







机器学习笔记
文章目录
一. 绪论
框架

可以这么理解, 监督学习通过训练集获得模型, 然后根据模型来预测位置的数据; 无监督学习是输入一堆没有标签的数据, 通过模型输出分好类(贴了标签)的数据; 而强化学习是在交互过程中持续进行的过程, 目的是使回报尽量达到最大化.注意当模型中无人为超参时, 不需要设置验证集.
基本概念
误差
模型输出与真值的偏离程度, 在模型中以损失函数表示
- 经验误差: 训练集上的误差, 体现对训练集的 拟合能力
- 泛化误差: 未知样本上的误差, 体现对未知数据的 预测能力
过拟合与欠拟合
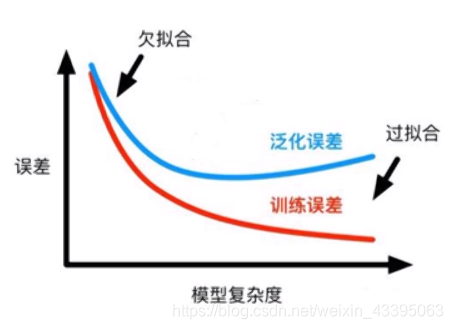
- 过拟合: 模型过于贴近训练集导致对验证和测试的数据产生较大误差
- 欠拟合: 训练和预测的时候都不太行
评估
hold-out 留出法评估
将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另外一个作为测试集T,即D=S∪T,S∩T=0.在S上训练出模型后,用T来评估其测试误差,作为对泛化误差的评估.需要注意保持两个集合数据分布的一致性
cross validation S-交叉验证
把样本数据随机的分成S份,每次随机的选择S-1份作为训练集,剩下的1份做测试集。当这一轮完成后,重新随机选择S-1份来训练数据。若干轮(小于S)之后,选择损失函数评估最优的模型和参数。
可以大致理解为, 将D分为互斥的s份, 每一份采用hold-out评估, 最后误差取平均值.
bootstrap自助法
假设给定的数据集包含d个样本。该数据集有放回地抽样m次,产生m个样本的训练集。这样原数据样本中的某些样本很可能在该样本集中出现多次。没有进入该训练集的样本最终形成检验集(测试集)。 显然每个样本被选中的概率是1/m,因此未被选中的概率就是
(
1
−
1
m
)
(1-\frac{1}{m})
(1−m1),这样一个样本在训练集中没出现的概率就是m次都未被选中的概率,即
(
1
−
1
m
)
m
(1- \frac{1}{m})^m
(1−m1)m。当m趋于无穷大时,这一概率就将趋近于
e
−
1
=
0.368
e^{-1}=0.368
e−1=0.368,所以留在训练集中的样本大概就占原来数据集的63.2%。
可以看到, 自助法它 适用于小的数据集, 在评估过程中也不会减小训练集S的规模, 但是他改变了数据集的分布, 所以会带来一定的误差
性能度量
这里想要补充一下分类和聚类. 可以这样理解: 分类的输入时有标签但是无分组的数据, 处理的时候需要根据数据的标签将同标签类的数据归入同一组, 如开头所说分类是一种监督学习的方法; 聚类的输入并没有表示类别的标签, 在处理时也不需要关心数据将会具有哪些标签, 只是把相似的数据聚到一起, 无监督学习需要聚类算法将数据聚到一起.
分类模型的性能度量
混淆矩阵
用于比较分类结果和实例的数据的差距
这里, 用T(Ture)表示预测正确, F(False)表示预测错误, P表示二分类中的正例, N表示负例;譬如测对的正例就是TP, 依次类推.
- 准确率: a c c u r a c y = T P + T N T P + F P + T N + F N ( 测 对 的 数 在 总 数 中 的 占 比 ) accuracy=\frac{TP+TN}{TP+FP+TN+FN}(测对的数在总数中的占比) accuracy=TP+FP+TN+FNTP+TN(测对的数在总数中的占比)
- 精确率: p r e c i s i o n = T P T P + F P ( 测 对 的 正 例 数 在 总 数 中 的 占 比 ) precision=\frac{TP}{TP+FP}(测对的正例数在总数中的占比) precision=TP+FPTP(测对的正例数在总数中的占比)
- 召回率: R e c a l l = T P T P + F N ( 测 对 的 正 例 在 所 有 正 例 中 的 占 比 ) Recall=\frac{TP}{TP+FN}(测对的正例在所有正例中的占比) Recall=TP+FNTP(测对的正例在所有正例中的占比)
- F-score: ( 1 + β 2 ) p r e c i s i o n × r e c a l l β 2 × p r e c i s i o n + r e c a l l ( 准 确 率 与 精 确 率 的 带 权 重 调 和 ) (1+\beta^2)\frac{precision\times recall}{\beta^2\times precision+recall}(准确率与精确率的带权重调和) (1+β2)β2×precision+recallprecision×recall(准确率与精确率的带权重调和)
- F1-score: 准确率与精确率的同权重调和, 即 β = 1 \beta = 1 β=1的F-score
- 真正率: T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP
- 假正率: F P R = F N T N + F P FPR=\frac{FN}{TN+FP} FPR=TN+FPFN
ROC, AUC与PR
ROC,AUC,PR曲线与混淆矩阵的各数据有非常直接的联系.
ROC曲线
横坐标FPR, 纵坐标TPR, 用分类的结果计算得点再连接成曲线. 显然越靠近左上角, 模型的准确率越高.
AUC
ROC的积分是模型的AUC, 用积分的含义可以解释为分类模型ROC曲线的面积.
在二分类的情况下, ROC数值大小不同对应模型的分类能力也不同:
- A U C = 1 AUC = 1 AUC=1: 模型具有100%完美预测的能力
- A U C ∈ [ 0.5 , 1 ] AUC\in [0.5, 1] AUC∈[0.5,1]: 在合适的阈值下, 模型预测能力优于随机预测
- A U C = 0.5 AUC = 0.5 AUC=0.5: 模型预测能力与随机预测相同, 此时的模型相当于在瞎猜
- A U C ∈ [ 0 , 0.5 ] AUC\in[0,0.5] AUC∈[0,0.5]: 模型预测能力相当差, 甚至低于瞎猜
PR曲线
横坐标recall, 纵坐标precision, 显然, 同一测试集, 上方的曲线预测能力更强; 在其他条件相同时, 光滑的曲线更强.
回归模型的性能度量
在学习方程时, 回归的含义是对一组变量与另一组变量之间关系的研究(给定x, y对, 计算y对x的方程). 对于回归模型的性能度量可以直接用数据表示, 不用再画图.在python中也可以直接找到对应的库函数调用.
{
L
1
−
n
o
r
m
l
o
s
s
(
L
1
范
数
损
失
)
:
M
A
E
(
y
,
y
^
)
=
1
n
∑
i
=
1
n
∣
y
i
−
y
^
i
∣
(
平
均
绝
对
误
差
)
L
2
−
n
o
r
m
l
o
s
s
(
L
2
范
数
损
失
)
:
M
S
E
(
y
,
y
^
)
=
1
n
∑
i
=
1
n
(
y
i
−
y
^
i
)
2
(
平
均
平
方
误
差
)
R
M
S
E
=
M
S
E
解
释
变
异
:
可
被
回
归
模
型
解
释
的
数
据
占
总
数
据
比
决
定
系
数
:
R
2
(
y
,
y
^
)
=
1
−
∑
i
=
1
n
(
y
−
y
^
)
2
∑
i
=
1
n
(
y
−
y
‾
)
2
(
回
归
模
型
已
解
释
的
y
值
占
比
)
\begin{cases} L_1-norm loss(L_1范数损失):MAE(y, \hat y)=\frac{1}{n}\sum_{i=1}^n|y_i -\hat y_i|(平均绝对误差) \\ L_2-norm loss(L_2范数损失):MSE(y, \hat y)=\frac{1}{n}\sum_{i=1}^n(y_i -\hat y_i)^2(平均平方误差) \\ RMSE = \sqrt {MSE} \\ 解释变异: 可被回归模型解释的数据占总数据比 \\ 决定系数: R^2(y, \hat y) =1-\frac{\sum_{i=1}^n(y-\hat y)^2}{\sum_{i=1}^n(y-\overline y)^2}(回归模型已解释的y值占比) \end{cases}
⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧L1−normloss(L1范数损失):MAE(y,y^)=n1∑i=1n∣yi−y^i∣(平均绝对误差)L2−normloss(L2范数损失):MSE(y,y^)=n1∑i=1n(yi−y^i)2(平均平方误差)RMSE=MSE解释变异:可被回归模型解释的数据占总数据比决定系数:R2(y,y^)=1−∑i=1n(y−y)2∑i=1n(y−y^)2(回归模型已解释的y值占比)
在决定系数中,
y
‾
=
1
n
∑
i
=
1
n
y
i
\overline y = \frac{1}{n}\sum_{i=1}^ny_i
y=n1∑i=1nyi
聚类模型的性能度量
约定在兰德指数中,某类别信息记为C, 聚类结果为K, CK中同类元素对数为a, 不同对数为b ;
在轮廓系数中, 样本与其他同类样本的平均距离记为a, 样本与最近不同类样本距离的平均值记为b
{ R a n d I n d e x 兰 德 指 数 : R I = a + b C 2 n ∈ [ 0 , 1 ] A d j u s t e d R a n d I n d e x 调 整 兰 德 指 数 : A R I = R I − E ( R I ) m a x ( R I ) − E ( R I ) 轮 廓 系 数 : S = b − a m a x ( a , b ) M I : 互 信 息 , 表 示 两 种 分 布 的 吻 合 程 度 A M I : 调 整 互 信 息 N M I : 标 准 化 互 信 息 \begin{cases} RandIndex兰德指数: RI = \frac{a+b}{C_2^n} \in [0,1] \\ AdjustedRandIndex调整兰德指数: ARI = \frac{RI-E(RI)}{max(RI)-E(RI)}\\ 轮廓系数: S = \frac{b-a}{max(a, b)}\\ MI: 互信息,表示两种分布的吻合程度\\ AMI: 调整互信息\\ NMI: 标准化互信息 \end{cases} ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧RandIndex兰德指数:RI=C2na+b∈[0,1]AdjustedRandIndex调整兰德指数:ARI=max(RI)−E(RI)RI−E(RI)轮廓系数:S=max(a,b)b−aMI:互信息,表示两种分布的吻合程度AMI:调整互信息NMI:标准化互信息

















 2013
2013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









