







最新版请移步
以下为老版本
这个是我上传到csdn的YOLOv8的整个文件夹(内含yolov8s.pt和yolov8n.pt)
第一步 下载YOLOv8代码
由于官网的数据更新,现在链接只能下载yolov11的代码(v11的代码也可以训练v8的预训练模型),需要yolov8代码可以下载之前上传的CSDN资源
github:YOLOv8-github
gitee:YOLOv8-gitee
推荐使用国内的gitee
第二步 创建conda虚拟环境
如果没有安装conda可以搜索一下conda配置教程,按照流程安装好conda,还要下载好符合自己电脑版本的CUDA 后续会用。
第一步 打开conda窗口 进入到安装的YOLOv8界面
第二步 创建新的虚拟环境
输入下面命令
conda create -n y8 python=3.8

是否安装环境所需基础包,输入y安装即可,安装完成如下图

输入下面命令查看是否创建成功
conda env list

激活进入环境
conda activate y8

激活成功后,前面的base会替换成y8
第三步 安装配置文件
首先先把pip的源换到国内aliyun镜像,下载速度提高很多
pip config set install.trusted-host mirrors.aliyun.com
首先conda环境cd进入ultralytics-main下,在文件夹内有个配置文件requirements.txt 在conda页面使用pip安装一下
注意如果是2024新版yolov8 requirements.txt文件在ultralytics.egg-info文件夹下
pip install -r requirements.txt
很多网友反应requirements.txt没有了,我把内容放在这,复制自己新建一个requirements.txt安装,配置环境。
# Ultralytics requirements
# Usage: pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.22.2 # pinned by Snyk to avoid a vulnerability
opencv-python>=4.6.0
pillow>=7.1.2
pyyaml>=5.3.1
requests>=2.23.0
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.64.0
# Logging -------------------------------------
# tensorboard>=2.13.0
# dvclive>=2.12.0
# clearml
# comet
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=6.0,<=6.2 # CoreML export
# onnx>=1.12.0 # ONNX export
# onnxsim>=0.4.1 # ONNX simplifier
# nvidia-pyindex # TensorRT export
# nvidia-tensorrt # TensorRT export
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TF exports (-cpu, -aarch64, -macos)
# tflite-support
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev>=2023.0 # OpenVINO export
# Extras --------------------------------------
psutil # system utilization
py-cpuinfo # display CPU info
# thop>=0.1.1 # FLOPs computation
# ipython # interactive notebook
# albumentations>=1.0.3 # training augmentations
# pycocotools>=2.0.6 # COCO mAP
# roboflow
我已经安装了一遍,安装完成大概如下图所示
安装完配置文件在安装一下yolov8在python>=3.8版本必要安装包
pip install ultralytics
第四步 下载训练模型,推荐yolov8s.pt或者yolov8n.pt,模型小,下载快,在gitee或者github下方readme里面,下载完成后,将模型放在主文件夹下,
yolov8s.pt下载地址:yolov8s.pt
yolov8n.pt下载地址:yolov8n.pt
YOLOv8 可以在命令行界面(CLI)中直接使用,使用yolov8自带经典图片进行测试:
首先cd进入yolov8主文件夹下,运行下面命令
无显卡驱动
yolo predict model=yolov8n.pt source='ultralytics/assets/bus.jpg' device=cpu
有显卡驱动(看扩展的部分,安装gpu版本torch才能运行)
yolo predict model=yolov8n.pt source='ultralytics/assets/bus.jpg' device=0

我的结果保存在runs\detect\predict4中,你们的看Results saved to 存放地址,结果如下图
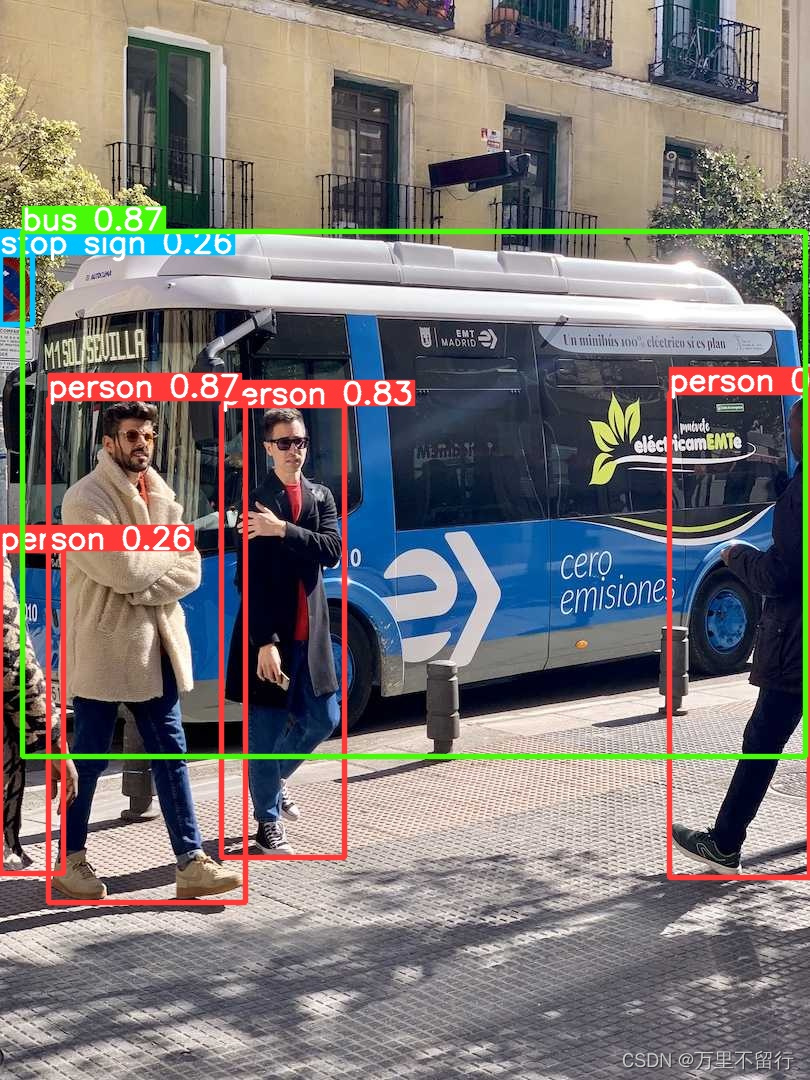
如果出现上面图片即成功
第四步 训练自己模型(cpu)
首先在yolov8主文件夹内创建data文件夹,创建一个data.yaml文件:
这里需要转成yolov8训练集
train: xxx/xxx/images/train //xxx/xxx为训练集图片根目录地址,一定要是绝对路径
val: xxx/xxx/images/val
nc: 1 #标签数量
names: ["1"]#标签名称
conda在主文件夹下运行下面命令:
yolo train data=data/data.yaml model=yolov8s.pt epochs=300 imgsz=640 batch=8 workers=0 device=cpu
data为yaml配置文件
model为下载的模型,放在主文件下
epochs为训练轮数
imagez为训练时ai看到的图片大小,检查大图片建议使用640,小图片可以320 越大越吃性能
batch为一轮训练中每一次放入图片数量,越大越快效果越好,但是对性能要求越高
device为使用的设备,使用cpu练就写cpu,使用显卡大多数都是0,多显卡就0,1,2,3,...多少显卡往后写多少
运行出现下面效果即为成功

扩展:训练自己的模型(GPU)
首先打开命令栏输入nvcc -V,查看自己的cuda版本

在使用nvidia-smi查看是否安装cuda,如果显示没有此命令则没有安装,去CUDA Toolkit Archive | NVIDIA Developer该网站,找到对应版本cuda和系统版本进行下载安装,具体安装步骤可以参考此教程【精选】CUDA安装及环境配置——最新详细版_abbrave的博客-CSDN博客,安装完成后再次输入nvidia-smi出现下图即为成功。
 再去pytorch官网,下载对应cuda版本和操作系统的pytorch,如果找不到对应版本,可以安装低于电脑cuda版本的pytorch。
再去pytorch官网,下载对应cuda版本和操作系统的pytorch,如果找不到对应版本,可以安装低于电脑cuda版本的pytorch。
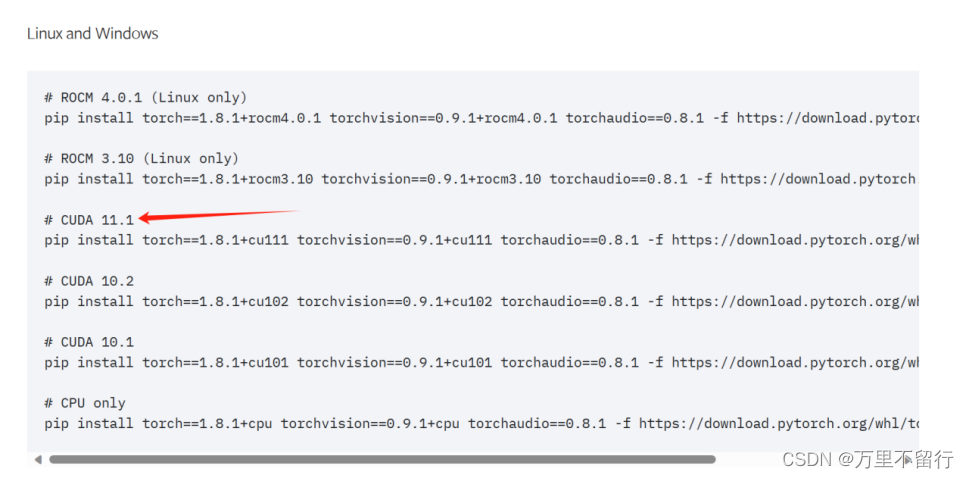
例如图cuda11.1 在conda中创建的虚拟环境运行下面对应的pip安装,在安装命令后面加上-i https://pypi.douban.com/simple/ some-package 使用国内下载源进行下载大大减少下载时间,等他下载完,在当前conda安装环境输入pip list找到torch+torchaudio+torchvision三个包,如下图在版本后带有+cuxxx即为安装成功。

输入下面代码进行测试,如果有多个显卡,在device=0,1,2…
yolo train data=data/data.yaml model=yolov8s.pt epochs=300 imgsz=640 batch=8 workers=0 device=0

可以运行,并且在运行时显示显卡型号即为成功。
如果还有问题可以添加下面vx备注yolov8,我拉个群聊大家一起讨论



















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









