






一:An Attention Pooling based Representation Learning Method for Speech Emotion Recognition(2018 InterSpeech)
(1)论文的模型如下图,输入声谱图,CNN先用两个不同的卷积核分别提取时域特征和频域特征,concat后喂给后面的CNN,在最后一层使用attention pooling的技术,在IEMOCAP的四类情感上取得71.8% 的weighted accuracy (WA) 和68% 的unweighted accuracy (UA),WA就是平时说的准确率,而UA是求各类的准确率然后做平均 。比state-of-art多了3%的WA和4%的UA。
(2)实验中的其中一篇baseline刚好也看了一下(就是下一篇要提到的论文),baseline用的是五折交叉而且带验证集的,而本论文用的是十折交叉只带测试集的,所以直接对比应该是不太科学的。
(3)我在复现这篇论文模型的时候一直都达不到论文中的结果,反复看了一下,最后是注意到论文在attention pooling合并前对bottom-up attention的feature map先做了一个softmax,这个softmax我觉得很奇怪,把它去掉后发现准确率飙升,可以达到论文中的实验结果,甚至可以超出。可能具体实现细节上有一些其它的出入。
(4)复现的时候我用的python_speech_feature库,其中有三种声谱图可以选择,振幅图,能量图,log能量图,debug的时候发现振幅和能量值的range还是挺大的,用log可以把range很大的值压到比较小的范围,所以我用的是log能量图。论文中提到对声谱图做一个预处理,说是可以让训练过程更加稳定,我在实现论文的时候有发现不加这个预处理结果会比较高。预处理的做法是先归一化到[-1, 1]然后做一个u为256的u率压扩,看到这里的256我估计论文是把声谱图直接保存成图像后做的归一化,而我是保存成声谱图矩阵来作为输入。
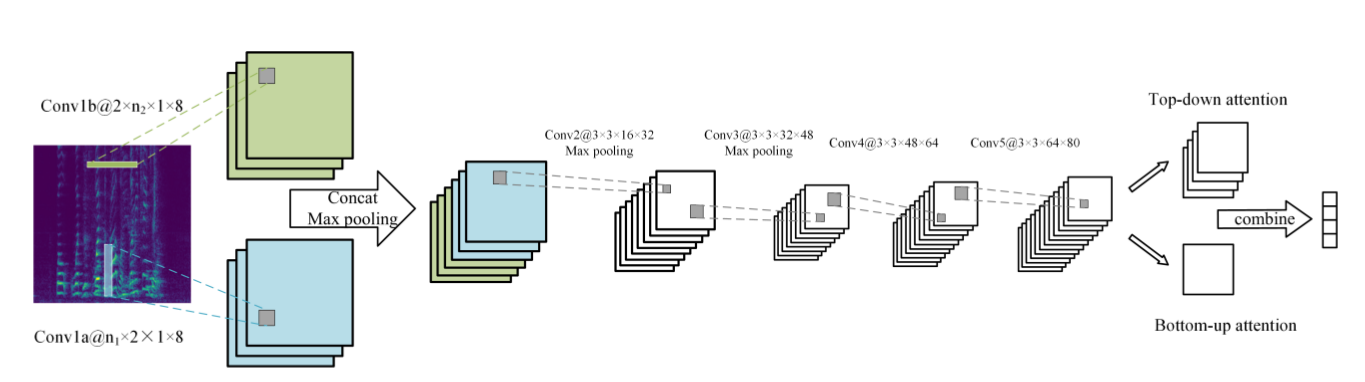
二:**Efficient Emotion Recognition from Speech Using Deep Learning on Spectrograms(2017 InterSpeech)**
(1)这篇论文是上一篇论文的其中一个baseline,于是也看了一下。模型结构图如下图,输入的也是声谱图,和上一篇稍微不同的是预处理方面,上篇是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 766
766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









