
M
(
k
)
(
h
i
(
k
)
,
h
j
(
k
)
,
e
i
j
)
\boldsymbol{m}_i^{(k+1)}=∑_{v_j∈N(v_i )}M^{(k)}\big(\boldsymbol{h}_i^{(k)}, \boldsymbol{h}_j^{(k)}, \boldsymbol{e}_{ij}\big)
mi(k+1)=vj∈N(vi)∑M(k)(hi(k),hj(k),eij)
h
i
(
k
+
1
)
=
U
(
k
)
(
h
i
(
k
)
,
m
i
(
k
+
1
)
)
\boldsymbol{h}_i^{(k+1)}=U^{(k)}\big(\boldsymbol{h}_i^{(k)}, \boldsymbol{m}_i^{(k+1)}\big)
hi(k+1)=U(k)(hi(k),mi(k+1))
其中
e
i
j
\boldsymbol{e}_{ij}
eij 表示边
⟨
v
i
,
v
j
⟩
\langle v_i,v_j\rangle
⟨vi,vj⟩ 上的特征向量,k表示第k次消息传播,在实际编程中,一般和模型中层的概念等价。
消息函数的输入由边本身以及两侧节点构成,为了方便描述,我们借用RDF(Resource Description Framework)三元组来表示这样的输入:
S
o
u
r
c
e
P
r
e
d
i
c
t
→
O
b
j
e
c
t
\boldsymbol{\large Source}\quad\underrightarrow{Predict}\quad \boldsymbol{\large Object}
SourcePredictObject
S
o
u
r
c
e
Source
Source 表示源节点,
O
b
j
e
c
t
Object
Object 表示目标节点,
P
r
e
d
i
c
t
Predict
Predict 表示源节点到目标节点的关系。这种描述框架非常自然地对应了汉语中的主谓宾三元组短句,如“GNN属于Deep Learning”,就描述了“GNN”到“Deep Learning”之间的关系,用RDF表示如下:
G
N
N
属
于
→
D
e
e
p
L
e
a
r
n
i
n
g
\boldsymbol{\large GNN}\quad\underrightarrow{属于}\quad \boldsymbol{\large Deep\ Learning}
GNN属于Deep Learning
在消息函数的作用下,图例面所有的RDF都会向外广播消息,之后这些消息都会沿着变得方向传播到RDF的两侧节点处进行聚合,聚合后的消息会在之后的更新函数的作用下对节点特征进行更新。如图3-8所示为MPNN计算的示意图:
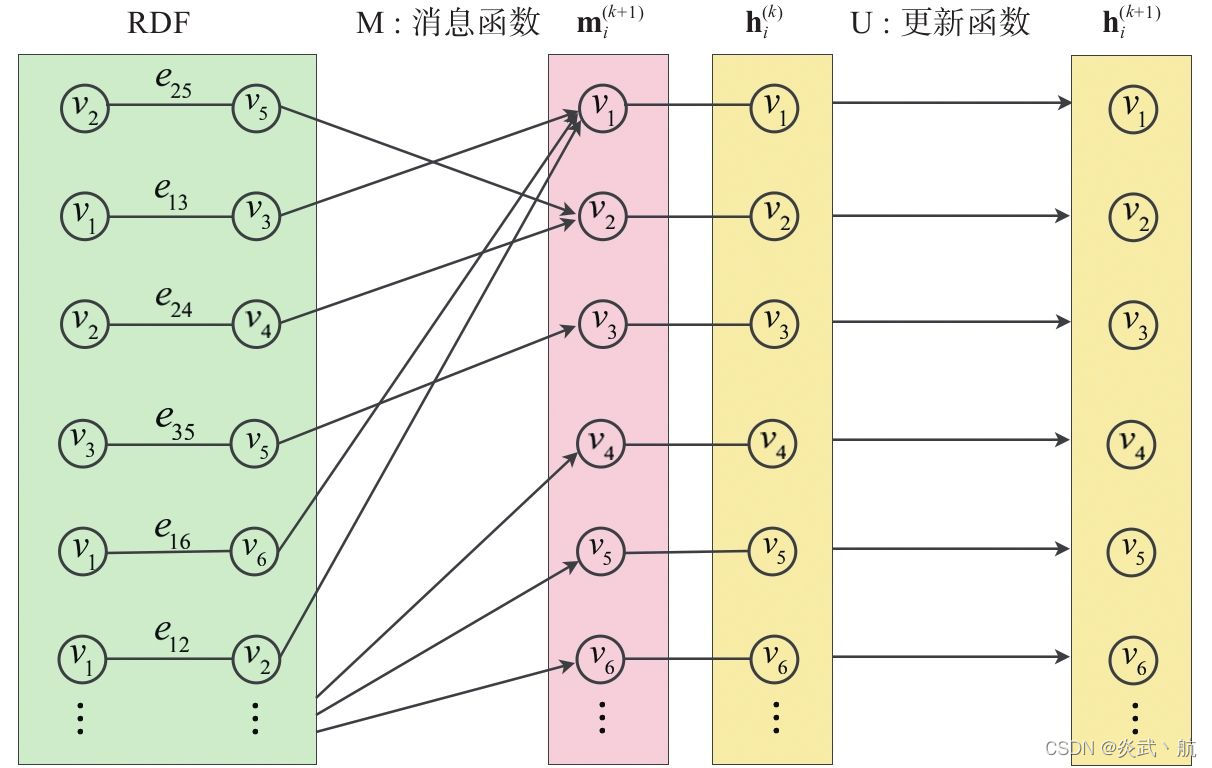
图3-8 MPNN计算示意图
要特别说明的是,上面的MPNN并没有对边的表示向量进行迭代更新,该文作者指出,如果有必要的话,比如在某场景下的图数据中边具有显式的重要意义,可以与节点一样,对边的表示向量始终维护一个状态变量,具体做法可以参考下面GN的做法。
MPNN的核心在于消息函数和更新函数,原则上可以把它们设计成任意一种DNN模型。接下来我们看看在消息传播的视角下,该如何确定GCN、R-GCN、GraphSAGE、Interaction Network [9] 等GNN模型中的消息函数与更新函数,如表3-1所示:

由于MPNN的消息函数是作用在RDF三元组上的,因此其对各种类型的图数据都具有一定的适应性。下面给出对于常见的同构图、异构图、属性图等类型的图数据用MPNN框架进行处理的方法,处理的方式不限于此,读者可自行考虑:
(1)同构图:同构图本身是非常容易处理的,唯一特殊的是有向加权图。对于这类图数据,可以将边的正反方向看成两种关系,借用R-GCN的思路进行处理,同时对边上的权重可以考虑进邻接矩阵中当作归一化项一并处理。
(2)异构图:可以考虑R-GCN方式,另外如果关系不多,可以将关系编码成one-hot向量当作边上的特征进行处理。
(3)属性图:之前我们介绍了属性图是一种应用很广泛的图数据的表达形式。在树形图中,我们需要考虑的因素有节点的易购以及边属性。对于前者,如果我们追求工程上的简化处理,可以在调用MPNN之前,对不同类型的节点分别送进变换函数(这些函数可以是任意的NN模型)里面,将异构的节点变换到同一维度的同一特征空间里,之后当作节点同构的图处理。对于后者,可以参考关系图的处理方式,这里如果边上具有一些属性信息的话,按照消息函数的机制,需要对其进行特征编码(比如类别型属性特征进行one-hot编码或者embedding编码)。
3.4.2 NLNN
非局部神经网络(NLNN)[10] 是对注意力机制的一般化总结,上一节介绍的GAT就可以看作是它的一个特例。NLNN通过non-local操作将任意位置的输出响应计算为所有位置特征的加权和。位置可以是图像中的空间坐标,也可以是序列数据中的时间坐标,在图数据中,位置可以直接以节点代替。
通用的non-local操作的定义如下:
h
i
′
=
1
C
(
h
)
∑
∀
j
f
(
h
i
,
h
j
)
g
(
h
j
)
\boldsymbol{h}_i'=\frac{1}{C(\boldsymbol{h})}∑_{∀j}f(\boldsymbol{h}_i,\boldsymbol{h}_j )g(\boldsymbol{h}_j)
hi′=C(h)1∀j∑f(hi,hj)g(hj)
这里的i是输出位置的索引,j是枚举所有可能位置的索引。
f
(
h
i
,
h
j
)
f(\boldsymbol{h}_i,\boldsymbol{h}_j )
f(hi,hj) 是i和j位置上元素之间的相关度函数,
g
(
h
j
)
g(\boldsymbol{h}_j)
g(hj) 表示对输入
h
j
\boldsymbol{h}_j
hj 进行变换的变换函数,因子
1
C
(
h
)
\frac{1}{C(\boldsymbol{h})}
C(h)1 用于归一化的结果。
同MPNN一样,NLNN的核心也在两个函数上: f f f 和 g g g 。为了简便,我们可以使用线性变换作为函数 g g g : g ( h j ) = W g h j g(\boldsymbol{h}_j )=W_g \boldsymbol{h}_j g(hj)=Wghj ,这里 W g W_g Wg 是需要学习的权重参数。下面我们重点列出函数f的一些选择:
1.内积
函数f的最简单的一种形式就是内积:
f
(
h
i
,
h
j
)
=
θ
(
h
i
)
T
ϕ
(
h
j
)
f(\boldsymbol{h}_i,\boldsymbol{h}_j )=θ(\boldsymbol{h}_i )^T ϕ\ (\boldsymbol{h}_j)
f(hi,hj)=θ(hi)Tϕ (hj)
这里
θ
(
h
i
)
=
W
θ
h
i
θ(\boldsymbol{h}_i )=W_θ \boldsymbol{h}_i
θ(hi)=Wθhi ,
ϕ
(
h
j
)
=
W
ϕ
h
j
ϕ(\boldsymbol{h}_j )=W_ϕ \boldsymbol{h}_j
ϕ(hj)=Wϕhj ,分别表示对输入的一种线性变换,
C
(
h
)
=
∣
h
j
∣
C(\boldsymbol{h})=|\boldsymbol{h}_j |
C(h)=∣hj∣ 。
2.全连接
使用输出为一维标量的全连接层定义
f
f
f :
f
(
h
i
,
h
j
)
=
σ
(
w
f
T
[
θ
(
h
i
)
∣
∣
ϕ
(
h
j
)
]
)
f(\boldsymbol{h}_i,\boldsymbol{h}_j )=σ(\boldsymbol{w}_f^T [θ(\boldsymbol{h}_i )||ϕ(\boldsymbol{h}_j)])
f(hi,hj)=σ(wfT[θ(hi)∣∣ϕ(hj)])
这里
w
f
\boldsymbol{w}_f
wf 是将向量投影到标量的权重参数,
C
(
h
)
=
∣
h
j
∣
C(\boldsymbol{h})=|\boldsymbol{h}_j|
C(h)=∣hj∣ 。
3.高斯函数
使用扩展形式的高斯函数:
f
(
h
i
,
h
j
)
=
e
θ
(
h
i
)
T
ϕ
(
h
j
)
f(\boldsymbol{h}_i,\boldsymbol{h}_j )=e^{θ(\boldsymbol{h}_i )^T ϕ(\boldsymbol{h}_j)}
f(hi,hj)=eθ(hi)Tϕ(hj)
其中
C
(
h
)
=
∑
∀
j
f
(
h
i
,
h
j
)
C(\boldsymbol{h})=∑_{∀j}f(\boldsymbol{h}_i,\boldsymbol{h}_j )
C(h)=∑∀jf(hi,hj) ,对于给定
i
i
i ,
1
C
(
h
)
\frac{1}{C(\boldsymbol{h})}
C(h)1 表示沿维度j进行归一化之后的值,此时
h
i
′
=
softmax
j
(
θ
(
h
i
)
T
ϕ
(
h
j
)
)
g
(
h
j
)
h_i'=\text{softmax}_j (θ(\boldsymbol{h}_i )^\text{T} ϕ(\boldsymbol{h}_j))g(\boldsymbol{h}_j)
hi′=softmaxj(θ(hi)Tϕ(hj))g(hj) 。如果将自然对数
e
e
e 的幂指数项改成全连接的形式,就成了GAT中的做法。
3.4.3 GN
Graph Network [11] 相较于MPNN和NLNN,对GNN做出了更一般的总结。其基本能计算单元包含3个要素: 节点的状态
h
i
h_i
hi 、边的状态
e
i
j
e_{ij}
eij 、图的状态
u
u
u 。Graph Network设计了3个更新函数
ϕ
ϕ
ϕ、3个聚合函数
ρ
ρ
ρ ,具体如下:
e
i
j
′
=
ϕ
e
(
e
i
j
,
h
i
,
h
j
,
u
)
\boldsymbol{e}_{ij}'=ϕ^e (\boldsymbol{e}_{ij},\boldsymbol{h}_i,\boldsymbol{h}_j,\boldsymbol{u})
eij′=ϕe(eij,hi,hj,u)
e
ˉ
i
′
=
ρ
e
→
h
(
[
e
i
j
′
,
∀
v
j
∈
N
(
v
i
)
]
)
h
i
′
=
ϕ
h
(
e
ˉ
i
′
,
h
i
,
u
)
\bar{\boldsymbol{e}}'_i=ρ^{e→h} ([\boldsymbol{e}_{ij}',∀v_j∈N(v_i )]) \boldsymbol{h}_i'=ϕ^h (\bar{\boldsymbol{e}}'_i,\boldsymbol{h}_i,\boldsymbol{u})
eˉi′=ρe→h([eij′,∀vj∈N(vi)])hi′=ϕh(eˉi′,hi,u)
{
e
ˉ
′
=
ρ
e
→
u
(
[
e
i
j
′
,
∀
e
i
j
∈
E
]
)
h
ˉ
i
′
=
ρ
h
→
u
(
[
h
i
′
,
∀
v
i
∈
V
]
)
u
′
=
ϕ
u
(
e
ˉ
i
′
,
h
′
ˉ
,
u
)
\begin{cases}\bar{\boldsymbol{e}}'=ρ^{e→u} ([\boldsymbol{e}_{ij}',∀\boldsymbol{e}_{ij}∈E]) \\ \bar{\boldsymbol{h}}'_i=ρ^{h→u} ([\boldsymbol{h}_i',∀v_i∈V]) \\ \boldsymbol{u}'=ϕ^u (\bar{\boldsymbol{e}}'_i,\bar{\boldsymbol{h'}},\boldsymbol{u})\end{cases}
⎩⎪⎨⎪⎧eˉ′=ρe→u([eij′,∀eij∈E])hˉi′=ρh→u([hi′,∀vi∈V])u′=ϕu(eˉi′,h′ˉ,u)
GN的计算过程如图3-9所示,蓝色表示正在被更新的元素,黑色表示正在参与更新计算的元素。GN的更新思路是非常自然的,由点更新边,边聚合更新点,点聚合与边聚合更新图,当然每个元素在更新的时候还需要考虑自身上一轮的状态。需要注意的是,上述的更新步骤并不是一成不变的,也可以从全局出发到每个节点,再到每条边。另外,全图状态u的初始值,可以看成是图的某种固有属性或者先验知识的编码向量。如果出去这个全图状态的维护,GN就退化成了一个维护边状态的MPNN。

图3-9 GN的计算过程 [1]
GN对图里面的节点、边、全图都维护了相应的状态,这三者可以分别对应上节点层面的任务、边层面的任务、全图层面的任务。当然,在实际场景中,可以依据图数据以及相关任务的实际情况,对GN进行相应的简化处理。
参考文献
[1] Battaglia P W , Hamrick J B , Bapst V , et al.Relational inductive biases,deep learning,and graph networks[J].arXiv preprint arXiv:1806.01261,2018.
[8] Gilmer J,Schoenholz S S,Riley P F,et al.Neural message passing for quantum chemistry[C]//Proceedings of the 34th International Conference on Machine Learning-Volume 70.JMLR.org,2017:1263-1272.
[9] Battaglia P,Pascanu R,Lai M,et al.Interaction networks for learning about objects,relations and physics[C]//Advances in neural information processing systems.2016:4502-4510.
[10] Wang X,Girshick R,Gupta A,et al.Non-local neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2018:7794-7803.
[11] Battaglia P W,Hamrick J B,Bapst V,et al.Relational inductive biases,deep learning,and graph networks[J].arXiv preprint arXiv:1806.01261,2018.
















 1755
1755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









