







使用Python获取高德POI数据,并使用MySQL建立本地空间数据库(一)
本方法仅供参考和学习交流使用,切勿用于商业用途
关于高德POI
在常用的互联网地图中,POI代表兴趣点,可以是楼宇、小区、商店、银行、学校等等,其提供的附带信息较为丰富,常有的有“地址”、“经纬度”、“POI类型”等。互联网地图强大的POI数据库,为互联网地图应用提供强大的使用空间。高德提供了千万级别的POI,通过POI搜索,可以完成找银行,找餐馆、找景点等等的功能,包含了关键字搜索、周边搜索、多边形搜索等等。这些功能依托于强大的数据库和空间数据引擎实现,本文将以高德POI为例,以Python为开发语言,以MySQL为数据库,阐述如何大范围获取详细的高德地图POI数据,并建立MySQL空间数据库,完成简单应用。
高德地图搜索POI的接口
高德地图的POI搜索依托于高德地图的搜索服务,搜索服务API是一类简单的HTTP接口,提供多种查询POI信息的能力,其中包括关键字搜索、周边搜索、多边形搜索、ID查询四种筛选机制。
- 使用API前您需先申请Key,申请时选择web服务,将会获取用于搜索的key,具体内容详见高德开发文档。
- 搜索API服务地址:
https://restapi.amap.com/v3/place/text?parameters请求方式为GET,parameters代表的参数包括必填参数和可选参数。所有参数均使用和号字符(&)进行分隔。 - 例如:
https://restapi.amap.com/v3/place/text?keywords=北京大学&city=beijing&output=xml&offset=20&page=1&key=<用户的key>&extensions=all代表了一个完整的POI请求。 - 关于接口的使用和参数的详细情况,请详见开发API文档。
抓取高德POI的思路
总体来讲,高德POI的搜索分为两类,第一种是按照城市和POI类型来检索,比如搜索北京市的购物类POI;另一种是按照区域(指定的矩形范围,按照经纬度坐标划分)和类型来检索。这两检索方式的选择直接决定了能否完整检索出想要的所有POI数据。
高德对搜索服务做了限制,无论指定多少个类型,每次请求最多返回1000个POI信息,若场景需要获取更可能多的POI;建议不要指定过多的类别,而是分多次请求从而得到更加准确的结果。
所以想要完整抓取POI数据,必须保证以下三个方面:
- 按照指定区域来搜索
- 保证每次搜索的数据返回量少于1000条
- 搜索类型不要太多,建议单类型循环搜索
因此,POI检索核心是针对检索区域,构建若干个矩形格网,格网的构建没有具体要求,只要保证单个格网POI检索的数据量少于1000即可,主城区核心地带格网可以小一些,郊区或者山区等格网可以大一些。
本文采用ArcGIS构建了矩形格网,包括了整个下载区域。
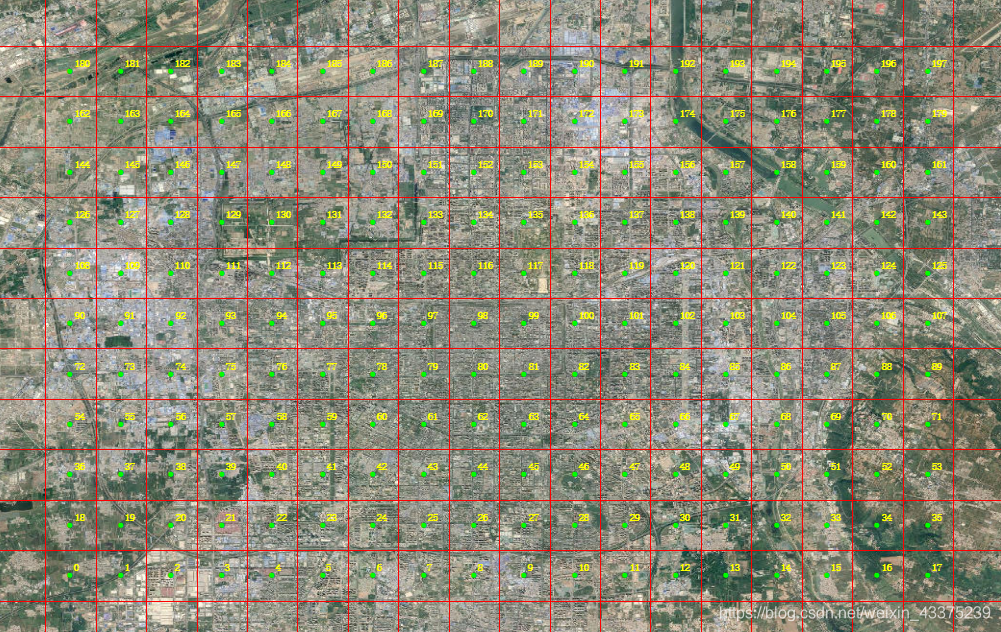
如果觉得手动创建格网很麻烦,可以直接采用一个大的矩形,然后不断进行22的分割,递归进行,创建四叉树,保证最小分割格网的搜索返回数小于1000即可。具体实现这里不在赘述,我采用的是手动创建格网的方法,格网大小约2km2km。
高德POI抓取的Python实现
代码实现的基本思路是按照格网分割得到的矩形坐标,循环请求不同区域、不同类型的POI数据,然后进行合并处理。废话不说,上代码先
import xlrd # 读xlsx
import xlsxwriter # 写xlsx
import urllib.request # url请求,Python3自带
import os # 创建output文件夹
import glob # 获取文件夹下文件名称
import time # 记录时间
import json # 读取json格式文件
def xlsx_merge(folder,header,filename):
fileList = []
for fileName in glob.glob(folder + "*.xlsx"):
fileList.append(fileName)
fileNum = len(fileList)
matrix = [None] * fileNum
for i in range(fileNum):
fileName = fileList[i]
workBook = xlrd.open_workbook(fileName)
try:
sheet = workBook.sheet_by_index(0)
except Exception as e:
print(e)
nRows = sheet.nrows
matrix[i] = [0]*(nRows - 1)
nCols = sheet.ncols
for m in range(nRows - 1):
matrix[i][m] = ["0"]* nCols
for j in range(1,nRows):
for k in range(nCols):
matrix[i][j-1][k] = sheet.cell(j,k).value
fileName = xlsxwriter.Workbook(folder + filename + ".xlsx")
sheet = fileName.add_worksheet("merged")
for i in range(len(header)):
sheet.write(0,i,header[i])
rowIndex = 1
for fileIndex in range(fileNum):
for j in range(len(matrix[fileIndex])):
for colIndex in range (len(matrix[fileIndex][j])):
sheet.write(rowIndex,colIndex,matrix[fileIndex][j][colIndex])
rowIndex += 1
print("已完成%d个文件的合并"%fileNum)
fileName.close()
# 本函数完成获取POI
def poi_by_adcode_poicode(folder,city_file = "polygon",poi_file = "poi",result_file = "result",merge_or_not = 1):
key="这里输入你的key"
count=0
city_file = city_file
poi_file = poi_file
merge_or_not = merge_or_not
header_full = ["id","name","type","typecode","biz_type","address","location","tel","pname","cityname","adname","rating","cost"]
header = ["id","name","type","typecode","biz_type","address","location","tel","pname","cityname","adname"]
offset = 25 # 实例设置每页展示10条POI(官方限定25条)
output_folder = folder + "output/"
# 创建输出路径
if os.path.isdir(output_folder):
pass
else:
os.makedirs(output_folder)
# 读取列表
city_sheet = xlrd.open_workbook(folder+ "input/" + city_file + ".xlsx").sheet_by_index(0)
poi_type_sheet = xlrd.open_workbook(folder+ "input/" + poi_file + ".xlsx").sheet_by_index(0)
city_list =city_sheet.col_values(0)
city_code_list = city_sheet.col_values(1)
upleftjd=city_sheet.col_values(1)
upleftwd=city_sheet.col_values(2)
rightbottomjd=city_sheet.col_values(3)
rightbottomwd=city_sheet.col_values(4)
jd = city_sheet.col_values(6)
wd = city_sheet.col_values(7)
poi_type_list = poi_type_sheet.col_values(1)
poi_type_name=poi_type_sheet.col_values(0)
result_file = result_file+str(poi_type_name[1])
# 指示工作完成量
total_work = (city_sheet.nrows - 1) * (poi_type_sheet.nrows - 1)
work_index = 1
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())) + ":抓取开始!")
for city_index in range(1,len(city_list)):
for poi_type_index in range(1,len(poi_type_list)):
workbook =xlsxwriter.Workbook(output_folder + str(city_list[city_index]) +"_"+ str(poi_type_list[poi_type_index])+"_"+ str(jd[city_index])+"_"+str(wd[city_index])+ ".xlsx") # 新建工作簿
sheet = workbook.add_worksheet("result") # 新建“poiResult”的工作表
for col_index in range(len(header_full)):
sheet.write(0,col_index,header_full[col_index]) # 写表头
row_index = 1
for page_index in range(1, 101):
try:
#以下是请求POI
url = "http://restapi.amap.com/v3/place/polygon?types=" + str(poi_type_list[poi_type_index]) + "&polygon=" + str(round(upleftjd[city_index],6))+","+ str(round(upleftwd[city_index],6))+"|"+ str(round(rightbottomjd[city_index],6))+","+ str(round(rightbottomwd[city_index],6))+"&offset=" + str(offset) + "&page="+ str(page_index) +"&key="+str(key)+"&extensions=all&output=json"
data = json.load(urllib.request.urlopen(url))["pois"]
count=count+1
for i in range(offset):
for col_index in range(len(header)):
sheet.write(row_index, col_index, str(data[i][header[col_index]]))
sheet.write(row_index,len(header),str(data[i]["biz_ext"]["rating"]))
sheet.write(row_index,len(header) + 1,str(data[i]["biz_ext"]["cost"]))
row_index += 1
except:
break
print("已完成:" + str(poi_type_list[poi_type_index]))
workbook.close()
print(str(city_list[city_index]) + " " + str(poi_type_list[poi_type_index] )+ " 已获取!进度:%.2f%%" %(work_index / total_work *100))
work_index += 1
print( "所有地区各类别POI获取完毕")
print("搜索次数:"+str(count))
if merge_or_not == 1:
xlsx_merge(output_folder, header_full, result_file)
print("已对文件进行合并!")
else:
print("未进行合并!")
print("所有工作完成!")
poi_by_adcode_poicode("E:/poi/","中部", "poi中部", "中部", 1)
程序input:
- 1、poi的格网划分文件
在这里主要使用表格的第2、3、4、5列,分别标示了左上角和右下角的经纬度坐标,用来确定单个格网的位置。

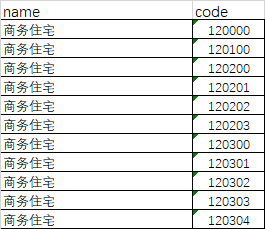
- 2、poi分类文件
name表示搜索的poi类型,code代表了该类型的代码分类
程序output:
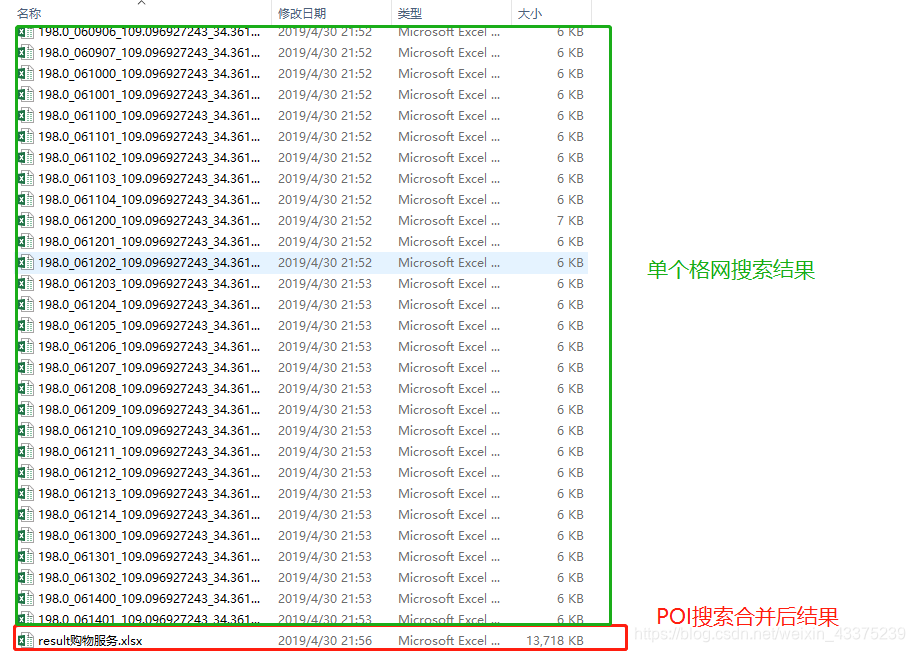
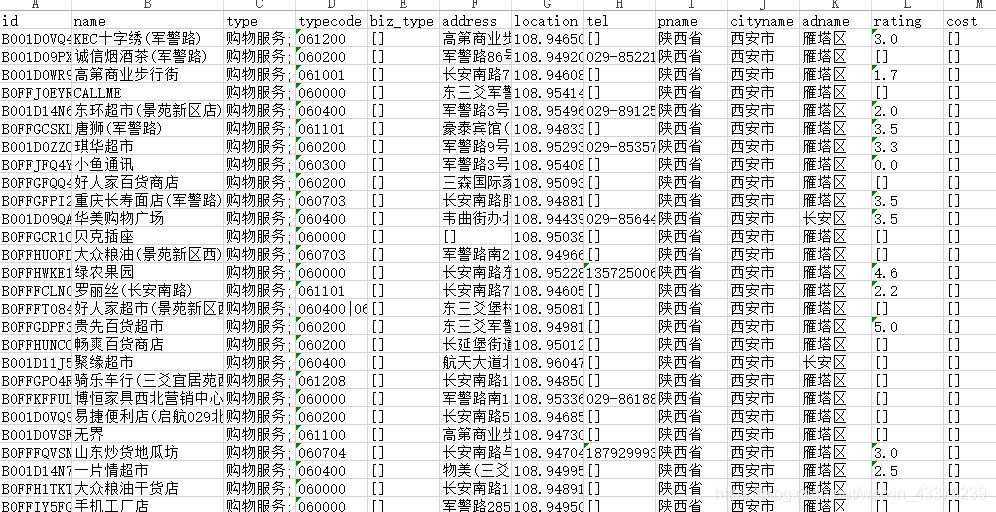
代码部分的内容很简单,提供源码和相关输入格式的下载
本部分主要是如何抓取poi数据,下一篇将以poi数据为例,创建空间数据库,完成基本的数据操作和空间分析。

















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









