






Visual Question Answering Dataset for Bilingual Image Understanding:
A Study of Cross-Lingual Transfer Using Attention Maps ——Coling18
文章链接:
https://www.aclweb.org/anthology/C18-1163
概述:该文章主要是考虑到日语vqa的发展几乎没有 于是提出了一种跨语言的vqa model。该文章主要贡献为使用众包的方式建立了一个日文vqa数据集
模型方面用的是Jiasen Lu 的HiCo-attention 唯一一处改动为前面attention部分为英语语料库得到的attention 之后将该attention参数用到后面的基于日语语料库的Hico-attention中 依据为:虽然语言不同, 但基于一个问题,应该观察的图像中的区域位置是相同的 因此 使用英语attention 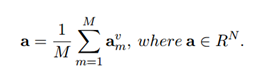 N是N个英语问题 取了attention的平均
N是N个英语问题 取了attention的平均
能够合适地移植入后面的日语Co-attention中。之所以选择英语attention 是为了用上英文VQA数据集的充分性
收获:
- 不同国家因为文化语言的差异 可能问的问题不太一样
- visual Genome 173w图片 1图17QApairs 分为全局问题和局部问题 问题类型六种(wwwwwh) Visual 7W是前者中的全局问题 现在常代替Visual Genome 加了个which
- coco-QA 四种类型问题:object number color location
answer都是一个词 - DAQUAR 1图9QA 数据集特别小
- 它的工作解决的一个方面是 wwwwwwh 在日语中不完全对应 例如 how many在日语中是一个单独的词















 3203
3203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









