







在很多语言中,都会利用“目录”来规范开发者分层的逻辑。
比如Javaweb中,会将目录分为Controller,Service,Dao,Model等等。
利用目录的形式对开发者进行约束,能够使代码整体结构更加清晰,功能分工更加明确。
我一直“以为”我对分层的感受能力还是很强的,但是回顾上星期写的代码,才让我感觉我对分层的理解一直停留在表面。
大家都知道:
在逻辑上,可能使用概念分层,比如AO,DAO;
在功能上,可能使用模块名进行约束,比如xxx_order、xxx_log;
进一步到代码上,利用目录进行分层,比如xxx_logic、xxx_model;
但是,我觉得上述的方式对于开发者来说(尤其是团队协作),都太宽泛了,对实际开发行为上难以进行“接口级别的约束”,但团队开发,互调接口却是很常见的。
如果在一开始并没有明确、协商好接口的参数返回值,就需要开发者自己理解不同层面的接口应该传递哪种粒度的对象。(我觉得主导者预先设计好接口是必要的,但是执行者自己也能理解其深意也是必须的)。
以我当前参与的项目为例,我需要实现model层(我理解为数据访问层)的逻辑功能,(代码)分层如下:
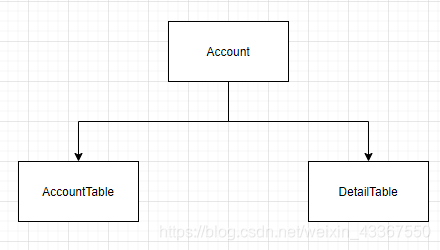
顶层的Account提供给外部使用,封装了账户的所有操作(流水只是账户变动的附加记录,理论上也是Account本身的熟悉),Account再利用AccountTable操作具体的账户表,利用DetailTable操作具体的流水表。
分层非常清晰,但是真正写起来会有很多“操作粒度”层面的问题(设计者没有提供接口的参数,需要我自己去思考)。
比如:
- 修改时的幂等校验,放在Account里面还是两个Table对象里面?为什么?
- 可以将查询的参数filter对外提供吗?在接口上作为参数传递进来(filter类似一个Map,相当于mysql where条件的实例)
- 不同的数据状态,在Account就进行(统一)分支还是下沉到两个Table中?
……
上面的问题似乎跟分层无关,但是我觉得这是“概念分层”无法掌控的细粒度分层。
-
如果把幂等校验放在Account里面,需要同时对AccountTable和DetailTable进行幂等校验,这时候需要操作两次数据库。将“意外拦截在了最外层”似乎很美好。
但是,当幂等校验通过后,进入到两个Table中之后,又要重复操作一次数据库,拿到在Account就已经拿到的对象,这显然非常不好,当然可以选择在Account就把参数传递下去,但是一开始没想到呢? -
我一开始就是把filter提供给了外部,这样对于查询,我只需要写一个接口,外部想要查询什么,自己构造filter即可。但是这个很容易想到,破坏了功能上的封装性,调用者需要熟悉库表结构才能准确操作该接口,这显然加大了整体的开发难度。
-
我一开始是在Account中进行统一分层,但是统一分层会使得局部代码快速膨胀,分支过多难以理解,结构不清晰,最终选择各个方法自行处理状态分支。
我觉得,分层应该不仅仅是宏观层面的概念,不能停留在目录分层的层面。
对个人来说,实现时的逻辑分层更重要,开发阶段就应该注意逻辑分层的抉择,尽量满足开闭原则,才能写出容易理解、结构清晰、易扩展的代码。














 2673
2673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









