






~~~~ 商家追踪和分析用户的购买行为,是希望对用户购买行为的研究,从而识别出机会和问题,进行明智的商业决策。每个用户往往都有着其不同的用户生命周期,企业公司都不希望自己的用户流失,并且希望他们能够在生命周期中创造更大的价值。因此在这一过程中,对于不同类型的用户,都必须采取必要的措施,使用用户流失模型来识别和预测待流失的用户;使用用户价值模型对创造价值较多的用户进行识别和引导创造更多的价值。在本次数据分析中,利用一个简单的例子来分析用户流失以及用户生命周期。
~~~~ 数据来源《Tableau商业分析》中RFM分析中的数据源,利用Tableau和python进行本次的数据分析,建立RFM以及聚类模型划分用户,筛选待针对的价值用户以及流失用户。
~~~~ 首先调用相关的包,并对数据进行观察
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('RFM分析.csv',encoding = 'GB2312',delimiter='\s')
print(len(df))
df.head()
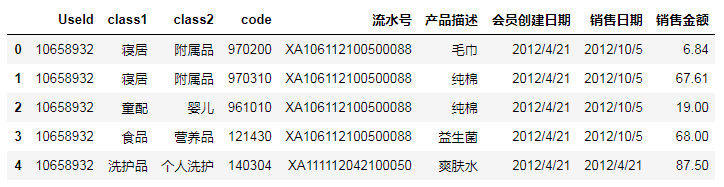
293157
~~~~
数据总共为293157条,包含9个特征,分别是用户id,商品大类,商品小类,商品id,流水号,产品描述,会员创建日期,销售日期,以及销售金额。接下对数据进行观察并做预处理。
df.describe()

df.info()

~~~~
可以看到在销售金额中存在着负数,这可能是退货的订单,需要进行筛选。另外一些特征的属性需要更改,例如需要把销售日期和会员创建日期改变为时间维度。
#处理时间维度
df['会员创建日期'] = pd.to_datetime(df['会员创建日期'])
df['销售日期'] = pd.to_datetime(df['销售日期'])
df.UseId = df.UseId.astype('object')
df.code = df.code.astype('object')
df_buy = df[df['销售金额']>0]
df_refund = df[df['销售金额']<0]
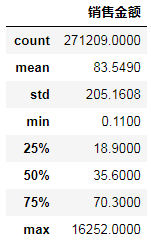
df_buy.describe()
~~~~
可以看出销售金额平均为83.54,而百分之75的订单都在平均值之下,表明存在了一些购买力极强的用户。我们可以将图做出来会更加明显。
df_buy['销售金额'].hist(figsize=(10,6),bins=100,color='c')
df_buy[df_buy['销售金额']<200]['销售金额'].hist(figsize=(10,6),bins=10,color='c')
df_buy[df_buy['销售金额']>2000]['销售金额'].hist(figsize=(10,6),bins=10,color='c')



~~~~
在第一张图中可以看出很明显的长尾效应,取了销售金额小于200的数据可以看出大部分的销售金额都集中在0到50,而到了销售金额2000的部分,数量则大为减少,另外,还存在几条销售金额大于10000订单。

~~~~
将其打印出来可以看到是两笔购买奶粉的订单,而其购买的原因不得而知,如果有相关的数据可以进行分析是否为异常数据。在这里我暂时将其当做为异常数据过滤掉。
df_refund.hist(figsize=(10,6),bins=100,color='c')
plt.ylabel('SumPrice of refunds(beyong -1000)')
df_refund[df_refund['销售金额']>-200].hist(figsize=(10,6),bins=100,color='c')
plt.ylabel('SumPrice of refunds(beyong -1000)')
df_refund[df_refund['销售金额']<-1000].hist(figsize=(10,6),bins=100,color='c')
plt.ylabel('SumPrice of refunds')



~~~~
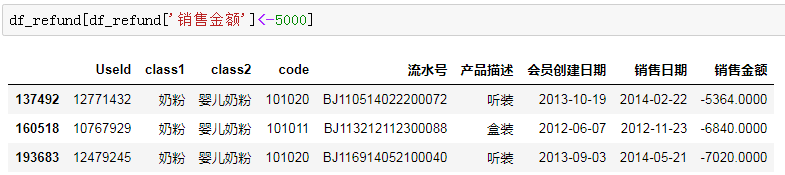
在退货订单的数据中,可以看出大部分的退货订单金额都集中100以内,另外也出现了一些退货金额较大的订单,可以看出最大的可以达到7000的退货单,同样我们来看下是什么。



~~~~
退货的商品同样是奶粉,我们对这些用户进行观察,可以发现三名用户有两名在退货的同时又购买了另一批奶粉,另外一名用户在购买历史中从没有买过奶粉,但是却买了7020元的奶粉并且购买之后就退货了,其原因如果有更过的数据进行挖掘可能会很有意思。
~~~~ 接下来,开始对商品价格展开一系列的可视化以及分析
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
#画图显示中文
df_buy = df_buy[df_buy['销售金额']<10000]
class_buy_rate = df_buy.groupby('class1')['UseId'].count().reset_index().rename(columns = {'UseId':'buy_count'})
class_refund_rate = df_refund.groupby('class1')['UseId'].count().reset_index().rename(columns = {'UseId':'refund_count'})
class_buy_rate['buy_count'] = class_buy_rate['buy_count'].apply(lambda x:x/len(df_buy))
class_refund_rate['refund_count'] = class_refund_rate['refund_count'].apply(lambda x:x/len(df_refund))
class_count=pd.merge(class_buy_rate,class_refund_rate,on='class1')
class_count = class_count.sort_values('buy_count',ascending = False)
fig = plt.figure(figsize=(15,5))
plt.bar(class_count['class1'],class_count['buy_count'],label='buy_rate')
plt.plot(class_count['class1'],class_count['refund_count'],color = 'r',label = 'refund_rate')
plt.legend(loc='best')
plt.ylabel('Rate')

~~~~
计算各个商品的购买比例,在下单的比例上,食品下单数最多其次是洗护品喂养等。在退货比例上,婴装和童装的退货订单比例最高,另外童鞋相比于其购买比例上,退货比例也较高,这类商品应该关注其退换原因。
def high_refund(data):
code= data.code.unique()
refund_store = defaultdict(int)
store = defaultdict(int)
for i in range(len(data)):
#print(data['code'][i])
store[data['code'][i]] += 1
if data['销售金额'][i] < 0:
refund_store[data.code[i]] += 1
print(len(refund_store))
pd_refund_store = pd.DataFrame(pd.Series(refund_store),columns = ['refund_count']).reset_index().rename(columns = {'index':'class1'})
print(len(pd_refund_store))
pd_store = pd.DataFrame(pd.Series(store),columns=['count']).reset_index().rename(columns={'index':'class1'})
result = pd.merge(pd_store,pd_refund_store,on='class1')
result['refund_rate'] = result['refund_count']/result['count']
return result
yingz = df[df['class1']=='婴装'].reset_index()
baby_class = high_refund(yingz)
baby_class['class1'] = baby_class['class1'].astype('str')
plt.figure(figsize=(16,7))
plt.plot(baby_class['class1'],baby_class['refund_rate'])
plt.xticks(rotation = 45)
plt.ylabel('退货比例(婴装)',fontsize=20)


~~~~ 在退单比例较高的三个大类婴装、童装、童鞋中进行退单率的观察,可以看出有些商品比同一类别中其他商品的退单率高,这些商品是应该重点关注的对象,研究其退单率高的原因。
df_buy_sum = df_buy.groupby('class1').agg(['sum','count'])['销售金额'].reset_index()
df_buy_sum['平均购买价格'] = df_buy_sum['sum']/df_buy_sum['count']
df_buy_sum = df_buy_sum.sort_values('sum',ascending=False)
fig,ax1 = plt.subplots(figsize=(16,7))
ax2 = ax1.twinx()
ax1.bar(df_buy_sum['class1'],df_buy_sum['sum'],label='销售总金额')
ax2.plot(df_buy_sum['class1'],df_buy_sum['平均购买价格'],color = 'r',label = '销售平均金额')
plt.legend(loc='best')
plt.ylabel('销售情况')
df_buy[(df_buy['class1']=='奶粉')&(df_buy['销售金额']<600)].hist(bins=50)



~~~~
对商品销售的总额以及平均价格进行分析,由于数据的金额是每笔订单的价格,因此无法求得每个商品的单价,只能知道每笔订单的价格,由图可知在销售金额的总量上,奶粉遥遥领先,其次是食品以及其他的一些日用品。从平均销售金额可以发现每笔奶粉的平均销售金额可以达到400以上,将类别为奶粉的提取出来可以大部分的销售金额处于100-300之间,而销售平均值处于销售金额在50%到75%之间,这可以说明存在部分购买力比较强的用户,拉高了平均值。
~~~~ 以上是关于商品销售的基本情况,主要是商品总体的销售情况,其中需要重点关注的是婴儿儿童产品的退单情况,奶粉销售以及大批量购买奶粉的用户。
利用RFM模型挖掘用户价值
~~~~ RFM模型是一种起源于零售行业的分析方法,用于衡量用户商业价值的一种思维方法。RFM分析方法比较简单但是却非常高效,通过影响企业销售和利润的客户行为中最重要的三个变量:R(Recency),指客户最近一次购买商品的时间,代表用户粘性;F(Frequency),指客户购买商品的次数,代表用户忠诚度;M(Monetary)指客户购买商品的总金额,代表用户所带来的价值收益,以此来对用户进行划分,从而发现具有不同价值的不同客户群体典型特征。

~~~~
根据RFM各指标的程度可以对用户进行分类,根据分类的结果可以知道哪些是高价值用户,哪些是低价值用户以及哪些高价值需要去挽留挽回,而哪些用户有发展成为高价值用户的潜力。
~~~~
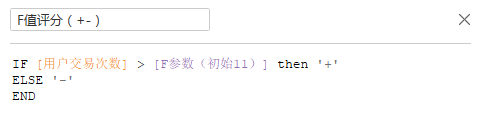
这里使用tableau并用python辅助进行完成。首先是用户交易次数也就是(F)
~~~~
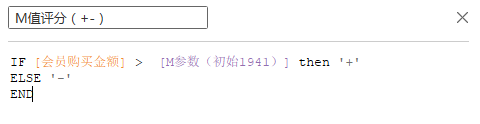
然后是用户购买金额(M)
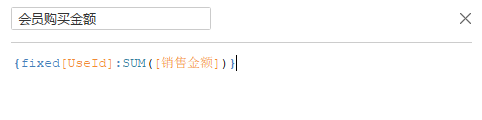
~~~~
最后是最近一次购买时间(R),首先要计算用户最后一次下单时间,然后算最后下单时间到当前时间点的距离,这里的时间点取的是最大的销售时间。
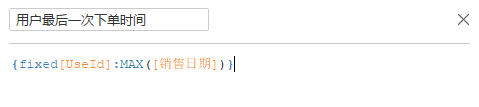
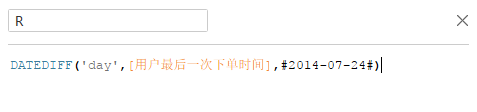
~~~~
对于每个指标的分级有着不同的方法,在这里我选取了2/8分的法则,在每个指标前20%的用户标记为+,其余的标记为-。利用python找出各个指标位于前20%的界限。另外,Tableau的好处在于可以设置参数,将2/8法则找到的界限作为初始,然后可以通过人为地更改这个界限并迅速能够观察到更改后的图示,增大了数据分析的自由度,因此在这里设置每个指标的参数。
~~~~
首先利用python找出各个指标的界限
df_buy_f = df_buy_f.groupby('UseId').count()['流水号'].reset_index()
df_buy_f = df_buy_f.sort_values('流水号').reset_index()
n = df_buy_f.shape[0]
print(df_buy_f['流水号'][int(0.8*n)])
#F值界限为11
df_buy_m = df_buy.groupby('UseId').sum()['销售金额'].reset_index().sort_values('销售金额').reset_index()
m_n=df_buy_m.shape[0]
print(df_buy_m['销售金额'][int(0.8*n)])
#M值界限为1941.1999999999998
df_buy_r = df_buy.groupby('UseId').max()['销售日期'].reset_index()
max_date = df_buy['销售日期'].max()
df_buy_r['r'] = max_date - df_buy_r['销售日期']
df_buy_r['r'] = df_buy_r['r'].apply(lambda x:x.days)
df_buy_r = df_buy_r.sort_values('r').reset_index()
r_n = df_buy_r.shape[0]
print(df_buy_r['r'][int(0.2*r_n)])
#R值界限为42
~~~~
找到这些值后设置参数:



~~~~
然后对用户进行正负的评级:
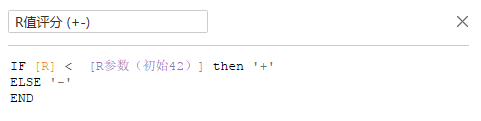
 ~~~~
接下来便可以利用Tableau对数据进行展示:
~~~~
接下来便可以利用Tableau对数据进行展示:
~~~~
通过Tableau制作了仪表盘,首先对每张图进行分析。
~~~~
左上角表示不同类型用户的数量以及他们的总销售金额,可以看出流失用户占到了65.9%,他们贡献了15.7%的销售金额,流失用户更好的解释可以说是价值比较低的用户,属于他们的群体的很多但是平均销售金额不高,类似于商品的长尾效应,他们单个带来的收益也许很低,但是总和不可小觑,如果能够利用小成本维持这些用户,也能够积累到比较高的收益;高价值用户以及重要换回用户分别占7.6%和8.5%,但却分别贡献了36.8%和31.6%的销售金额,基本符合2/8法则,可以说这两部分是需要重点关注的高价值用户,而其两者的区别可以从后面的图来分析。另外,重要深耕用户以及重要挽留用户比例比较低,但是平均销售金额却比较高,如同其字面意思一样,这类需要去深度挖掘以及挽留。
~~~~
左下角的图根据用户生命周期以及销售金额作散点图,圆圈的大小代表R,R越小距离上次购买的时间越近圆圈更大。高价值用户会比重要挽回用户具有更大的圆圈大小,重要挽回用户在他们的购买生命周期中次数金额较大,但是最近的购买次数减少,因此对于这类用户应该研究其流失趋势的原因,并且采取措施进行挽回,同样重要挽留用户也应当作类似的研究。
~~~~
右上角的图用于分析不同用户类型对不同品类购买的分析,可以看出不同用户购买商品的偏向类似,主要集中在奶粉食品以及洗护品上,而对于重要深耕用户以及重要挽留用户来说,他们相比于高价值用户或者其他用户更集中于购买奶粉,因此如何将其对购买奶粉依赖的同时使其也能够更多地购买商品可能会使得这类用户带来的收益更大。
~~~~
右下角是属于时间维度上的观察,通过选定不同用户类型可以发现,高价值用户的销售金额呈现逐渐升高的趋势,而重要挽回用户在2013年底开始呈现略微下降的趋势,而流失用户以及重要挽留用户在最近的时间段开始没有购买行为,通过时间维度可以找出用户发现转变的时间点,从而进行针对性分析,以下是一些仪表盘中操作的示例图:



~~~~
仪表盘中右边的图例中,可以对RFM三个指标划分±的界限进行自定义,可以放宽或者紧缩规则从而达到想要效果。
~~~~
筛选出这些用户之后,可以针对每个类别在进行细分,根据一些用户的基本信息和特征作用户画像从而更好地锁定用户,而这些所有的准备工作都是后续精细化运营的基础。
以上可视化图片已发布到我的Tableau Public:https://public.tableau.com/profile/zhu.tk#!/vizhome/RFM_15677380434720/3
购物篮分析
~~~~
购物篮分析是关联分析一种具体的应用,用于挖掘用户的购买数据从而找出用户的购买模式。关联规则能够反映一个事物与其他事物之间的关系,如果一些事物之间存在关联,那么其中一个事物就能被其他事物所预测。关联规则能够用于挖掘数据之间的相关关系。其中,Apriori算法是一种典型的关联算法。Apriori的原理简要来说就是一句话:任一频繁项的所有非空子集也必须是频繁的。
~~~~
关联分析一般需要计算以下数值:
~~~~
支持度(support):support(A=>B) = P(A∪B),表示A和B同时出现的概率。
~~~~
置信度(confidence):confidence(A=>B)=support(A∪B) / support(A),表示A和B同时出现的概率占A出现概率的比值。
~~~~
频繁项集:在项集中频繁出现并满足最小支持度阈值的集合,例如{牛奶、面包},{啤酒、尿布}等。
~~~~
首先通过迭代找出所有频繁项集,然后再计算置信,根据指定的置信度筛选出强关联规则。
~~~~
在这里直接使用Mlxtend库中的frequent_patterns模块实现Apriori算法和挖掘关联规则:
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
def record(df,list_):
item_store = []
for i in df['class2']:
item_store.append(i)
item_store = list(set(item_store))
list_.append(item_store)
return len(df['class2'].unique())
item_stores = []
df_buy.groupby('流水号').apply(lambda x:record(x,item_stores))
item_stores

item_stores输出了每笔流水号中同时够购买的商品组合,然后就可以利用Mlxtend进行处理了。
te = TransactionEncoder()
te_ary = te.fit(item_stores).transform(item_stores)
item_te = pd.DataFrame(te_ary, columns=te.columns_)
frequent_itemsets = apriori(item_te, min_support=0.02,use_colnames=True)
rules = association_rules(frequent_itemsets, min_threshold=0.2)

~~~~
根据class2进行关联规则,从中找出以上这几种关联性比较强的组合,可以看出并没有很奇妙的组合出现,都是属于很简单的组合,在这里lift表示提升度,它的计算公式是:support(A∩B) / (support(A)*support(B)),提升度越大表示关联性越强。
~~~~
对class1进行关联规则的分析,结果如下:

~~~~
同样也可以用Tableau进行绘制:

~~~~
以上是class1大类中的强关联规则,可以看出一旦用户对平台产生粘性,他们会自己baby一部分成长费用都花在平台上,例如婴儿产品和幼儿产品的关联,婴装和童装的关联等,另外有着相同作用对象的产品也能产生强关联,例如喂养和洗护品等。依据购物篮分析可以对商品进行捆绑销售或者对用户进行推荐。
总结
~~~~ 本文主要利用python以及Tableau对一批电商平台的销售数据进行分析,涵盖了基本的描述性统计、商品购买退货情况、利用RFM对用户分群以及购物篮分析。
~~~~ 1)通过基本的描述性统计分析以及商品退换货情况,计算了不同类型商品的销售情况,以及一些需要重要关注的商品类型例如奶粉、婴装、童鞋等。
~~~~ 2)利用RFM模型对用户进行分群,筛选出了一批高价值用户,并且观察一些用户可能流失以及一些可能能成为高价值的用户。用户分群后续可以根据用户的属性进行用户画像,为后续的精细化运营作基础,有利于提供以消费者为导向的消费模式。
~~~~ 3)通过关联规则分析商品购买之间的联系,找出关联性比较强的商品组合,能够通过商品捆绑提高销量,也能够为用户进行商品推荐。















 5371
5371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









