



如果perf无法找到内核源代码,则可能需要手动设置源代码位置。可以通过设置环境变量KERNEL_SOURCE来实现。例如,如果您的内核源代码位于/usr/src/linux目录下,则可以使用以下命令来设置环境变量:
复制代码export KERNEL_SOURCE=/usr/src/linux
然后,重新运行perf工具即可。如果您想永久设置这个环境变量,可以将它添加到~/.bashrc文件中。
perf examples
下面是一些使用perf Linux分析器的例子,该分析器也被称为Linux性能计数器(Performance Counters for Linux, PCL)、Linux perf事件(Linux perf events, LPE)或perf_events。
Perf_events是一个面向事件的可观察性工具,可以帮助您解决高级性能和故障诊断功能。可以回答的问题包括:
- Why is the kernel on-CPU so much? What code-paths? 为什么内核一直在on-CPU?代码是如何执行的
- Which code-paths are causing CPU level 2 cache misses? 哪些代码导致了CPU L2 misses?
- Are the CPUs stalled on memory I/O? cpu是否停在内存I/O上?
- Which code-paths are allocating memory, and how much? 哪些代码路径分配了内存,分配了多少内存?
- What is triggering TCP retransmits? 什么触发了TCP重传?
- Is a certain kernel function being called, and how often?
- What reasons are threads leaving the CPU? 线程离开CPU的原因是什么?
perf_events是Linux内核的一部分,在tools/perf下。虽然它使用了许多Linux trace特性,但有些还没有通过perf命令暴露,需要通过ftrace接口来使用。我的perf-tools(https://github.com/brendangregg/perf-tools)集合(github)根据需要同时使用了perf_events和ftrace。
1. Screenshot
从屏幕截图开始,下面是perf版本3.9.3跟踪磁盘I/O:
# perf record -e block:block_rq_issue -ag
^C
# ls -l perf.data
-rw------- 1 root root 3458162 Jan 26 03:03 perf.data
# perf report
[...]
# Samples: 2K of event 'block:block_rq_issue'
# Event count (approx.): 2216
#
# Overhead Command Shared Object Symbol
# ........ ............ ................. ....................
#
32.13% dd [kernel.kallsyms] [k] blk_peek_request
|
--- blk_peek_request
virtblk_request
__blk_run_queue
|
|--98.31%-- queue_unplugged
| blk_flush_plug_list
| |
| |--91.00%-- blk_queue_bio
| | generic_make_request
| | submit_bio
| | ext4_io_submit
| | |
| | |--58.71%-- ext4_bio_write_page
| | | mpage_da_submit_io
| | | mpage_da_map_and_submit
| | | write_cache_pages_da
| | | ext4_da_writepages
| | | do_writepages
| | | __filemap_fdatawrite_range
| | | filemap_flush
| | | ext4_alloc_da_blocks
| | | ext4_release_file
| | | __fput
| | | ____fput
| | | task_work_run
| | | do_notify_resume
| | | int_signal
| | | close
| | | 0x0
| | |
| | --41.29%-- mpage_da_submit_io
[...]
使用了一个perf记录命令来跟踪该块:block_rq_issue探针,该探针在发出块设备I/O请求(磁盘I/O)时触发。选项包括-a用于跟踪所有cpu, -g用于捕获调用图(堆栈跟踪)。跟踪数据被写入perf。当按下Ctrl-C键时,跟踪结束。使用perf report打印perf.data文件的摘要,该报告根据堆栈跟踪构建树,合并公共路径,并显示每个路径的百分比。
perf报告的输出显示有2216个事件被跟踪(磁盘I/O),其中32%来自dd命令。这些请求是由内核函数blk_peek_request()发出的,沿着栈往下看,这32%中大约有一半来自close()系统调用。
2. One-Liners
我收集或编写的一些有用的单行代码。我使用的术语,从低到高的开销:
- statistics/count: 在事件上增加一个整数计数器
- sample: 从一个事件子集收集细节(例如,指令指针或堆栈)(每次一次…)
- trace: 收集每个事件的详细信息
Listing Events
# Listing all currently known events:
perf list
# Listing sched tracepoints:
perf list 'sched:*'
Counting Events
# CPU counter statistics for the specified command:
perf stat command
# Detailed CPU counter statistics (includes extras) for the specified command:
perf stat -d command
# CPU counter statistics for the specified PID, until Ctrl-C:
perf stat -p PID
# CPU counter statistics for the entire system, for 5 seconds:
perf stat -a sleep 5
# Various basic CPU statistics, system wide, for 10 seconds:
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles -a sleep 10
# Various CPU level 1 data cache statistics for the specified command:
perf stat -e L1-dcache-loads,L1-dcache-load-misses,L1-dcache-stores command
# Various CPU data TLB statistics for the specified command:
perf stat -e dTLB-loads,dTLB-load-misses,dTLB-prefetch-misses command
# Various CPU last level cache statistics for the specified command:
perf stat -e LLC-loads,LLC-load-misses,LLC-stores,LLC-prefetches command
# Using raw PMC counters, eg, counting unhalted core cycles:
perf stat -e r003c -a sleep 5
# PMCs: counting cycles and frontend stalls via raw specification:
perf stat -e cycles -e cpu/event=0x0e,umask=0x01,inv,cmask=0x01/ -a sleep 5
# Count syscalls per-second system-wide:
perf stat -e raw_syscalls:sys_enter -I 1000 -a
# Count system calls by type for the specified PID, until Ctrl-C:
perf stat -e 'syscalls:sys_enter_*' -p PID
# Count system calls by type for the entire system, for 5 seconds:
perf stat -e 'syscalls:sys_enter_*' -a sleep 5
# Count scheduler events for the specified PID, until Ctrl-C:
perf stat -e 'sched:*' -p PID
# Count scheduler events for the specified PID, for 10 seconds:
perf stat -e 'sched:*' -p PID sleep 10
# Count ext4 events for the entire system, for 10 seconds:
perf stat -e 'ext4:*' -a sleep 10
# Count block device I/O events for the entire system, for 10 seconds:
perf stat -e 'block:*' -a sleep 10
# Count all vmscan events, printing a report every second:
perf stat -e 'vmscan:*' -a -I 1000
Profiling
# Sample on-CPU functions for the specified command, at 99 Hertz:
perf record -F 99 command
# Sample on-CPU functions for the specified PID, at 99 Hertz, until Ctrl-C:
perf record -F 99 -p PID
# Sample on-CPU functions for the specified PID, at 99 Hertz, for 10 seconds:
perf record -F 99 -p PID sleep 10
# Sample CPU stack traces (via frame pointers) for the specified PID, at 99 Hertz, for 10 seconds:
perf record -F 99 -p PID -g -- sleep 10
# Sample CPU stack traces for the PID, using dwarf (dbg info) to unwind stacks, at 99 Hertz, for 10 seconds:
perf record -F 99 -p PID --call-graph dwarf sleep 10
# Sample CPU stack traces for the entire system, at 99 Hertz, for 10 seconds (< Linux 4.11):
perf record -F 99 -ag -- sleep 10
# Sample CPU stack traces for the entire system, at 99 Hertz, for 10 seconds (>= Linux 4.11):
perf record -F 99 -g -- sleep 10
# If the previous command didn't work, try forcing perf to use the cpu-clock event:
perf record -F 99 -e cpu-clock -ag -- sleep 10
# Sample CPU stack traces for a container identified by its /sys/fs/cgroup/perf_event cgroup:
perf record -F 99 -e cpu-clock --cgroup=docker/1d567f4393190204...etc... -a -- sleep 10
# Sample CPU stack traces for the entire system, with dwarf stacks, at 99 Hertz, for 10 seconds:
perf record -F 99 -a --call-graph dwarf sleep 10
# Sample CPU stack traces for the entire system, using last branch record for stacks, ... (>= Linux 4.?):
perf record -F 99 -a --call-graph lbr sleep 10
# Sample CPU stack traces, once every 10,000 Level 1 data cache misses, for 5 seconds:
perf record -e L1-dcache-load-misses -c 10000 -ag -- sleep 5
# Sample CPU stack traces, once every 100 last level cache misses, for 5 seconds:
perf record -e LLC-load-misses -c 100 -ag -- sleep 5
# Sample on-CPU kernel instructions, for 5 seconds:
perf record -e cycles:k -a -- sleep 5
# Sample on-CPU user instructions, for 5 seconds:
perf record -e cycles:u -a -- sleep 5
# Sample on-CPU user instructions precisely (using PEBS), for 5 seconds:
perf record -e cycles:up -a -- sleep 5
# Perform branch tracing (needs HW support), for 1 second:
perf record -b -a sleep 1
# Sample CPUs at 49 Hertz, and show top addresses and symbols, live (no perf.data file):
perf top -F 49
# Sample CPUs at 49 Hertz, and show top process names and segments, live:
perf top -F 49 -ns comm,dso
Static Tracing
# Trace new processes, until Ctrl-C:
perf record -e sched:sched_process_exec -a
# Sample (take a subset of) context-switches, until Ctrl-C:
perf record -e context-switches -a
# Trace all context-switches, until Ctrl-C:
perf record -e context-switches -c 1 -a
# Include raw settings used (see: man perf_event_open):
perf record -vv -e context-switches -a
# Trace all context-switches via sched tracepoint, until Ctrl-C:
perf record -e sched:sched_switch -a
# Sample context-switches with stack traces, until Ctrl-C:
perf record -e context-switches -ag
# Sample context-switches with stack traces, for 10 seconds:
perf record -e context-switches -ag -- sleep 10
# Sample CS, stack traces, and with timestamps (< Linux 3.17, -T now default):
perf record -e context-switches -ag -T
# Sample CPU migrations, for 10 seconds:
perf record -e migrations -a -- sleep 10
# Trace all connect()s with stack traces (outbound connections), until Ctrl-C:
perf record -e syscalls:sys_enter_connect -ag
# Trace all accepts()s with stack traces (inbound connections), until Ctrl-C:
perf record -e syscalls:sys_enter_accept* -ag
# Trace all block device (disk I/O) requests with stack traces, until Ctrl-C:
perf record -e block:block_rq_insert -ag
# Sample at most 100 block device requests per second, until Ctrl-C:
perf record -F 100 -e block:block_rq_insert -a
# Trace all block device issues and completions (has timestamps), until Ctrl-C:
perf record -e block:block_rq_issue -e block:block_rq_complete -a
# Trace all block completions, of size at least 100 Kbytes, until Ctrl-C:
perf record -e block:block_rq_complete --filter 'nr_sector > 200'
# Trace all block completions, synchronous writes only, until Ctrl-C:
perf record -e block:block_rq_complete --filter 'rwbs == "WS"'
# Trace all block completions, all types of writes, until Ctrl-C:
perf record -e block:block_rq_complete --filter 'rwbs ~ "*W*"'
# Sample minor faults (RSS growth) with stack traces, until Ctrl-C:
perf record -e minor-faults -ag
# Trace all minor faults with stack traces, until Ctrl-C:
perf record -e minor-faults -c 1 -ag
# Sample page faults with stack traces, until Ctrl-C:
perf record -e page-faults -ag
# Trace all ext4 calls, and write to a non-ext4 location, until Ctrl-C:
perf record -e 'ext4:*' -o /tmp/perf.data -a
# Trace kswapd wakeup events, until Ctrl-C:
perf record -e vmscan:mm_vmscan_wakeup_kswapd -ag
# Add Node.js USDT probes (Linux 4.10+):
perf buildid-cache --add `which node`
# Trace the node http__server__request USDT event (Linux 4.10+):
perf record -e sdt_node:http__server__request -a
Dynamic Tracing
# Add a tracepoint for the kernel tcp_sendmsg() function entry ("--add" is optional):
perf probe --add tcp_sendmsg
# Remove the tcp_sendmsg() tracepoint (or use "--del"):
perf probe -d tcp_sendmsg
# Add a tracepoint for the kernel tcp_sendmsg() function return:
perf probe 'tcp_sendmsg%return'
# Show available variables for the kernel tcp_sendmsg() function (needs debuginfo):
perf probe -V tcp_sendmsg
# Show available variables for the kernel tcp_sendmsg() function, plus external vars (needs debuginfo):
perf probe -V tcp_sendmsg --externs
# Show available line probes for tcp_sendmsg() (needs debuginfo):
perf probe -L tcp_sendmsg
# Show available variables for tcp_sendmsg() at line number 81 (needs debuginfo):
perf probe -V tcp_sendmsg:81
# Add a tracepoint for tcp_sendmsg(), with three entry argument registers (platform specific):
perf probe 'tcp_sendmsg %ax %dx %cx'
# Add a tracepoint for tcp_sendmsg(), with an alias ("bytes") for the %cx register (platform specific):
perf probe 'tcp_sendmsg bytes=%cx'
# Trace previously created probe when the bytes (alias) variable is greater than 100:
perf record -e probe:tcp_sendmsg --filter 'bytes > 100'
# Add a tracepoint for tcp_sendmsg() return, and capture the return value:
perf probe 'tcp_sendmsg%return $retval'
# Add a tracepoint for tcp_sendmsg(), and "size" entry argument (reliable, but needs debuginfo):
perf probe 'tcp_sendmsg size'
# Add a tracepoint for tcp_sendmsg(), with size and socket state (needs debuginfo):
perf probe 'tcp_sendmsg size sk->__sk_common.skc_state'
# Tell me how on Earth you would do this, but don't actually do it (needs debuginfo):
perf probe -nv 'tcp_sendmsg size sk->__sk_common.skc_state'
# Trace previous probe when size is non-zero, and state is not TCP_ESTABLISHED(1) (needs debuginfo):
perf record -e probe:tcp_sendmsg --filter 'size > 0 && skc_state != 1' -a
# Add a tracepoint for tcp_sendmsg() line 81 with local variable seglen (needs debuginfo):
perf probe 'tcp_sendmsg:81 seglen'
# Add a tracepoint for do_sys_open() with the filename as a string (needs debuginfo):
perf probe 'do_sys_open filename:string'
# Add a tracepoint for myfunc() return, and include the retval as a string:
perf probe 'myfunc%return +0($retval):string'
# Add a tracepoint for the user-level malloc() function from libc:
perf probe -x /lib64/libc.so.6 malloc
# Add a tracepoint for this user-level static probe (USDT, aka SDT event):
perf probe -x /usr/lib64/libpthread-2.24.so %sdt_libpthread:mutex_entry
# List currently available dynamic probes:
perf probe -l
Mixed
# Trace system calls by process, showing a summary refreshing every 2 seconds:
perf top -e raw_syscalls:sys_enter -ns comm
# Trace sent network packets by on-CPU process, rolling output (no clear):
stdbuf -oL perf top -e net:net_dev_xmit -ns comm | strings
# Sample stacks at 99 Hertz, and, context switches:
perf record -F99 -e cpu-clock -e cs -a -g
# Sample stacks to 2 levels deep, and, context switch stacks to 5 levels (needs 4.8):
perf record -F99 -e cpu-clock/max-stack=2/ -e cs/max-stack=5/ -a -g
Special
# Record cacheline events (Linux 4.10+):
perf c2c record -a -- sleep 10
# Report cacheline events from previous recording (Linux 4.10+):
perf c2c report
Reporting
# Show perf.data in an ncurses browser (TUI) if possible:
perf report
# Show perf.data with a column for sample count:
perf report -n
# Show perf.data as a text report, with data coalesced and percentages:
perf report --stdio
# Report, with stacks in folded format: one line per stack (needs 4.4):
perf report --stdio -n -g folded
# List all events from perf.data:
perf script
# List all perf.data events, with data header (newer kernels; was previously default):
perf script --header
# List all perf.data events, with customized fields (< Linux 4.1):
perf script -f time,event,trace
# List all perf.data events, with customized fields (>= Linux 4.1):
perf script -F time,event,trace
# List all perf.data events, with my recommended fields (needs record -a; newer kernels):
perf script --header -F comm,pid,tid,cpu,time,event,ip,sym,dso
# List all perf.data events, with my recommended fields (needs record -a; older kernels):
perf script -f comm,pid,tid,cpu,time,event,ip,sym,dso
# Dump raw contents from perf.data as hex (for debugging):
perf script -D
# Disassemble and annotate instructions with percentages (needs some debuginfo):
perf annotate --stdio
这些单行代码用于说明perf_events的功能,也可以使用简短的教程:学习perf_events,一次一行。您也可以将这些打印为perf_events备忘录。
4. Background
下面几节提供一些背景知识,帮助理解perf_events以及如何使用它。我将描述先决条件、受众、用法、事件和跟踪点。
4.1. Prerequisites
perf工具位于linux-tools-common包中。首先添加它,然后运行“perf”看看你是否得到了使用信息。它可能会告诉你安装另一个相关的包(linux-tools-kernelversion)。
您还可以从Linux内核源代码构建和添加perf。
为了获得最大的性能,你需要symbol和堆栈跟踪。这些可能在你的Linux发行版中默认工作,或者它们可能需要添加包,或者使用额外的配置选项重新编译内核。
4.2. Symbols
与其他调试工具一样,Perf_events也需要符号信息(symbols)。它们用于将内存地址转换为函数和变量名,以便我们可以读取它们。如果没有符号,您将看到表示所分析的内存地址的十六进制数字。
下面的perf报告输出显示了堆栈跟踪,但只能看到十六进制数:
57.14% sshd libc-2.15.so [.] connect
|
--- connect
|
|--25.00%-- 0x7ff3c1cddf29
|
|--25.00%-- 0x7ff3bfe82761
| 0x7ff3bfe82b7c
|
|--25.00%-- 0x7ff3bfe82dfc
--25.00%-- [...]
如果软件是通过包添加的,您可能会找到提供符号的调试包(通常是“-dbgsym”)。有时perf报告会告诉你安装这些,例如:“在/bin/dd中没有找到符号,也许安装一个调试包?”
下面是在添加openssh-server-dbgsym和libc6-dbgsym(在ubuntu 12.04上)后,与之前看到的性能报告输出相同:
57.14% sshd libc-2.15.so [.] __GI___connect_internal
|
--- __GI___connect_internal
|
|--25.00%-- add_one_listen_addr.isra.0
|
|--25.00%-- __nscd_get_mapping
| __nscd_get_map_ref
|
|--25.00%-- __nscd_open_socket
--25.00%-- [...]
我发现添加libc6-dbgsym和coreutil-dbgsym很有用,以提供用户级操作系统代码路径的一些符号覆盖。
另一种获取symbol的方法是自己编译软件。例如,我刚刚编译了node (node .js):
# file node-v0.10.28/out/Release/node
node-v0.10.28/out/Release/node: ELF 64-bit LSB executable, ... not stripped
它还没有被strip,所以我可以分析node,看到的不仅仅是十六进制。如果结果是剥离的,请配置构建系统,不要在输出的二进制文件上运行strip(1)。
内核级符号位于内核debuginfo包中,或者在用CONFIG_KALLSYMS编译内核时。
4.4 Stack Traces
总是使用帧指针编译。省略帧指针是一种糟糕的编译器优化,会破坏调试器,而且可悲的是,这通常是默认的。如果没有它们,您可能会看到perf_events的不完整堆栈,就像前面sshd符号示例中看到的那样。有三种方法可以解决这个问题:要么使用dwarf数据展开栈,要么在可用的情况下使用最后分支记录(LBR)(处理器特性),或者返回帧指针。
还有其他的栈遍历技术,如BTS(分支跟踪存储)和新的ORC unwinder。我会在某个时候(以及性能支持到达时)为它们添加文档。
Frame Pointers
早期的sshd例子是OpenSSH的默认构建,它使用编译器优化(-O2),在这个例子中省略了帧指针。下面是使用-fno-omit-frame-pointer重新编译OpenSSH后的样子:
100.00% sshd libc-2.15.so [.] __GI___connect_internal
|
--- __GI___connect_internal
|
|--30.00%-- add_one_listen_addr.isra.0
| add_listen_addr
| fill_default_server_options
| main
| __libc_start_main
|
|--20.00%-- __nscd_get_mapping
| __nscd_get_map_ref
|
|--20.00%-- __nscd_open_socket
--30.00%-- [...]
现在可以看到从add_one_listen_addr()到main()和__libc_start_main()了。
内核也可能遇到同样的问题。下面是一个在空闲服务器上收集的CPU配置文件示例,使用堆栈跟踪(-g):
99.97% swapper [kernel.kallsyms] [k] default_idle
|
--- default_idle
0.03% sshd [kernel.kallsyms] [k] iowrite16
|
--- iowrite16
__write_nocancel
(nil)
内核栈跟踪不完整。现在创建一个类似的配置文件CONFIG_FRAME_POINTER=y:
99.97% swapper [kernel.kallsyms] [k] default_idle
|
--- default_idle
cpu_idle
|
|--87.50%-- start_secondary
|
--12.50%-- rest_init
start_kernel
x86_64_start_reservations
x86_64_start_kernel
0.03% sshd [kernel.kallsyms] [k] iowrite16
|
--- iowrite16
vp_notify
virtqueue_kick
start_xmit
dev_hard_start_xmit
sch_direct_xmit
dev_queue_xmit
ip_finish_output
ip_output
ip_local_out
ip_queue_xmit
tcp_transmit_skb
tcp_write_xmit
__tcp_push_pending_frames
tcp_sendmsg
inet_sendmsg
sock_aio_write
do_sync_write
vfs_write
sys_write
system_call_fastpath
__write_nocancel
好多了——可以看到从write()系统调用(__write_nocancel)到iowrite16()的整个路径。
Dwarf
大约从3.9内核开始,perf_events支持一种解决用户级栈中缺少帧指针的解决方案:libunwind,它使用dwarf。这可以使用“–call-graph dwarf”(或“-g dwarf”)来启用。
Dwarf(Debugging With Attributed Record Formats)是一种通用的调试信息格式,它包含了关于变量、函数、源代码等调试信息,并支持多种调试器进行解释和使用。
要在编译应用程序时生成dwarf4调试信息,可以使用gcc编译器并使用以下选项:
-g -gdwarf-4
其中,-g选项指示编译器生成调试信息,而-gdwarf-4选项指示编译器使用dwarf4格式生成调试信息。例如,编译一个名为test.c的C语言源代码文件并生成dwarf4调试信息的命令如下:
gcc -g -gdwarf-4 test.c -o test
值得注意的是,dwarf4调试信息相对于较早的dwarf2格式具有更好的性能和可扩展性,但不是所有的调试器都支持dwarf4格式。在使用具体的调试器之前,需要确认该调试器是否支持dwarf4格式,并进行相应的配置。
libunwind是一个开源的C/C++库,用于获取执行过程中的回溯信息(backtrace),即获取当前执行位置的调用栈信息。它可以与各种平台和编译器配合使用,并支持多种架构。
而DWARF(Debugging With Attributed Record Formats)是一种通用的调试信息格式,用于描述程序符号表、类型信息、源代码行号等元数据,并提供给调试器进行解释和使用。DWARF格式通常作为二进制文件的一部分出现,可以通过调试器解析并提供给用户进行调试。
在实际使用中,libunwind库通常会使用DWARF格式的调试信息来获取回溯信息。当应用程序遇到错误或异常时,libunwind会从当前位置开始向上递归查找函数调用链,并使用DWARF格式的调试信息来解析每个调用帧。在每个调用帧中,libunwind可以获取函数的名称、参数、返回地址等信息,并构造出完整的回溯信息。因此,libunwind和DWARF之间存在紧密的联系,并共同构成了应用程序调试的重要组成部分。
有关构建perf_events的其他注意事项,请参阅构建部分,因为如果没有正确的库,它可能会在不支持dwarf的情况下自行构建。
LBR
LBR是Linux性能事件监控工具perf中的一个功能,它代表Last Branch Record(最后分支记录),用于记录CPU执行过程中的分支跳转信息,包括分支指令的地址、目标地址、是否为直接分支等信息。LBR功能通常与硬件性能计数器(PMU)一起使用,以提供更全面、准确的性能分析数据。
LBR功能可用于诊断应用程序或系统性能问题,并帮助用户定位瓶颈所在。它可以记录哪些代码路径被频繁地执行或哪些分支跳转导致了缓存失效等情况。此外,LBR功能还可以用于检测恶意代码或漏洞利用攻击,因为它可以记录处理器执行的所有分支跳转信息,包括控制流改变和函数调用等。
要使用LBR功能,需要满足以下条件:
- CPU支持LBR功能,并进行了相应的配置。
- 操作系统内核支持LBR,且相关驱动程序已加载。
- perf工具版本支持LBR,并正确配置了相应选项。
在perf中启用LBR功能可以使用perf record命令,并添加如下选项:
-b, --branch-stack
该选项将启用LBR功能,并将分支跳转信息存储到perf.data文件中。之后,用户可以使用perf report命令分析perf.data文件,并查看分支跳转信息。
您必须有Last Branch Record访问才能使用它。它在大多数云环境中都是禁用的,你会看到这样的错误:
# perf record -F 99 -a --call-graph lbr
Error:
PMU Hardware doesn't support sampling/overflow-interrupts.
Here’s an example of it working:
# perf record -F 99 -a --call-graph lbr
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.903 MB perf.data (163 samples) ]
# perf script
[...]
stackcollapse-p 23867 [007] 4762187.971824: 29003297 cycles:ppp:
1430c0 Perl_re_intuit_start (/usr/bin/perl)
144118 Perl_regexec_flags (/usr/bin/perl)
cfcc9 Perl_pp_match (/usr/bin/perl)
cbee3 Perl_runops_standard (/usr/bin/perl)
51fb3 perl_run (/usr/bin/perl)
2b168 main (/usr/bin/perl)
stackcollapse-p 23867 [007] 4762187.980184: 31532281 cycles:ppp:
e3660 Perl_sv_force_normal_flags (/usr/bin/perl)
109b86 Perl_leave_scope (/usr/bin/perl)
1139db Perl_pp_leave (/usr/bin/perl)
cbee3 Perl_runops_standard (/usr/bin/perl)
51fb3 perl_run (/usr/bin/perl)
2b168 main (/usr/bin/perl)
stackcollapse-p 23867 [007] 4762187.989283: 32341031 cycles:ppp:
cfae0 Perl_pp_match (/usr/bin/perl)
cbee3 Perl_runops_standard (/usr/bin/perl)
51fb3 perl_run (/usr/bin/perl)
2b168 main (/usr/bin/perl)
好了!请注意,LBR通常在堆栈深度上是有限的(8帧、16帧或32帧),因此它可能不适合深度堆栈或火焰图生成,因为火焰图需要走到公共根进行合并。
下面是使用默认帧指针游走进行采样的相同程序:
# perf record -F 99 -a -g
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.882 MB perf.data (81 samples) ]
# perf script
[...]
stackcollapse-p 23883 [005] 4762405.747834: 35044916 cycles:ppp:
135b83 [unknown] (/usr/bin/perl)
stackcollapse-p 23883 [005] 4762405.757935: 35036297 cycles:ppp:
ee67d Perl_sv_gets (/usr/bin/perl)
stackcollapse-p 23883 [005] 4762405.768038: 35045174 cycles:ppp:
137334 [unknown] (/usr/bin/perl)
您可以使用帧指针支持重新编译Perl(在其./Configure中,选择编译器选项:add -fno-omit-frame-pointer)。如果LBR可用,你也可以使用它,而且你不需要很长的堆栈。
4.5. Audience
要使用perf_events,你可以:
-
开发自己的命令
-
运行命令示例
开发perf_events的新调用需要研究内核和应用程序代码,这并不适合所有人。更多的人将通过运行其他人开发的命令来使用perf_events,就像本页上的示例一样。这可以很好地解决:您的组织可能只需要一到两个人,他们可以开发perf_events命令或获取它们,然后共享它们以供整个操作和支持组使用。
无论哪种方式,您都需要了解perf_events的功能,以便知道何时使用它,无论是搜索示例命令还是编写自己的命令。下面示例的目的之一是向您展示可以做些什么,以帮助您学习这些功能。您还应该浏览其他网站上的示例(https://www.brendangregg.com/perf.html#Links)。
如果你以前从未使用过perf_events,可能需要在生产环境中使用它之前进行测试(它过去有内核panic bug)。我的经历还不错(没有恐慌)。
4.6. Usage
Perf_events为各种性能分析活动提供了一个命令行工具perf和子命令。这是提供各种事件的不同工具框架的单一接口。
perf命令将单独列出子命令;下面是perf 4.10版本(针对Linux 4.10内核):
# perf
usage: perf [--version] [--help] [OPTIONS] COMMAND [ARGS]
The most commonly used perf commands are:
annotate Read perf.data (created by perf record) and display annotated code
archive Create archive with object files with build-ids found in perf.data file
bench General framework for benchmark suites
buildid-cache Manage build-id cache.
buildid-list List the buildids in a perf.data file
config Get and set variables in a configuration file.
data Data file related processing
diff Read perf.data files and display the differential profile
evlist List the event names in a perf.data file
inject Filter to augment the events stream with additional information
kmem Tool to trace/measure kernel memory properties
kvm Tool to trace/measure kvm guest os
list List all symbolic event types
lock Analyze lock events
mem Profile memory accesses
record Run a command and record its profile into perf.data
report Read perf.data (created by perf record) and display the profile
sched Tool to trace/measure scheduler properties (latencies)
script Read perf.data (created by perf record) and display trace output
stat Run a command and gather performance counter statistics
test Runs sanity tests.
timechart Tool to visualize total system behavior during a workload
top System profiling tool.
probe Define new dynamic tracepoints
trace strace inspired tool
See 'perf help COMMAND' for more information on a specific command.
除了为每个子命令提供单独的帮助外,内核源代码中的tools/perf/ documentation中也有相关文档。Perf不断发展,随着时间的推移添加了不同的功能,因此在较旧的内核上,您可能会缺少一些子命令或功能。此外,当您在活动之间切换时,它的使用可能感觉不一致。最好将其视为一种多功能工具。
Perf_events可以通过三种方式检测(现在使用Perf_events术语):
- 在内核上下文中对事件进行计数,perf会打印计数的摘要。此模式不会生成perf.data。
- 采样事件,它将事件数据写入内核缓冲区,perf命令以温和的异步速率读取该缓冲区,并将其写入perf.data。然后通过perf报告或perf脚本命令读取该文件。
- bpf programs on events.这是Linux 4.4+内核中的一个新特性,可以在内核空间中执行自定义的用户定义程序,它可以执行高效的数据过滤和摘要。例如,有效测量的延迟直方图。
尝试使用perf stat命令开始计数事件,看看这是否足够。这个子命令的开销最小。
在使用具有perf record的采样模式时,您需要注意开销,因为捕获文件可能很快变成数百mb。这取决于你所追踪的事件的频率:越频繁,开销越高,性能也就越大。数据的大小。
要真正减少开销并生成更高级的摘要,请编写由perf执行的BPF程序。请参阅eBPF部分。
4.7. Usage Examples
选择这些示例序列是为了说明使用perf的一些不同方式,从收集到报告。
gzip命令的性能计数器汇总,包括IPC:
# perf stat gzip largefile
统计5秒内所有调度器进程事件的数量,并按tracepoint计数:
# perf stat -e 'sched:sched_process_*' -a sleep 5
跟踪所有调度器进程事件5秒,并根据tracepoint和进程名计数:
# perf record -e 'sched:sched_process_*' -a sleep 5
# perf report
跟踪所有调度器进程事件5秒,并转储每个事件的详细信息:
# perf record -e 'sched:sched_process_*' -a sleep 5
# perf script
当请求字节小于10时,跟踪read()系统调用:
# perf record -e 'syscalls:sys_enter_read' --filter 'count < 10' -a
示例CPU堆栈在99赫兹,持续5秒:
# perf record -F 99 -ag -- sleep 5
# perf report
动态检测内核tcp_sendmsg()函数,并使用堆栈跟踪跟踪它5秒:
# perf probe --add tcp_sendmsg
# perf record -e probe:tcp_sendmsg -ag -- sleep 5
# perf probe --del tcp_sendmsg
# perf report
没有必要删除tracepoint(–del);我包含它是为了展示如何将系统恢复到其原始状态。
警告
使用-p PID作为过滤器在一些较旧的内核版本(Linux 3.x)上不能正常工作:perf会达到100%的CPU,需要终止。这是令人讨厌的。解决方法是分析所有cpu (-a),然后过滤pid。
4.8. Special Usage
有许多提供特殊功能的子命令。这些包括:
- perf c2c (Linux 4.10+): cache-2-cache和cacheline false sharing分析。
- Perf kmem:内核内存分配分析。
- perf kvm: kvm虚拟客户分析。
- Perf lock:锁分析。
- Perf mem:内存访问分析。
- Perf sched:内核调度器统计信息。
这些工具利用perf现有的检测功能,记录选定的事件并以自定义的方式报告它们。
5. Events
perf_events检测“事件”,这是不同内核检测框架的统一接口。下面的图说明了事件的来源:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aE9iUpfK-1682324813017)(perf examples.assets/perf_events_map.png)]
事件的类型有:
- 硬件事件:CPU性能监控指标。
- 软件事件(Software event):基于内核计数器的底层事件。例如,CPU迁移、小故障、大故障等。
- 内核Tracepoint事件:这是静态的内核级插桩点,硬编码在内核中有趣且符合逻辑的地方。
- 用户静态定义跟踪(USDT):这些是用户级程序和应用程序的静态跟踪点。
- 动态跟踪:软件可以动态插装,在任何位置创建事件。对于内核软件,使用kprobes框架。对于用户级软件,uprobes。
- 定时分析:可以使用perf记录-F Hz以任意频率收集快照。这通常用于分析CPU使用情况,并通过创建自定义定时中断事件来工作。
可以收集有关事件的详细信息,包括时间戳、导致事件的代码路径和其他特定的细节。perf_events的功能非常强大,你可能只会使用其中的一小部分。
可以使用list子命令列出当前可用的事件:
# perf list
List of pre-defined events (to be used in -e):
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
cache-references [Hardware event]
cache-misses [Hardware event]
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
stalled-cycles-frontend OR idle-cycles-frontend [Hardware event]
stalled-cycles-backend OR idle-cycles-backend [Hardware event]
ref-cycles [Hardware event]
cpu-clock [Software event]
task-clock [Software event]
page-faults OR faults [Software event]
context-switches OR cs [Software event]
cpu-migrations OR migrations [Software event]
minor-faults [Software event]
major-faults [Software event]
alignment-faults [Software event]
emulation-faults [Software event]
L1-dcache-loads [Hardware cache event]
L1-dcache-load-misses [Hardware cache event]
L1-dcache-stores [Hardware cache event]
[...]
rNNN [Raw hardware event descriptor]
cpu/t1=v1[,t2=v2,t3 ...]/modifier [Raw hardware event descriptor]
(see 'man perf-list' on how to encode it)
mem:<addr>[:access] [Hardware breakpoint]
probe:tcp_sendmsg [Tracepoint event]
[...]
sched:sched_process_exec [Tracepoint event]
sched:sched_process_fork [Tracepoint event]
sched:sched_process_wait [Tracepoint event]
sched:sched_wait_task [Tracepoint event]
sched:sched_process_exit [Tracepoint event]
[...]
# perf list | wc -l
657
当您使用动态跟踪时,您正在扩展此列表。此列表中的probe:tcp_sendmsg跟踪点是一个示例,我通过检测tcp_sendmsg()添加了该跟踪点。没有列出分析(抽样)事件。
5.1. Software Events
perf提供了几个固定的软件事件:
# perf list
List of pre-defined events (to be used in -e):
alignment-faults [Software event]
bpf-output [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
[...]
这些也在手册页perf_event_open(2)中有记录:
[...]
PERF_COUNT_SW_CPU_CLOCK
This reports the CPU clock, a high-resolution per-
CPU timer.
PERF_COUNT_SW_TASK_CLOCK
This reports a clock count specific to the task that
is running.
PERF_COUNT_SW_PAGE_FAULTS
This reports the number of page faults.
PERF_COUNT_SW_CONTEXT_SWITCHES
This counts context switches. Until Linux 2.6.34,
these were all reported as user-space events, after
that they are reported as happening in the kernel.
PERF_COUNT_SW_CPU_MIGRATIONS
This reports the number of times the process has
migrated to a new CPU.
PERF_COUNT_SW_PAGE_FAULTS_MIN
This counts the number of minor page faults. These
did not require disk I/O to handle.
[...]
内核还支持traecpoints,它与软件事件非常相似,但具有不同的、可扩展的API。
软件事件可能有一个默认的周期。这意味着,当你使用它们进行采样时,你是在采样事件的子集,而不是跟踪每个事件。你可以用perf record -vv检查:
# perf record -vv -e context-switches /bin/true
Using CPUID GenuineIntel-6-55
------------------------------------------------------------
perf_event_attr:
type 1
size 112
config 0x3
{ sample_period, sample_freq } 4000
sample_type IP|TID|TIME|PERIOD
disabled 1
inherit 1
mmap 1
comm 1
freq 1
enable_on_exec 1
[...]
有关这些字段的描述,请参阅perf_event_open(2)手册页。默认的意思是内核调整采样率,使其每秒捕获大约4000个上下文切换事件。如果你真的想全部记录,可以使用-c 1:
# perf record -vv -e context-switches -c 1 /bin/true
Using CPUID GenuineIntel-6-55
------------------------------------------------------------
perf_event_attr:
type 1
size 112
config 0x3
{ sample_period, sample_freq } 1
sample_type IP|TID|TIME
disabled 1
inherit 1
mmap 1
comm 1
enable_on_exec 1
首先使用perf统计检查事件率,以便您可以估计将要捕获的数据量。默认情况下对子集进行采样可能是一件好事,特别是对于上下文切换这样的高频事件。
许多其他事件(如tracepoints)的默认值都是1。你会在许多软硬件事件中遇到非1的默认值。
5.2. Hardware Events (PMCs)
perf_events最初是一个工具,用于检测处理器的性能监控单元(performance monitoring unit, PMU)硬件计数器,也称为性能监控计数器(performance monitoring counters, PMCs)或性能监控计数器(performance instrumentation counter, PICs)。这些仪器的底层处理器活动,例如CPU周期、指令退役、内存停顿周期、二级缓存缺失等。有些将被列为硬件缓存事件。
pmc在Intel 64 and IA-32 Architectures Software Developer’s Manual Volume 3B: System Programming Guide, Part 2 and the BIOS and Kernel Developer’s Guide (BKDG) For AMD Family 10h Processors.中有记录。有数千种不同的pmc可用。
一个典型的处理器将以以下方式实现PMCs:从成千上万可用的记录中,同一时间只能记录少数或几个。这是因为它们是处理器上的固定硬件资源(寄存器数量有限),程序会开始对选定事件进行计数。
有关使用pmc的示例,请参见6.1。
5.3. Kernel Tracepoints
这些跟踪点硬编码在内核中感兴趣的逻辑位置上,因此可以很容易地跟踪更高层次的行为。例如,系统调用、TCP事件、文件系统I/O、磁盘I/O等。这些被分组为跟踪点库;例如,"sock:"表示套接字事件,"sched:"表示CPU调度器事件。tracepoints的一个关键值是它们应该有一个稳定的API,因此如果你编写的工具在一个内核版本上使用它们,它们应该也能在更高的版本上工作。
跟踪点通常通过include/trace/events/*中的宏添加到内核代码中。XXX覆盖实施。
在我的Linux 4.10系统上,总结跟踪点库的名称和跟踪点的数量:
# perf list | awk -F: '/Tracepoint event/ { lib[$1]++ } END {
for (l in lib) { printf " %-16.16s %d\n", l, lib[l] } }' | sort | column
alarmtimer 4 i2c 8 page_isolation 1 swiotlb 1
block 19 iommu 7 pagemap 2 syscalls 614
btrfs 51 irq 5 power 22 task 2
cgroup 9 irq_vectors 22 printk 1 thermal 7
clk 14 jbd2 16 random 15 thermal_power_ 2
cma 2 kmem 12 ras 4 timer 13
compaction 14 libata 6 raw_syscalls 2 tlb 1
cpuhp 3 mce 1 rcu 1 udp 1
dma_fence 8 mdio 1 regmap 15 vmscan 15
exceptions 2 migrate 2 regulator 7 vsyscall 1
ext4 95 mmc 2 rpm 4 workqueue 4
fib 3 module 5 sched 24 writeback 30
fib6 1 mpx 5 scsi 5 x86_fpu 14
filelock 10 msr 3 sdt_node 1 xen 35
filemap 2 napi 1 signal 2 xfs 495
ftrace 1 net 10 skb 3 xhci-hcd 9
gpio 2 nmi 1 sock 2
huge_memory 4 oom 1 spi 7
These include:
- block: block device I/O
- ext4: file system operations
- kmem: kernel memory allocation events
- random: kernel random number generator events
- sched: CPU scheduler events
- syscalls: system call enter and exits
- task: task events
每次内核升级后,都应该检查跟踪点列表,看看是否有新的跟踪点。添加它们的价值一直在争论,人们想知道有多少人会使用它们(我)。有一个平衡的目标:我将包含足够满足常见需求的最少数量的探测,任何不寻常或不寻常的都可以留给动态跟踪。
有关使用跟踪点的示例,请参见6.4。
5.4. User-Level Statically Defined Tracing (USDT)
与内核跟踪点类似,这些跟踪点被硬编码(通常通过放置宏)在应用程序源代码中有意义的逻辑位置,并作为稳定的API呈现(事件名称和参数)。许多应用程序已经包含跟踪点,以支持DTrace(DTrace Tools (brendangregg.com))。但是,在Linux上,这些应用程序中有许多默认不会编译它们。通常,您需要使用–with-dtrace标志自己编译应用程序。
例如,使用这个版本的Node.js编译USDT事件:
$ sudo apt-get install systemtap-sdt-dev # adds "dtrace", used by node build
$ wget https://nodejs.org/dist/v4.4.1/node-v4.4.1.tar.gz
$ tar xvf node-v4.4.1.tar.gz
$ cd node-v4.4.1
$ ./configure --with-dtrace
$ make -j 8
要检查生成的node二进制文件中是否包含探针:
$ readelf -n node
Displaying notes found at file offset 0x00000254 with length 0x00000020:
Owner Data size Description
GNU 0x00000010 NT_GNU_ABI_TAG (ABI version tag)
OS: Linux, ABI: 2.6.32
Displaying notes found at file offset 0x00000274 with length 0x00000024:
Owner Data size Description
GNU 0x00000014 NT_GNU_BUILD_ID (unique build ID bitstring)
Build ID: 1e01659b0aecedadf297b2c56c4a2b536ae2308a
Displaying notes found at file offset 0x00e70994 with length 0x000003c4:
Owner Data size Description
stapsdt 0x0000003c NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: gc__start
Location: 0x0000000000dc14e4, Base: 0x000000000112e064, Semaphore: 0x000000000147095c
Arguments: 4@%esi 4@%edx 8@%rdi
stapsdt 0x0000003b NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: gc__done
Location: 0x0000000000dc14f4, Base: 0x000000000112e064, Semaphore: 0x000000000147095e
Arguments: 4@%esi 4@%edx 8@%rdi
stapsdt 0x00000067 NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: http__server__response
Location: 0x0000000000dc1894, Base: 0x000000000112e064, Semaphore: 0x0000000001470956
Arguments: 8@%rax 8@-1144(%rbp) -4@-1148(%rbp) -4@-1152(%rbp)
stapsdt 0x00000061 NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: net__stream__end
Location: 0x0000000000dc1c44, Base: 0x000000000112e064, Semaphore: 0x0000000001470952
Arguments: 8@%rax 8@-1144(%rbp) -4@-1148(%rbp) -4@-1152(%rbp)
stapsdt 0x00000068 NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: net__server__connection
Location: 0x0000000000dc1ff4, Base: 0x000000000112e064, Semaphore: 0x0000000001470950
Arguments: 8@%rax 8@-1144(%rbp) -4@-1148(%rbp) -4@-1152(%rbp)
stapsdt 0x00000060 NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: http__client__response
Location: 0x0000000000dc23c5, Base: 0x000000000112e064, Semaphore: 0x000000000147095a
Arguments: 8@%rdx 8@-1144(%rbp) -4@%eax -4@-1152(%rbp)
stapsdt 0x00000089 NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: http__client__request
Location: 0x0000000000dc285e, Base: 0x000000000112e064, Semaphore: 0x0000000001470958
Arguments: 8@%rax 8@%rdx 8@-2184(%rbp) -4@-2188(%rbp) 8@-2232(%rbp) 8@-2240(%rbp) -4@-2192(%rbp)
stapsdt 0x00000089 NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: http__server__request
Location: 0x0000000000dc2e69, Base: 0x000000000112e064, Semaphore: 0x0000000001470954
Arguments: 8@%r14 8@%rax 8@-4344(%rbp) -4@-4348(%rbp) 8@-4304(%rbp) 8@-4312(%rbp) -4@-4352(%rbp)
For examples of using USDT events, see 6.5
5.5. Dynamic Tracing
跟踪点与动态跟踪的区别如下图所示,展示了常用跟踪点库的覆盖情况:
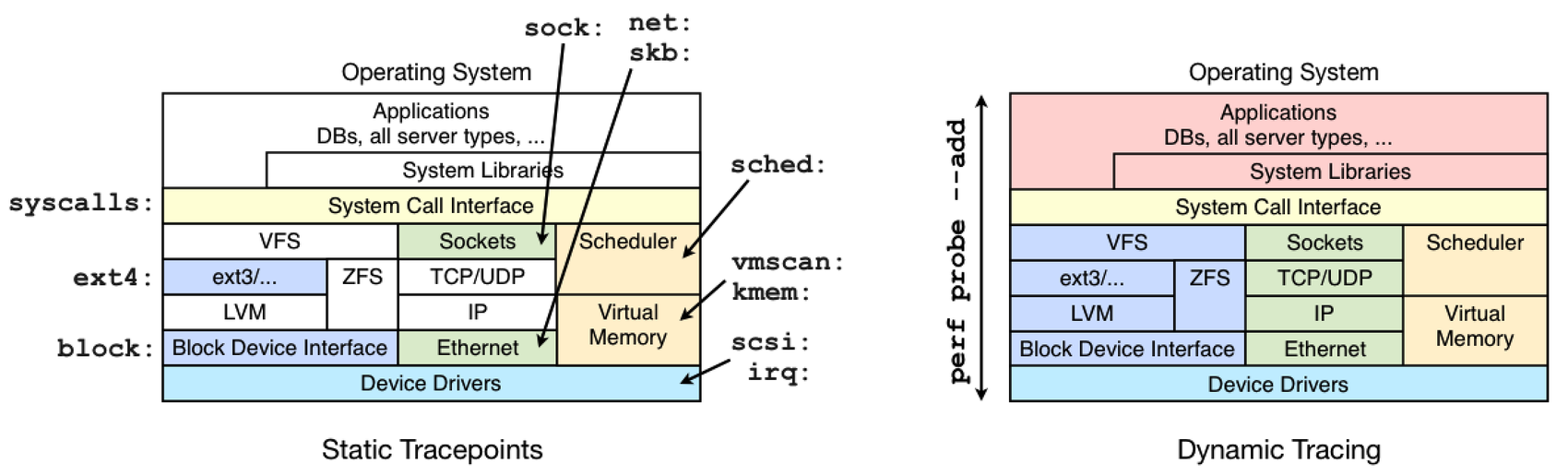
虽然动态跟踪可以看到一切,但它也是一个不稳定的接口,因为它是在检测原始代码。这意味着您开发的任何动态跟踪工具都可能在内核补丁或更新之后失效。首先尝试使用静态跟踪点,因为它们的接口应该更稳定。它们也可以更容易使用和理解,因为它们在设计时考虑了跟踪最终用户。
动态跟踪的一个好处是可以在实时系统上启用它,而无需重新启动任何东西。您可以使用已经运行的内核或应用程序,然后开始动态插桩,它(安全地)为内存中的指令打补丁以添加插桩。这意味着在您开始使用此功能之前,此功能的开销或税收为零。这一刻你的二进制文件还在不修改地全速运行,下一刻,它就在运行一些你动态添加的额外插装指令。一旦你完成了动态跟踪的会话,这些指令最终应该被删除。
使用动态跟踪和执行额外指令时的开销与插桩事件的频率乘以在每个插桩上所做的工作有关。
For examples of using dynamic tracing, see 6.5
6. Examples
These are some examples of perf_events, collected from a variety of 3.x Linux systems.
6.1. CPU Statistics
perf stat命令记录并总结关键的CPU计数器(PMCs)。下面是perf 3.5.7.2版本的代码:
# perf stat gzip file1
Performance counter stats for 'gzip file1':
1920.159821 task-clock # 0.991 CPUs utilized
13 context-switches # 0.007 K/sec
0 CPU-migrations # 0.000 K/sec
258 page-faults # 0.134 K/sec
5,649,595,479 cycles # 2.942 GHz [83.43%]
1,808,339,931 stalled-cycles-frontend # 32.01% frontend cycles idle [83.54%]
1,171,884,577 stalled-cycles-backend # 20.74% backend cycles idle [66.77%]
8,625,207,199 instructions # 1.53 insns per cycle
# 0.21 stalled cycles per insn [83.51%]
1,488,797,176 branches # 775.351 M/sec [82.58%]
53,395,139 branch-misses # 3.59% of all branches [83.78%]
1.936842598 seconds time elapsed
这包括每周期指令(IPC),标记为“insns per cycle”,或在早期版本中为“IPC”。这是一个经常检查的指标,IPC或其倒数CPI。更高的IPC值意味着更高的指令吞吐量,更低的值意味着更多的暂停周期。我通常认为IPC值高(例如,超过1.0)是好的,表明工作的最佳处理。然而,我想再次检查指令是什么,以防这是由于自旋循环:指令率很高,但实际工作的完成率很低。
现在在perf统计中包含了一些高级指标:前端周期空闲,后端周期空闲和每个insn的停顿周期( frontend cycles idle, backend cycles idle, and stalled cycles per insn.)。要真正理解这些,你需要一些CPU微架构的知识。
CPU Microarchitecture
前端和后端监控指标引用CPU流水线,也基于暂停计数。前端按顺序处理CPU指令。它包括取指令、分支预测和解码。解码后的指令成为后端处理的微操作(uops),并且可能会乱序。有关这些组件的更长的总结,请参阅Shannon Cepeda关于前端和后端的优秀帖子。
后端也可以并行处理多个uops;对于现代处理器,3到4个。除了流水线之外,IPC也可以变得大于1,因为每个CPU周期可以完成(“退役”)多条指令。
Stalled cycles per instruction与IPC(倒序)类似,但只计算停滞周期,这将用于内存或资源总线访问。这很容易理解:停顿是延迟,减少停顿。我真的很喜欢这个指标,希望它能像IPC/CPI一样普遍。我们称它为SCPI。
Detailed Mode
There is a “detailed” mode for perf stat:
# perf stat -d gzip file1
Performance counter stats for 'gzip file1':
1610.719530 task-clock # 0.998 CPUs utilized
20 context-switches # 0.012 K/sec
0 CPU-migrations # 0.000 K/sec
258 page-faults # 0.160 K/sec
5,491,605,997 cycles # 3.409 GHz [40.18%]
1,654,551,151 stalled-cycles-frontend # 30.13% frontend cycles idle [40.80%]
1,025,280,350 stalled-cycles-backend # 18.67% backend cycles idle [40.34%]
8,644,643,951 instructions # 1.57 insns per cycle
# 0.19 stalled cycles per insn [50.89%]
1,492,911,665 branches # 926.860 M/sec [50.69%]
53,471,580 branch-misses # 3.58% of all branches [51.21%]
1,938,889,736 L1-dcache-loads # 1203.741 M/sec [49.68%]
154,380,395 L1-dcache-load-misses # 7.96% of all L1-dcache hits [49.66%]
0 LLC-loads # 0.000 K/sec [39.27%]
0 LLC-load-misses # 0.00% of all LL-cache hits [39.61%]
1.614165346 seconds time elapsed
Specific Counters
Hardware cache event counters, seen in perf list, can be instrumented. Eg:
# perf list | grep L1-dcache
L1-dcache-loads [Hardware cache event]
L1-dcache-load-misses [Hardware cache event]
L1-dcache-stores [Hardware cache event]
L1-dcache-store-misses [Hardware cache event]
L1-dcache-prefetches [Hardware cache event]
L1-dcache-prefetch-misses [Hardware cache event]
# perf stat -e L1-dcache-loads,L1-dcache-load-misses,L1-dcache-stores gzip file1
Performance counter stats for 'gzip file1':
1,947,551,657 L1-dcache-loads
153,829,652 L1-dcache-misses
# 7.90% of all L1-dcache hits
1,171,475,286 L1-dcache-stores
1.538038091 seconds time elapsed
Raw Counters
Intel 64 and IA-32 Architectures Software Developer’s Manual Volume 3B: System Programming Guide, Part 2 and the BIOS and Kernel Developer’s Guide (BKDG) For AMD Family 10h Processors都有很多有趣的计数器,但大多数在perf列表中找不到。如果找到想要检测的事件,可以将其指定为原始事件,格式为:rUUEE,其中UU == umask, EE ==event number。下面是一个添加了几个原始计数器的例子:
# perf stat -e cycles,instructions,r80a2,r2b1 gzip file1
Performance counter stats for 'gzip file1':
5,586,963,328 cycles # 0.000 GHz
8,608,237,932 instructions # 1.54 insns per cycle
9,448,159 raw 0x80a2
11,855,777,803 raw 0x2b1
1.588618969 seconds time elapsed
如果我没有做错,那么r80a2已经测量了RESOURCE_STALLS。OTHER和r2b1已经检测了UOPS_DISPATCHED。核心:每个周期分派的uops数量。这很容易搞砸,你需要仔细检查你是否在处理器手册的正确页上。
如果您确实找到了一个很棒的原始计数器,请建议将其添加为perf_events中的别名,以便我们都可以在perf列表中找到它。
Other Options
perf子命令,特别是perf stat,有一个可以使用“-h”列出的大量选项集。我在这里包含了3.9.3版本的perf stat的完整输出,不是作为参考,而是作为接口的说明:
# perf stat -h
usage: perf stat [<options>] [<command>]
-e, --event <event> event selector. use 'perf list' to list available events
--filter <filter>
event filter
-i, --no-inherit child tasks do not inherit counters
-p, --pid <pid> stat events on existing process id
-t, --tid <tid> stat events on existing thread id
-a, --all-cpus system-wide collection from all CPUs
-g, --group put the counters into a counter group
-c, --scale scale/normalize counters
-v, --verbose be more verbose (show counter open errors, etc)
-r, --repeat <n> repeat command and print average + stddev (max: 100)
-n, --null null run - dont start any counters
-d, --detailed detailed run - start a lot of events
-S, --sync call sync() before starting a run
-B, --big-num print large numbers with thousands' separators
-C, --cpu <cpu> list of cpus to monitor in system-wide
-A, --no-aggr disable CPU count aggregation
-x, --field-separator <separator>
print counts with custom separator
-G, --cgroup <name> monitor event in cgroup name only
-o, --output <file> output file name
--append append to the output file
--log-fd <n> log output to fd, instead of stderr
--pre <command> command to run prior to the measured command
--post <command> command to run after to the measured command
-I, --interval-print <n>
print counts at regular interval in ms (>= 100)
--aggr-socket aggregate counts per processor socket
在进行自动化测试或微基准测试时,诸如–repeat、–sync、–pre和–post等选项非常有用。
6.2. Timed Profiling
perf_events可以基于以固定时间间隔对指令指针或堆栈跟踪进行采样来分析CPU使用情况(定时分析)。
以99赫兹(-F 99)对整个系统(-a,所有CPU)和堆栈跟踪(-g,调用图)对CPU堆栈进行采样,时间为10秒:
# perf record -F 99 -a -g -- sleep 30
[ perf record: Woken up 9 times to write data ]
[ perf record: Captured and wrote 3.135 MB perf.data (~136971 samples) ]
# ls -lh perf.data
-rw------- 1 root root 3.2M Jan 26 07:26 perf.data
选择99赫兹而不是100赫兹,是为了避免偶然地与某些周期性活动同步采样,从而产生偏斜的结果。这也是粗略的:您可能想要将其提高到更高的速率(例如,高达997赫兹)以获得更精细的分辨率,特别是如果您正在对活动的短脉冲进行采样,并且您仍然希望有足够的分辨率。请记住,更高的频率意味着更高的开销。
可以用多种方法处理perf_data文件。在最近的版本中,perf report命令会启动一个ncurses导航器来检查调用图。旧版本的perf(或者如果你在新版本中使用–stdio)将调用图打印为带百分比注释的树:
# perf report --stdio
# ========
# captured on: Mon Jan 26 07:26:40 2014
# hostname : dev2
# os release : 3.8.6-ubuntu-12-opt
# perf version : 3.8.6
# arch : x86_64
# nrcpus online : 8
# nrcpus avail : 8
# cpudesc : Intel(R) Xeon(R) CPU X5675 @ 3.07GHz
# cpuid : GenuineIntel,6,44,2
# total memory : 8182008 kB
# cmdline : /usr/bin/perf record -F 99 -a -g -- sleep 30
# event : name = cpu-clock, type = 1, config = 0x0, config1 = 0x0, config2 = ...
# HEADER_CPU_TOPOLOGY info available, use -I to display
# HEADER_NUMA_TOPOLOGY info available, use -I to display
# pmu mappings: software = 1, breakpoint = 5
# ========
#
# Samples: 22K of event 'cpu-clock'
# Event count (approx.): 22751
#
# Overhead Command Shared Object Symbol
# ........ ....... ................. ...............................
#
94.12% dd [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
|
--- _raw_spin_unlock_irqrestore
|
|--96.67%-- extract_buf
| extract_entropy_user
| urandom_read
| vfs_read
| sys_read
| system_call_fastpath
| read
|
|--1.69%-- account
| |
| |--99.72%-- extract_entropy_user
| | urandom_read
| | vfs_read
| | sys_read
| | system_call_fastpath
| | read
| --0.28%-- [...]
|
|--1.60%-- mix_pool_bytes.constprop.17
[...]
该树从cpu上的功能开始,一直追溯到祖先。这种方法被称为“基于被调用者的调用图”。这可以通过使用-G来翻转“反向调用图”,或者使用“caller”选项来翻转-G /–call-graph,而不是默认的“callee”。
在这个perf调用图中,最热(最频繁)的堆栈跟踪发生在90.99%的样本中,这是开销百分比和顶层堆栈叶子节点(94.12% x 96.67%,这是相对比率)的乘积。Perf报告也可以使用“-g graph”来显示绝对开销率,在这种情况下“90.99%”直接显示在堆栈叶子上:
94.12% dd [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
|
--- _raw_spin_unlock_irqrestore
|
|--90.99%-- extract_buf
[...]
如果用户级栈看起来不完整,您可以尝试使用“–call-graph dwarf”作为另一种技术来展开它们。请参阅4.4部分。
perf报告的输出可能有很多页长,读起来很麻烦。尝试从相同的数据生成火焰图。
6.3. Event Profiling
除了按时间间隔采样外,采样CPU硬件计数器触发的样本是另一种形式的CPU剖析,可用于更多地揭示缓存缺失、内存停顿周期和其他低级处理器事件。可用的事件可以通过perf list找到:
# perf list | grep Hardware
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
cache-references [Hardware event]
cache-misses [Hardware event]
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
stalled-cycles-frontend OR idle-cycles-frontend [Hardware event]
stalled-cycles-backend OR idle-cycles-backend [Hardware event]
ref-cycles [Hardware event]
L1-dcache-loads [Hardware cache event]
L1-dcache-load-misses [Hardware cache event]
L1-dcache-stores [Hardware cache event]
L1-dcache-store-misses [Hardware cache event]
[...]
对于其中的大多数情况,在每次发生时都收集一个堆栈会导致太多的开销,并会降低系统的速度,并改变目标的性能特征。通常只测量它们出现的一小部分就足够了,而不是全部。这可以通过指定触发事件集合的阈值(使用“-c”和一个计数)来实现。
例如,以下一行工具的1级数据缓存加载失败,每10 000次出现一次就会收集堆栈跟踪:
# perf record -e L1-dcache-load-misses -c 10000 -ag -- sleep 5
“-c计数”的机制是由处理器实现的,只有在达到阈值时才会中断内核。
有关指定自定义计数器的示例,请参阅前面的原始计数器部分,以及下一节有关skew的内容。
Skew and PEBS
事件分析有一个你在CPU分析中不会遇到的问题(定时采样)。使用定时采样,即使在中断和读取指令指针(IP)之间有一个小的亚微秒级的延迟,也没有关系。一些CPU分析器故意引入这种抖动,作为另一种避免同步采样的方法。但对于事件分析来说,这一点很重要:如果您试图在某些PMC事件上捕获IP,并且在PMC溢出和捕获IP之间有一段延迟,那么IP将指向错误的地址。This is skew。另一个问题是微操作是并行和乱序处理的,而指令指针指向恢复指令,而不是导致事件的指令。我之前说过这个。
解决方案是“精确采样”,在Intel上是PEBS(基于事件的精确采样),在AMD上是IBS(基于指令的采样)。它们使用CPU硬件支持来捕获事件发生时CPU的真实状态。perf可以通过在PMC事件名称后添加一个:p修饰符来使用精确采样,例如“-e instructions:p”。p越多,越准确。以下是tools/perf/Documentation/perf-list.txt(linux/perf-list.txt at master · torvalds/linux (github.com))中的文档:
The 'p' modifier can be used for specifying how precise the instruction
address should be. The 'p' modifier can be specified multiple times:
0 - SAMPLE_IP can have arbitrary skid
1 - SAMPLE_IP must have constant skid
2 - SAMPLE_IP requested to have 0 skid
3 - SAMPLE_IP must have 0 skid
在某些情况下,perf将默认使用精确采样,而无需指定它。执行命令“perf record -vv…”,可以查看“precise_ip”的值。还要注意,只有一些pmc支持peb。
如果PEBS对你不起作用,请检查dmesg:
# dmesg | grep -i pebs
[ 0.387014] Performance Events: PEBS fmt1+, SandyBridge events, 16-deep LBR, full-width counters, Intel PMU driver.
[ 0.387034] core: PEBS disabled due to CPU errata, please upgrade microcode
The fix (on Intel):
# apt-get install -y intel-microcode
[...]
intel-microcode: microcode will be updated at next boot
Processing triggers for initramfs-tools (0.125ubuntu5) ...
update-initramfs: Generating /boot/initrd.img-4.8.0-41-generic
# reboot
(system reboots)
# dmesg | grep -i pebs
[ 0.386596] Performance Events: PEBS fmt1+, SandyBridge events, 16-deep LBR, full-width counters, Intel PMU driver.
#
XXX: Need to cover more PEBS problems and other caveats.
6.4. Static Kernel Tracing
下面的例子演示了静态跟踪:跟踪点和其他静态事件的插装。
Counting Syscalls
下面这个简单的单行代码对被执行命令的系统调用进行计数,并打印出(非零计数的)摘要:
# perf stat -e 'syscalls:sys_enter_*' gzip file1 2>&1 | awk '$1 != 0'
Performance counter stats for 'gzip file1':
1 syscalls:sys_enter_utimensat
1 syscalls:sys_enter_unlink
5 syscalls:sys_enter_newfstat
1,603 syscalls:sys_enter_read
3,201 syscalls:sys_enter_write
5 syscalls:sys_enter_access
1 syscalls:sys_enter_fchmod
1 syscalls:sys_enter_fchown
6 syscalls:sys_enter_open
9 syscalls:sys_enter_close
8 syscalls:sys_enter_mprotect
1 syscalls:sys_enter_brk
1 syscalls:sys_enter_munmap
1 syscalls:sys_enter_set_robust_list
1 syscalls:sys_enter_futex
1 syscalls:sys_enter_getrlimit
5 syscalls:sys_enter_rt_sigprocmask
14 syscalls:sys_enter_rt_sigaction
1 syscalls:sys_enter_exit_group
1 syscalls:sys_enter_set_tid_address
14 syscalls:sys_enter_mmap
1.543990940 seconds time elapsed
在这种情况下,分析了gzip命令。报告显示有3201个write()系统调用,其中read()系统调用的数量是这个数字的一半。许多其他系统调用是由于进程和库初始化引起的。
使用系统调用跟踪器strace -c可以看到类似的报告,但它可能比perf产生更高的开销,因为perf在内核中缓冲了数据。
perf vs strace
进一步解释两者的区别:strace的当前实现使用ptrace(2)连接到目标进程,并在系统调用期间停止它,就像调试器一样。这很暴力,可能会导致严重的开销。为了说明这一点,我们使用perf和strace单独运行了下面这个系统调用繁重的程序。这里只包含了显示其性能的那一行输出:
# dd if=/dev/zero of=/dev/null bs=512 count=10000k
5242880000 bytes (5.2 GB) copied, 3.53031 s, 1.5 GB/s
# perf stat -e 'syscalls:sys_enter_*' dd if=/dev/zero of=/dev/null bs=512 count=10000k
5242880000 bytes (5.2 GB) copied, 9.14225 s, 573 MB/s
# strace -c dd if=/dev/zero of=/dev/null bs=512 count=10000k
5242880000 bytes (5.2 GB) copied, 218.915 s, 23.9 MB/s
使用perf时,程序的运行速度要慢2.5倍。但使用strace时,速度慢了62倍。这可能是最坏情况下的结果:如果系统调用不那么频繁,工具之间的差异就不会那么大。
perf的最新版本包含了一个trace子命令,以提供与strace类似的功能,但开销要低得多。
New Processes
跟踪由“man ls”触发的新进程:
# perf record -e sched:sched_process_exec -a
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.064 MB perf.data (~2788 samples) ]
# perf report -n --sort comm --stdio
[...]
# Overhead Samples Command
# ........ ............ .......
#
11.11% 1 troff
11.11% 1 tbl
11.11% 1 preconv
11.11% 1 pager
11.11% 1 nroff
11.11% 1 man
11.11% 1 locale
11.11% 1 grotty
11.11% 1 groff
执行了9条不同的命令,每条命令执行一次。我使用-n打印“Samples”列,使用“–sort comm”自定义剩余的列。
这是通过跟踪sched:sched_process_exec来工作的,当进程运行exec()来执行不同的二进制文件时。这通常是创建新进程的方式,但并不总是如此。应用也许会fork()来创建一个工作进程池,但不是用exec()创建一个不同的二进制文件。应用程序也可以重新执行:再次调用exec(),通常是为了清理其地址空间。在这种情况下,它将被这个exec跟踪点看到,但它不是一个新进程。
sched:sched_process_fork跟踪点只能捕获通过fork()创建的新进程。这样做的缺点是,被标识的进程是父进程,而不是新目标进程,因为新进程还没有exec()它的最终程序。
Outbound Connections
有时,需要仔细检查服务器发起了哪些网络连接、发起了哪些进程以及发起的原因。你可能会感到惊讶。理解这些连接很重要,因为它们可能是延迟的来源。
对于这个例子,我有一个完全空闲的ubuntu服务器,在跟踪时我将使用ssh登录到它。我将通过connect()系统调用跟踪出站连接。假设我正在通过SSH执行入站连接,是否会有任何出站连接?
# perf record -e syscalls:sys_enter_connect -a
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.057 MB perf.data (~2489 samples) ]
# perf report --stdio
# ========
# captured on: Tue Jan 28 10:53:38 2014
# hostname : ubuntu
# os release : 3.5.0-23-generic
# perf version : 3.5.7.2
# arch : x86_64
# nrcpus online : 2
# nrcpus avail : 2
# cpudesc : Intel(R) Core(TM) i7-3820QM CPU @ 2.70GHz
# cpuid : GenuineIntel,6,58,9
# total memory : 1011932 kB
# cmdline : /usr/bin/perf_3.5.0-23 record -e syscalls:sys_enter_connect -a
# event : name = syscalls:sys_enter_connect, type = 2, config = 0x38b, ...
# HEADER_CPU_TOPOLOGY info available, use -I to display
# HEADER_NUMA_TOPOLOGY info available, use -I to display
# ========
#
# Samples: 21 of event 'syscalls:sys_enter_connect'
# Event count (approx.): 21
#
# Overhead Command Shared Object Symbol
# ........ ....... .................. ...........................
#
52.38% sshd libc-2.15.so [.] __GI___connect_internal
19.05% groups libc-2.15.so [.] __GI___connect_internal
9.52% sshd libpthread-2.15.so [.] __connect_internal
9.52% mesg libc-2.15.so [.] __GI___connect_internal
9.52% bash libc-2.15.so [.] __GI___connect_internal
报告显示,sshd、groups、mesg和bash都在执行connect()系统调用。想起来了吗?
从connect()的栈跟踪可以解释这一点:
# perf record -e syscalls:sys_enter_connect -ag
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.057 MB perf.data (~2499 samples) ]
# perf report --stdio
[...]
55.00% sshd libc-2.15.so [.] __GI___connect_internal
|
--- __GI___connect_internal
|
|--27.27%-- add_one_listen_addr.isra.0
|
|--27.27%-- __nscd_get_mapping
| __nscd_get_map_ref
|
|--27.27%-- __nscd_open_socket
--18.18%-- [...]
20.00% groups libc-2.15.so [.] __GI___connect_internal
|
--- __GI___connect_internal
|
|--50.00%-- __nscd_get_mapping
| __nscd_get_map_ref
|
--50.00%-- __nscd_open_socket
10.00% mesg libc-2.15.so [.] __GI___connect_internal
|
--- __GI___connect_internal
|
|--50.00%-- __nscd_get_mapping
| __nscd_get_map_ref
|
--50.00%-- __nscd_open_socket
10.00% bash libc-2.15.so [.] __GI___connect_internal
|
--- __GI___connect_internal
|
|--50.00%-- __nscd_get_mapping
| __nscd_get_map_ref
|
--50.00%-- __nscd_open_socket
5.00% sshd libpthread-2.15.so [.] __connect_internal
|
--- __connect_internal
啊,这些是nscd调用:名称服务缓存守护进程。如果你看到的是十六进制数而不是函数名,则需要安装调试信息:请参阅前面关于符号的部分。这些nscd调用可能是通过调用getaddrinfo()触发的,服务器软件可能使用它来解析IP地址以记录日志,或匹配配置文件中的主机名。浏览堆栈跟踪应该能找出原因。
对于sshd来说,这是通过add_one_listen_addr()调用的:这个名称只有在添加openssh-server-dbgsym包之后才可见。不幸的是,堆栈跟踪在add_one_listen_add()之后不再继续。我可以浏览OpenSSH代码,找出我们调用add_one_listen_add()的原因,或者,我可以让堆栈跟踪工作。请参阅前面关于堆栈跟踪的部分。
我快速浏览了一下OpenSSH代码,看起来这个代码路径是由于从sshd_config文件中解析ListenAddress,它可以包含IP地址或主机名。
Socket Buffers
跟踪套接字缓冲区的使用和栈跟踪,是识别是什么导致了套接字或网络I/O的一种方法。
# perf record -e 'skb:consume_skb' -ag
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.065 MB perf.data (~2851 samples) ]
# perf report
[...]
74.42% swapper [kernel.kallsyms] [k] consume_skb
|
--- consume_skb
arp_process
arp_rcv
__netif_receive_skb_core
__netif_receive_skb
netif_receive_skb
virtnet_poll
net_rx_action
__do_softirq
irq_exit
do_IRQ
ret_from_intr
default_idle
cpu_idle
start_secondary
25.58% sshd [kernel.kallsyms] [k] consume_skb
|
--- consume_skb
dev_kfree_skb_any
free_old_xmit_skbs.isra.24
start_xmit
dev_hard_start_xmit
sch_direct_xmit
dev_queue_xmit
ip_finish_output
ip_output
ip_local_out
ip_queue_xmit
tcp_transmit_skb
tcp_write_xmit
__tcp_push_pending_frames
tcp_sendmsg
inet_sendmsg
sock_aio_write
do_sync_write
vfs_write
sys_write
system_call_fastpath
__write_nocancel
交换器栈显示了由中断触发的网络接收路径。sshd路径显示写操作。
6.5. Static User Tracing
在后来的4.x系列内核中增加了对该特性的支持。下面演示了Linux 4.10(带有额外的补丁集)以及跟踪Node.js的USDT探测:
# perf buildid-cache --add `which node`
# perf list | grep sdt_node
sdt_node:gc__done [SDT event]
sdt_node:gc__start [SDT event]
sdt_node:http__client__request [SDT event]
sdt_node:http__client__response [SDT event]
sdt_node:http__server__request [SDT event]
sdt_node:http__server__response [SDT event]
sdt_node:net__server__connection [SDT event]
sdt_node:net__stream__end [SDT event]
# perf record -e sdt_node:http__server__request -a
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.446 MB perf.data (3 samples) ]
# perf script
node 7646 [002] 361.012364: sdt_node:http__server__request: (dc2e69)
node 7646 [002] 361.204718: sdt_node:http__server__request: (dc2e69)
node 7646 [002] 361.363043: sdt_node:http__server__request: (dc2e69)
xxx 请告诉我,包括如何使用参数。
如果您使用的是较旧的内核,例如Linux 4.4-4.9,您可能可以通过调整使它们工作(我甚至用ftrace对较旧的内核进行了修改),但由于它们一直在开发中,我还没有看到lkml以外的文档,所以您需要弄清楚。(在这个内核范围内,您可能会找到更多关于使用bcc/eBPF跟踪它们的文档,包括使用trace.py工具。)
6.6. Dynamic Tracing
For kernel analysis, I’m using CONFIG_KPROBES=y and CONFIG_KPROBE_EVENTS=y, to enable kernel dynamic tracing, and CONFIG_FRAME_POINTER=y, for frame pointer-based kernel stacks. For user-level analysis, CONFIG_UPROBES=y and CONFIG_UPROBE_EVENTS=y, for user-level dynamic tracing.
要将探测点添加到应用程序中,您可以使用以下步骤:
-
确定要分析的函数或代码段。这可以通过对应用程序进行静态代码分析或使用调试器进行动态调试来实现。
-
使用
perf probe命令创建一个新的探测点,并指定要分析的函数或代码段以及探测点名称。例如:复制代码perf probe -x /path/to/binary -a function_name这个命令将在二进制文件
/path/to/binary中的函数function_name上创建一个探测点。 -
运行应用程序,并让
perf probe开始收集数据。探测点会在应用程序执行时自动触发,并记录相应的函数调用、参数值和返回值等信息。 -
分析收集的数据,以确定性能瓶颈或其他问题。可以使用
perf record和perf report等工具来收集和分析探测点数据。
请注意,在将探测点添加到应用程序中时,请确保不会对应用程序的正确性和稳定性产生负面影响。此外,为了确保探测点的正确性和安全性,建议在测试环境中进行探测点的开发和测试,并由经验丰富的开发人员进行实施。
Kernel: tcp_sendmsg()
This example shows instrumenting the kernel tcp_sendmsg() function on the Linux 3.9.3 kernel:
# perf probe --add tcp_sendmsg
Failed to find path of kernel module.
Added new event:
probe:tcp_sendmsg (on tcp_sendmsg)
You can now use it in all perf tools, such as:
perf record -e probe:tcp_sendmsg -aR sleep 1
这会添加一个新的tracepoint事件。它建议使用-R选项来收集原始样本记录,这已经是tracepoints的默认选项。跟踪此事件5秒,记录堆栈跟踪:
# perf record -e probe:tcp_sendmsg -a -g -- sleep 5
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.228 MB perf.data (~9974 samples) ]
And the report:
# perf report --stdio
# ========
# captured on: Fri Jan 31 20:10:14 2014
# hostname : pgbackup
# os release : 3.9.3-ubuntu-12-opt
# perf version : 3.9.3
# arch : x86_64
# nrcpus online : 8
# nrcpus avail : 8
# cpudesc : Intel(R) Xeon(R) CPU E5-2670 0 @ 2.60GHz
# cpuid : GenuineIntel,6,45,7
# total memory : 8179104 kB
# cmdline : /lib/modules/3.9.3/build/tools/perf/perf record -e probe:tcp_sendmsg -a -g -- sleep 5
# event : name = probe:tcp_sendmsg, type = 2, config = 0x3b2, config1 = 0x0, config2 = 0x0, ...
# HEADER_CPU_TOPOLOGY info available, use -I to display
# HEADER_NUMA_TOPOLOGY info available, use -I to display
# pmu mappings: software = 1, tracepoint = 2, breakpoint = 5
# ========
#
# Samples: 12 of event 'probe:tcp_sendmsg'
# Event count (approx.): 12
#
# Overhead Command Shared Object Symbol
# ........ ....... ................. ...............
#
100.00% sshd [kernel.kallsyms] [k] tcp_sendmsg
|
--- tcp_sendmsg
sock_aio_write
do_sync_write
vfs_write
sys_write
system_call_fastpath
__write_nocancel
|
|--8.33%-- 0x50f00000001b810
--91.67%-- [...]
This shows the path from the write() system call to tcp_sendmsg().
You can delete these dynamic tracepoints if you want after use, using perf probe --del.
Kernel: tcp_sendmsg() with size
如果你的内核有debuginfo (CONFIG_DEBUG_INFO=y),你可以从函数中提取出内核变量。这是一个在Linux 3.13.1上检查size_t(整数)的简单例子。
Listing variables available for tcp_sendmsg():
# perf probe -V tcp_sendmsg
Available variables at tcp_sendmsg
@<tcp_sendmsg+0>
size_t size
struct kiocb* iocb
struct msghdr* msg
struct sock* sk
Creating a probe for tcp_sendmsg() with the “size” variable:
# perf probe --add 'tcp_sendmsg size'
Added new event:
probe:tcp_sendmsg (on tcp_sendmsg with size)
You can now use it in all perf tools, such as:
perf record -e probe:tcp_sendmsg -aR sleep 1
Tracing this probe:
# perf record -e probe:tcp_sendmsg -a
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.052 MB perf.data (~2252 samples) ]
# perf script
# ========
# captured on: Fri Jan 31 23:49:55 2014
# hostname : dev1
# os release : 3.13.1-ubuntu-12-opt
# perf version : 3.13.1
# arch : x86_64
# nrcpus online : 2
# nrcpus avail : 2
# cpudesc : Intel(R) Xeon(R) CPU E5645 @ 2.40GHz
# cpuid : GenuineIntel,6,44,2
# total memory : 1796024 kB
# cmdline : /usr/bin/perf record -e probe:tcp_sendmsg -a
# event : name = probe:tcp_sendmsg, type = 2, config = 0x1dd, config1 = 0x0, config2 = ...
# HEADER_CPU_TOPOLOGY info available, use -I to display
# HEADER_NUMA_TOPOLOGY info available, use -I to display
# pmu mappings: software = 1, tracepoint = 2, breakpoint = 5
# ========
#
sshd 1301 [001] 502.424719: probe:tcp_sendmsg: (ffffffff81505d80) size=b0
sshd 1301 [001] 502.424814: probe:tcp_sendmsg: (ffffffff81505d80) size=40
sshd 2371 [000] 502.952590: probe:tcp_sendmsg: (ffffffff81505d80) size=27
sshd 2372 [000] 503.025023: probe:tcp_sendmsg: (ffffffff81505d80) size=3c0
sshd 2372 [001] 503.203776: probe:tcp_sendmsg: (ffffffff81505d80) size=98
sshd 2372 [001] 503.281312: probe:tcp_sendmsg: (ffffffff81505d80) size=2d0
sshd 2372 [001] 503.461358: probe:tcp_sendmsg: (ffffffff81505d80) size=30
sshd 2372 [001] 503.670239: probe:tcp_sendmsg: (ffffffff81505d80) size=40
sshd 2372 [001] 503.742565: probe:tcp_sendmsg: (ffffffff81505d80) size=140
sshd 2372 [001] 503.822005: probe:tcp_sendmsg: (ffffffff81505d80) size=20
sshd 2371 [000] 504.118728: probe:tcp_sendmsg: (ffffffff81505d80) size=30
sshd 2371 [000] 504.192575: probe:tcp_sendmsg: (ffffffff81505d80) size=70
[...]
The size is shown as hexadecimal.
Kernel: tcp_sendmsg() line number and local variable
With debuginfo, perf_events can create tracepoints for lines within kernel functions. Listing available line probes for tcp_sendmsg():
# perf probe -L tcp_sendmsg
<tcp_sendmsg@/mnt/src/linux-3.14.5/net/ipv4/tcp.c:0>
0 int tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
size_t size)
2 {
struct iovec *iov;
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
6 int iovlen, flags, err, copied = 0;
7 int mss_now = 0, size_goal, copied_syn = 0, offset = 0;
bool sg;
long timeo;
[...]
79 while (seglen > 0) {
int copy = 0;
81 int max = size_goal;
skb = tcp_write_queue_tail(sk);
84 if (tcp_send_head(sk)) {
85 if (skb->ip_summed == CHECKSUM_NONE)
max = mss_now;
87 copy = max - skb->len;
}
90 if (copy <= 0) {
new_segment:
[...]
This is Linux 3.14.5; your kernel version may look different. Lets check what variables are available on line 81:
# perf probe -V tcp_sendmsg:81
Available variables at tcp_sendmsg:81
@<tcp_sendmsg+537>
bool sg
int copied
int copied_syn
int flags
int mss_now
int offset
int size_goal
long int timeo
size_t seglen
struct iovec* iov
struct sock* sk
unsigned char* from
下面跟踪第81行,在循环中检查变量seglen:
# perf probe --add 'tcp_sendmsg:81 seglen'
Added new event:
probe:tcp_sendmsg (on tcp_sendmsg:81 with seglen)
You can now use it in all perf tools, such as:
perf record -e probe:tcp_sendmsg -aR sleep 1
# perf record -e probe:tcp_sendmsg -a
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.188 MB perf.data (~8200 samples) ]
# perf script
sshd 4652 [001] 2082360.931086: probe:tcp_sendmsg: (ffffffff81642ca9) seglen=0x80
app_plugin.pl 2400 [001] 2082360.970489: probe:tcp_sendmsg: (ffffffff81642ca9) seglen=0x20
postgres 2422 [000] 2082360.970703: probe:tcp_sendmsg: (ffffffff81642ca9) seglen=0x52
app_plugin.pl 2400 [000] 2082360.970890: probe:tcp_sendmsg: (ffffffff81642ca9) seglen=0x7b
postgres 2422 [001] 2082360.971099: probe:tcp_sendmsg: (ffffffff81642ca9) seglen=0xb
app_plugin.pl 2400 [000] 2082360.971140: probe:tcp_sendmsg: (ffffffff81642ca9) seglen=0x55
[...]
这太神奇了。请记住,您还可以使用–filter包括内核过滤,以匹配您想要的数据。
User: malloc()
虽然这是一个有趣的例子,但我想马上说明malloc()调用非常频繁,因此您需要考虑跟踪这样的调用的开销。
Adding a libc malloc() probe:
# perf probe -x /lib/x86_64-linux-gnu/libc-2.15.so --add malloc
Added new event:
probe_libc:malloc (on 0x82f20)
You can now use it in all perf tools, such as:
perf record -e probe_libc:malloc -aR sleep 1
Tracing it system-wide:
# perf record -e probe_libc:malloc -a
^C[ perf record: Woken up 12 times to write data ]
[ perf record: Captured and wrote 3.522 MB perf.data (~153866 samples) ]
The report:
# perf report -n
[...]
# Samples: 45K of event 'probe_libc:malloc'
# Event count (approx.): 45158
#
# Overhead Samples Command Shared Object Symbol
# ........ ............ ............... ............. ..........
#
42.72% 19292 apt-config libc-2.15.so [.] malloc
19.71% 8902 grep libc-2.15.so [.] malloc
7.88% 3557 sshd libc-2.15.so [.] malloc
6.25% 2824 sed libc-2.15.so [.] malloc
6.06% 2738 which libc-2.15.so [.] malloc
4.12% 1862 update-motd-upd libc-2.15.so [.] malloc
3.72% 1680 stat libc-2.15.so [.] malloc
1.68% 758 login libc-2.15.so [.] malloc
1.21% 546 run-parts libc-2.15.so [.] malloc
1.21% 545 ls libc-2.15.so [.] malloc
0.80% 360 dircolors libc-2.15.so [.] malloc
0.56% 252 tr libc-2.15.so [.] malloc
0.54% 242 top libc-2.15.so [.] malloc
0.49% 222 irqbalance libc-2.15.so [.] malloc
0.44% 200 dpkg libc-2.15.so [.] malloc
0.38% 173 lesspipe libc-2.15.so [.] malloc
0.29% 130 update-motd-fsc libc-2.15.so [.] malloc
0.25% 112 uname libc-2.15.so [.] malloc
0.24% 108 cut libc-2.15.so [.] malloc
0.23% 104 groups libc-2.15.so [.] malloc
0.21% 94 release-upgrade libc-2.15.so [.] malloc
0.18% 82 00-header libc-2.15.so [.] malloc
0.14% 62 mesg libc-2.15.so [.] malloc
0.09% 42 update-motd-reb libc-2.15.so [.] malloc
0.09% 40 date libc-2.15.so [.] malloc
0.08% 35 bash libc-2.15.so [.] malloc
0.08% 35 basename libc-2.15.so [.] malloc
0.08% 34 dirname libc-2.15.so [.] malloc
0.06% 29 sh libc-2.15.so [.] malloc
0.06% 26 99-footer libc-2.15.so [.] malloc
0.05% 24 cat libc-2.15.so [.] malloc
0.04% 18 expr libc-2.15.so [.] malloc
0.04% 17 rsyslogd libc-2.15.so [.] malloc
0.03% 12 stty libc-2.15.so [.] malloc
0.00% 1 cron libc-2.15.so [.] malloc
This shows the most malloc() calls were by apt-config, while I was tracing.
User: malloc() with size
As of the Linux 3.13.1 kernel, this is not supported yet:
# perf probe -x /lib/x86_64-linux-gnu/libc-2.15.so --add 'malloc size'
Debuginfo-analysis is not yet supported with -x/--exec option.
Error: Failed to add events. (-38)
As a workaround, you can access the registers (on Linux 3.7+). For example, on x86_64:
# perf probe -x /lib64/libc-2.17.so '--add=malloc size=%di'
probe_libc:malloc (on 0x800c0 with size=%di)
6.7. Scheduler Analysis
perf sched子命令提供了许多工具,用于分析内核CPU调度器的行为。你可以用它来识别和量化调度器延迟的问题。
该工具当前的开销(从Linux 4.10开始)可能是显而易见的,因为它检测调度器事件并将其转储到perf.data文件以供后续分析。例如:
# perf sched record -- sleep 1
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 1.886 MB perf.data (13502 samples) ]
每秒1.9 mb,包括13,502个样本。大小和速率将与您的工作负载和CPU数量相关(本例是运行软件构建的8个CPU服务器)。将事件写入文件系统的方式得到了优化:它只被唤醒一次,读取事件缓冲区并将它们写入磁盘,这大大降低了开销。也就是说,检测所有调度器事件和将事件数据写入文件系统仍然有很大的开销。这些事件:
# perf script --header
# ========
# captured on: Sun Feb 26 19:40:00 2017
# hostname : bgregg-xenial
# os release : 4.10-virtual
# perf version : 4.10
# arch : x86_64
# nrcpus online : 8
# nrcpus avail : 8
# cpudesc : Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz
# cpuid : GenuineIntel,6,62,4
# total memory : 15401700 kB
# cmdline : /usr/bin/perf sched record -- sleep 1
# event : name = sched:sched_switch, , id = { 2752, 2753, 2754, 2755, 2756, 2757, 2758, 2759 }, type = 2, size = 11...
# event : name = sched:sched_stat_wait, , id = { 2760, 2761, 2762, 2763, 2764, 2765, 2766, 2767 }, type = 2, size =...
# event : name = sched:sched_stat_sleep, , id = { 2768, 2769, 2770, 2771, 2772, 2773, 2774, 2775 }, type = 2, size ...
# event : name = sched:sched_stat_iowait, , id = { 2776, 2777, 2778, 2779, 2780, 2781, 2782, 2783 }, type = 2, size...
# event : name = sched:sched_stat_runtime, , id = { 2784, 2785, 2786, 2787, 2788, 2789, 2790, 2791 }, type = 2, siz...
# event : name = sched:sched_process_fork, , id = { 2792, 2793, 2794, 2795, 2796, 2797, 2798, 2799 }, type = 2, siz...
# event : name = sched:sched_wakeup, , id = { 2800, 2801, 2802, 2803, 2804, 2805, 2806, 2807 }, type = 2, size = 11...
# event : name = sched:sched_wakeup_new, , id = { 2808, 2809, 2810, 2811, 2812, 2813, 2814, 2815 }, type = 2, size ...
# event : name = sched:sched_migrate_task, , id = { 2816, 2817, 2818, 2819, 2820, 2821, 2822, 2823 }, type = 2, siz...
# HEADER_CPU_TOPOLOGY info available, use -I to display
# HEADER_NUMA_TOPOLOGY info available, use -I to display
# pmu mappings: breakpoint = 5, power = 7, software = 1, tracepoint = 2, msr = 6
# HEADER_CACHE info available, use -I to display
# missing features: HEADER_BRANCH_STACK HEADER_GROUP_DESC HEADER_AUXTRACE HEADER_STAT
# ========
#
perf 16984 [005] 991962.879966: sched:sched_wakeup: comm=perf pid=16999 prio=120 target_cpu=005
[...]
如果开销是一个问题,您可以使用我的eBPF/bcc工具(https://www.brendangregg.com/ebpf.html#bcc),包括runqlat和runqlen,它们使用调度器事件的内核摘要,进一步减少开销。perf sched的一个优点是,您不局限于摘要。如果捕获了一个间歇事件,可以用自定义的方式分析这些记录的事件,直到理解问题为止,而不需要再次捕获它。
捕获的跟踪文件可以通过多种方式报告,帮助消息总结如下:
# perf sched -h
Usage: perf sched [] {record|latency|map|replay|script|timehist}
-D, --dump-raw-trace dump raw trace in ASCII
-f, --force don't complain, do it
-i, --input input file name
-v, --verbose be more verbose (show symbol address, etc)
Perf sched latency将按任务汇总调度器延迟,包括平均和最大延迟:
# perf sched latency
-----------------------------------------------------------------------------------------------------------------
Task | Runtime ms | Switches | Average delay ms | Maximum delay ms | Maximum delay at |
-----------------------------------------------------------------------------------------------------------------
cat:(6) | 12.002 ms | 6 | avg: 17.541 ms | max: 29.702 ms | max at: 991962.948070 s
ar:17043 | 3.191 ms | 1 | avg: 13.638 ms | max: 13.638 ms | max at: 991963.048070 s
rm:(10) | 20.955 ms | 10 | avg: 11.212 ms | max: 19.598 ms | max at: 991963.404069 s
objdump:(6) | 35.870 ms | 8 | avg: 10.969 ms | max: 16.509 ms | max at: 991963.424443 s
:17008:17008 | 462.213 ms | 50 | avg: 10.464 ms | max: 35.999 ms | max at: 991963.120069 s
grep:(7) | 21.655 ms | 11 | avg: 9.465 ms | max: 24.502 ms | max at: 991963.464082 s
fixdep:(6) | 81.066 ms | 8 | avg: 9.023 ms | max: 19.521 ms | max at: 991963.120068 s
mv:(10) | 30.249 ms | 14 | avg: 8.380 ms | max: 21.688 ms | max at: 991963.200073 s
ld:(3) | 14.353 ms | 6 | avg: 7.376 ms | max: 15.498 ms | max at: 991963.452070 s
recordmcount:(7) | 14.629 ms | 9 | avg: 7.155 ms | max: 18.964 ms | max at: 991963.292100 s
svstat:17067 | 1.862 ms | 1 | avg: 6.142 ms | max: 6.142 ms | max at: 991963.280069 s
cc1:(21) | 6013.457 ms | 1138 | avg: 5.305 ms | max: 44.001 ms | max at: 991963.436070 s
gcc:(18) | 43.596 ms | 40 | avg: 3.905 ms | max: 26.994 ms | max at: 991963.380069 s
ps:17073 | 27.158 ms | 4 | avg: 3.751 ms | max: 8.000 ms | max at: 991963.332070 s
[...]
为了说明这是如何测量和计算的,我将展示导致top事件的“最大延迟”为29.702 ms的事件。下面是perf sched script中的原始事件:
sh 17028 [001] 991962.918368: sched:sched_wakeup_new: comm=sh pid=17030 prio=120 target_cpu=002
[...]
cc1 16819 [002] 991962.948070: sched:sched_switch: prev_comm=cc1 prev_pid=16819 prev_prio=120
prev_state=R ==> next_comm=sh next_pid=17030 next_prio=120
[...]
从唤醒(991962.918368,单位为秒)到上下文切换(991962.948070)的时间是29.702 ms。该进程在原始事件中被列为“sh”(shell),但很快执行了“cat”,因此在perf sched延迟输出中显示为“cat”。
perf sched map显示了所有的CPU和上下文切换事件,其中的列表示每个CPU正在做什么以及什么时候做。这是你可以在调度器分析gui中看到的可视化数据(包括perf时间图,布局旋转了90度)。示例输出:
# perf sched map
*A0 991962.879971 secs A0 => perf:16999
A0 *B0 991962.880070 secs B0 => cc1:16863
*C0 A0 B0 991962.880070 secs C0 => :17023:17023
*D0 C0 A0 B0 991962.880078 secs D0 => ksoftirqd/0:6
D0 C0 *E0 A0 B0 991962.880081 secs E0 => ksoftirqd/3:28
D0 C0 *F0 A0 B0 991962.880093 secs F0 => :17022:17022
*G0 C0 F0 A0 B0 991962.880108 secs G0 => :17016:17016
G0 C0 F0 *H0 B0 991962.880256 secs H0 => migration/5:39
G0 C0 F0 *I0 B0 991962.880276 secs I0 => perf:16984
G0 C0 F0 *J0 B0 991962.880687 secs J0 => cc1:16996
G0 C0 *K0 J0 B0 991962.881839 secs K0 => cc1:16945
G0 C0 K0 J0 *L0 B0 991962.881841 secs L0 => :17020:17020
G0 C0 K0 J0 *M0 B0 991962.882289 secs M0 => make:16637
G0 C0 K0 J0 *N0 B0 991962.883102 secs N0 => make:16545
G0 *O0 K0 J0 N0 B0 991962.883880 secs O0 => cc1:16819
G0 *A0 O0 K0 J0 N0 B0 991962.884069 secs
G0 A0 O0 K0 *P0 J0 N0 B0 991962.884076 secs P0 => rcu_sched:7
G0 A0 O0 K0 *Q0 J0 N0 B0 991962.884084 secs Q0 => cc1:16831
G0 A0 O0 K0 Q0 J0 *R0 B0 991962.884843 secs R0 => cc1:16825
G0 *S0 O0 K0 Q0 J0 R0 B0 991962.885636 secs S0 => cc1:16900
G0 S0 O0 *T0 Q0 J0 R0 B0 991962.886893 secs T0 => :17014:17014
G0 S0 O0 *K0 Q0 J0 R0 B0 991962.886917 secs
[...]
这是一个有8个CPU的系统,你可以看到每个CPU从左边开始有8列。有些CPU列开始为空,因为我们还没有在概要文件开始时跟踪该CPU上的事件。它们很快就变得很拥挤。
你看到的两个字符编码(“A0”, “C0”)是任务的标识符,映射在右边(“=>”)。这比使用进程(任务)id更简洁。“*”表示哪个CPU有上下文切换事件,以及正在运行的新事件。例如,最后一行显示在991962.886917(秒)CPU 4上上下文切换到K0(一个“cc1”进程,PID 16945)。
这个例子来自一个繁忙的系统。下面是一个空闲的系统:
# perf sched map
*A0 993552.887633 secs A0 => perf:26596
*. A0 993552.887781 secs . => swapper:0
. *B0 993552.887843 secs B0 => migration/5:39
. *. 993552.887858 secs
. . *A0 993552.887861 secs
. *C0 A0 993552.887903 secs C0 => bash:26622
. *. A0 993552.888020 secs
. *D0 . A0 993552.888074 secs D0 => rcu_sched:7
. *. . A0 993552.888082 secs
. . *C0 A0 993552.888143 secs
. *. . C0 A0 993552.888173 secs
. . . *B0 A0 993552.888439 secs
. . . *. A0 993552.888454 secs
. *C0 . . A0 993552.888457 secs
. C0 . . *. 993552.889257 secs
. *. . . . 993552.889764 secs
. . *E0 . . 993552.889767 secs E0 => bash:7902
[...]
空闲cpu显示为“。”。
请记住检查时间戳列以理解这种可视化(gui使用时间戳列作为维度,这更容易理解,但这里只是列出了数字)。它也只显示上下文切换事件,而不显示调度器延迟。新的timehist命令有一个可视化(-V),可以包含唤醒事件。
Linux 4.10中增加了perf sched timehist,它按事件显示调度器延迟,包括任务等待被唤醒的时间(wait time)和唤醒后运行的调度器延迟(sch delay)。我们对调度器延迟更感兴趣。示例输出:
# perf sched timehist
Samples do not have callchains.
time cpu task name wait time sch delay run time
[tid/pid] (msec) (msec) (msec)
--------------- ------ ------------------------------ --------- --------- ---------
991962.879971 [0005] perf[16984] 0.000 0.000 0.000
991962.880070 [0007] :17008[17008] 0.000 0.000 0.000
991962.880070 [0002] cc1[16880] 0.000 0.000 0.000
991962.880078 [0000] cc1[16881] 0.000 0.000 0.000
991962.880081 [0003] cc1[16945] 0.000 0.000 0.000
991962.880093 [0003] ksoftirqd/3[28] 0.000 0.007 0.012
991962.880108 [0000] ksoftirqd/0[6] 0.000 0.007 0.030
991962.880256 [0005] perf[16999] 0.000 0.005 0.285
991962.880276 [0005] migration/5[39] 0.000 0.007 0.019
991962.880687 [0005] perf[16984] 0.304 0.000 0.411
991962.881839 [0003] cat[17022] 0.000 0.000 1.746
991962.881841 [0006] cc1[16825] 0.000 0.000 0.000
[...]
991963.885740 [0001] :17008[17008] 25.613 0.000 0.057
991963.886009 [0001] sleep[16999] 1000.104 0.006 0.269
991963.886018 [0005] cc1[17083] 19.998 0.000 9.948
该输出包括sleep命令,用于将perf本身的持续时间设置为1秒。请注意,sleep的等待时间是1000.104毫秒,因为我运行了“sleep 1”:这是它休眠等待计时器唤醒事件的时间。它的调度器延迟仅为0.006毫秒,在cpu上的时间为0.269毫秒。
timehist有许多选项,包括用于添加CPU可视化列的-V、用于添加迁移事件的-M以及用于唤醒事件的-w。例如:
# perf sched timehist -MVw
Samples do not have callchains.
time cpu 012345678 task name wait time sch delay run time
[tid/pid] (msec) (msec) (msec)
--------------- ------ --------- ------------------ --------- --------- ---------
991962.879966 [0005] perf[16984] awakened: perf[16999]
991962.879971 [0005] s perf[16984] 0.000 0.000 0.000
991962.880070 [0007] s :17008[17008] 0.000 0.000 0.000
991962.880070 [0002] s cc1[16880] 0.000 0.000 0.000
991962.880071 [0000] cc1[16881] awakened: ksoftirqd/0[6]
991962.880073 [0003] cc1[16945] awakened: ksoftirqd/3[28]
991962.880078 [0000] s cc1[16881] 0.000 0.000 0.000
991962.880081 [0003] s cc1[16945] 0.000 0.000 0.000
991962.880093 [0003] s ksoftirqd/3[28] 0.000 0.007 0.012
991962.880108 [0000] s ksoftirqd/0[6] 0.000 0.007 0.030
991962.880249 [0005] perf[16999] awakened: migration/5[39]
991962.880256 [0005] s perf[16999] 0.000 0.005 0.285
991962.880264 [0005] m migration/5[39] migrated: perf[16999] cpu 5 => 1
991962.880276 [0005] s migration/5[39] 0.000 0.007 0.019
991962.880682 [0005] m perf[16984] migrated: cc1[16996] cpu 0 => 5
991962.880687 [0005] s perf[16984] 0.304 0.000 0.411
991962.881834 [0003] cat[17022] awakened: :17020
[...]
991963.885734 [0001] :17008[17008] awakened: sleep[16999]
991963.885740 [0001] s :17008[17008] 25.613 0.000 0.057
991963.886005 [0001] sleep[16999] awakened: perf[16984]
991963.886009 [0001] s sleep[16999] 1000.104 0.006 0.269
991963.886018 [0005] s cc1[17083] 19.998 0.000 9.948
CPU visualization列(“012345678”)中有“s”表示上下文切换事件,“m”表示迁移事件,显示了事件的CPU。如果运行perf sched record -g,那么堆栈跟踪将在右侧的单行中附加(这里没有显示)。
输出中的最后一个事件包括那些与用于计算性能的“sleep 1”命令相关的事件。唤醒发生在991963.885734,而在991963.885740(6微秒后),CPU 1开始切换到睡眠进程。该事件的列仍然显示“:17008[17008]”表示cpu上的内容,但没有显示上下文切换的目标(睡眠)。它存在于原始事件中:
:17008 17008 [001] 991963.885740: sched:sched_switch: prev_comm=cc1 prev_pid=17008 prev_prio=120
prev_state=R ==> next_comm=sleep next_pid=16999 next_prio=120
991963.886005事件表明,在sleep运行时,perf命令收到了一个唤醒(几乎可以肯定,sleep会唤醒它的父进程,因为它终止了),然后我们在991963.886009上进行上下文切换,其中sleep停止运行,并打印出摘要:1000.104 ms waiting(“sleep 1”),0.006 ms调度器延迟,0.269 ms CPU运行时间。
在这里,我用上下文切换目标的细节装饰了timehist输出:
991963.885734 [0001] :17008[17008] awakened: sleep[16999]
991963.885740 [0001] s :17008[17008] 25.613 0.000 0.057 next: sleep[16999]
991963.886005 [0001] sleep[16999] awakened: perf[16984]
991963.886009 [0001] s sleep[16999] 1000.104 0.006 0.269 next: cc1[17008]
991963.886018 [0005] s cc1[17083] 19.998 0.000 9.948 next: perf[16984]
当睡眠结束时,一个等待的“cc1”进程随后执行。Perf运行在下面的上下文切换上,并且是描述文件中的最后一个事件(Perf终止)。我将其添加为perf的-n/–next选项(应该在Linux 4.11或4.12中实现)。
perf sched script dumps all events (similar to perf script):
# perf sched script
perf 16984 [005] 991962.879960: sched:sched_stat_runtime: comm=perf pid=16984 runtime=3901506 [ns] vruntime=165...
perf 16984 [005] 991962.879966: sched:sched_wakeup: comm=perf pid=16999 prio=120 target_cpu=005
perf 16984 [005] 991962.879971: sched:sched_switch: prev_comm=perf prev_pid=16984 prev_prio=120 prev_stat...
perf 16999 [005] 991962.880058: sched:sched_stat_runtime: comm=perf pid=16999 runtime=98309 [ns] vruntime=16405...
cc1 16881 [000] 991962.880058: sched:sched_stat_runtime: comm=cc1 pid=16881 runtime=3999231 [ns] vruntime=7897...
:17024 17024 [004] 991962.880058: sched:sched_stat_runtime: comm=cc1 pid=17024 runtime=3866637 [ns] vruntime=7810...
cc1 16900 [001] 991962.880058: sched:sched_stat_runtime: comm=cc1 pid=16900 runtime=3006028 [ns] vruntime=7772...
cc1 16825 [006] 991962.880058: sched:sched_stat_runtime: comm=cc1 pid=16825 runtime=3999423 [ns] vruntime=7876...
这些事件(“sched:sched_stat_runtime”等)都是可以直接使用perf记录检测的跟踪点。
正如我前面所展示的,这个原始输出可以用于比摘要命令更深入的挖掘。
Perf sched replay将获取记录的调度器事件,然后通过生成具有类似运行时和上下文切换的线程来模拟工作负载。用于测试和开发调度器更改和配置。不要对这个(和其他)工作负载重玩器太过信任:它们可以是一个有用的负载生成器,但很难完全模拟真实的工作负载。这里我使用-r -1运行replay,以重复工作负载:
# perf sched replay -r -1
run measurement overhead: 84 nsecs
sleep measurement overhead: 146710 nsecs
the run test took 1000005 nsecs
the sleep test took 1107773 nsecs
nr_run_events: 4175
nr_sleep_events: 4710
nr_wakeup_events: 2138
task 0 ( swapper: 0), nr_events: 13
task 1 ( swapper: 1), nr_events: 1
task 2 ( swapper: 2), nr_events: 1
task 3 ( kthreadd: 4), nr_events: 1
task 4 ( kthreadd: 6), nr_events: 29
[...]
task 530 ( sh: 17145), nr_events: 4
task 531 ( sh: 17146), nr_events: 7
task 532 ( sh: 17147), nr_events: 4
task 533 ( make: 17148), nr_events: 10
task 534 ( sh: 17149), nr_events: 1
------------------------------------------------------------
#1 : 965.996, ravg: 966.00, cpu: 798.24 / 798.24
#2 : 902.647, ravg: 966.00, cpu: 1157.53 / 798.24
#3 : 945.482, ravg: 966.00, cpu: 925.25 / 798.24
#4 : 943.541, ravg: 966.00, cpu: 761.72 / 798.24
#5 : 914.643, ravg: 966.00, cpu: 1604.32 / 798.24
[...]
6.8. eBPF
在Linux 4.4中,perf有一些增强的BPF支持(又名eBPF或简称“BPF”),在后续的内核中有更多支持。BPF使perf跟踪程序化,并将perf从一个带有后处理的计数和采样跟踪器变成一个完全在内核中可编程的跟踪器。
目前eBPF有一些限制,很难从perf中使用。情况一直在好转。目前访问eBPF的另一种更简单的方法是通过bcc Python接口,这在我的eBPF工具页面上有描述(Linux eBPF Tracing Tools (brendangregg.com))。在这个页面中,我将讨论perf。
Prerequisites
Linux 4.4 at least. Newer versions have more perf/BPF features, so the newer the better. Also clang (eg, apt-get install clang).
kmem_cache_alloc from Example
该程序跟踪内核kmem_cache_alloc()函数,仅当调用它的函数匹配指定的范围,并在内核上下文中过滤。您可以想象这样做是为了提高效率:不必跟踪所有的分配,这可能非常频繁,并增加大量的开销,您只需筛选感兴趣的内核调用函数范围,例如内核模块。作为例子,我将松散地匹配tcp函数,它们位于内存中的以下地址:
# grep tcp /proc/kallsyms | more
[...]
ffffffff817c1bb0 t tcp_get_info_chrono_stats
ffffffff817c1c60 T tcp_init_sock
ffffffff817c1e30 t tcp_splice_data_recv
ffffffff817c1e70 t tcp_push
ffffffff817c20a0 t tcp_send_mss
ffffffff817c2170 t tcp_recv_skb
ffffffff817c2250 t tcp_cleanup_rbuf
[...]
ffffffff818524f0 T tcp6_proc_exit
ffffffff81852510 T tcpv6_exit
ffffffff818648a0 t tcp6_gro_complete
ffffffff81864910 t tcp6_gro_receive
ffffffff81864ae0 t tcp6_gso_segment
ffffffff8187bd89 t tcp_v4_inbound_md5_hash
我假设这些函数是连续的,所以通过跟踪0xffffffff817c1bb0到0xffffffff8187bd89的范围,我匹配了大部分tcp。
这是我的BPF程序,kca_from.c:
#include <uapi/linux/bpf.h>
#include <uapi/linux/ptrace.h>
#define SEC(NAME) __attribute__((section(NAME), used))
/*
* Edit the following to match the instruction address range you want to
* sample. Eg, look in /proc/kallsyms. The addresses will change for each
* kernel version and build.
*/
#define RANGE_START 0xffffffff817c1bb0
#define RANGE_END 0xffffffff8187bd89
struct bpf_map_def {
unsigned int type;
unsigned int key_size;
unsigned int value_size;
unsigned int max_entries;
};
static int (*probe_read)(void *dst, int size, void *src) =
(void *)BPF_FUNC_probe_read;
static int (*get_smp_processor_id)(void) =
(void *)BPF_FUNC_get_smp_processor_id;
static int (*perf_event_output)(void *, struct bpf_map_def *, int, void *,
unsigned long) = (void *)BPF_FUNC_perf_event_output;
struct bpf_map_def SEC("maps") channel = {
.type = BPF_MAP_TYPE_PERF_EVENT_ARRAY,
.key_size = sizeof(int),
.value_size = sizeof(u32),
.max_entries = __NR_CPUS__,
};
SEC("func=kmem_cache_alloc")
int func(struct pt_regs *ctx)
{
u64 ret = 0;
// x86_64 specific:
probe_read(&ret, sizeof(ret), (void *)(ctx->bp+8));
if (ret >= RANGE_START && ret < RANGE_END) {
perf_event_output(ctx, &channel, get_smp_processor_id(),
&ret, sizeof(ret));
}
return 0;
}
char _license[] SEC("license") = "GPL";
int _version SEC("version") = LINUX_VERSION_CODE;
Now I’ll execute it, then dump the events:
# perf record -e bpf-output/no-inherit,name=evt/ -e ./kca_from.c/map:channel.event=evt/ -a -- sleep 1
bpf: builtin compilation failed: -95, try external compiler
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.214 MB perf.data (3 samples) ]
# perf script
testserver00001 14337 [003] 481432.395181: 0 evt: ffffffff81210f51 kmem_cache_alloc (/lib/modules/...)
BPF output: 0000: 0f b4 7c 81 ff ff ff ff ..|.....
0008: 00 00 00 00 ....
redis-server 1871 [005] 481432.395258: 0 evt: ffffffff81210f51 kmem_cache_alloc (/lib/modules/...)
BPF output: 0000: 14 55 7c 81 ff ff ff ff .U|.....
0008: 00 00 00 00 ....
redis-server 1871 [005] 481432.395456: 0 evt: ffffffff81210f51 kmem_cache_alloc (/lib/modules/...)
BPF output: 0000: fe dc 7d 81 ff ff ff ff ..}.....
0008: 00 00 00 00 ....
它工作了:“BPF输出”记录包含我们范围内的地址:0xffffffff817cb40f,等等。kmem_cache_alloc()是一个经常被调用的函数,因此它在一秒钟的跟踪中只匹配了几个条目,这表明它正在工作(我还可以放宽范围来确认它)。
Adding stack traces with -g:
# perf record -e bpf-output/no-inherit,name=evt/ -e ./kca_from.c/map:channel.event=evt/ -a -g -- sleep 1
bpf: builtin compilation failed: -95, try external compiler
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.215 MB perf.data (3 samples) ]
# perf script
testserver00001 16744 [002] 481518.262579: 0 evt:
410f51 kmem_cache_alloc (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9cb40f tcp_conn_request (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9da243 tcp_v4_conn_request (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9d0936 tcp_rcv_state_process (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9db102 tcp_v4_do_rcv (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9dcabf tcp_v4_rcv (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9b4af4 ip_local_deliver_finish (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9b4dff ip_local_deliver (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9b477b ip_rcv_finish (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9b50fb ip_rcv (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
97119e __netif_receive_skb_core (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
971708 __netif_receive_skb (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9725df process_backlog (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
971c8e net_rx_action (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
a8e58d __do_softirq (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
a8c9ac do_softirq_own_stack (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
28a061 do_softirq.part.18 (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
28a0ed __local_bh_enable_ip (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9b8ff3 ip_finish_output2 (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9b9f43 ip_finish_output (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9ba9f6 ip_output (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9ba155 ip_local_out (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9ba48a ip_queue_xmit (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9d3823 tcp_transmit_skb (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9d5345 tcp_connect (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9da764 tcp_v4_connect (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9f1abc __inet_stream_connect (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9f1d38 inet_stream_connect (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
952fd9 SYSC_connect (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
953c1e sys_connect (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
a8b9fb entry_SYSCALL_64_fastpath (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
10800 __GI___libc_connect (/lib/x86_64-linux-gnu/libpthread-2.23.so)
BPF output: 0000: 0f b4 7c 81 ff ff ff ff ..|.....
0008: 00 00 00 00 ....
redis-server 1871 [003] 481518.262670: 0 evt:
410f51 kmem_cache_alloc (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9c5514 tcp_poll (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9515ba sock_poll (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
485699 sys_epoll_ctl (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
a8b9fb entry_SYSCALL_64_fastpath (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
106dca epoll_ctl (/lib/x86_64-linux-gnu/libc-2.23.so)
BPF output: 0000: 14 55 7c 81 ff ff ff ff .U|.....
0008: 00 00 00 00 ....
redis-server 1871 [003] 481518.262870: 0 evt:
410f51 kmem_cache_alloc (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9ddcfe tcp_time_wait (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9cefff tcp_fin (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9cf630 tcp_data_queue (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9d0abd tcp_rcv_state_process (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9db102 tcp_v4_do_rcv (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9dca8b tcp_v4_rcv (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9b4af4 ip_local_deliver_finish (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9b4dff ip_local_deliver (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9b477b ip_rcv_finish (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9b50fb ip_rcv (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
97119e __netif_receive_skb_core (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
971708 __netif_receive_skb (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9725df process_backlog (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
971c8e net_rx_action (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
a8e58d __do_softirq (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
a8c9ac do_softirq_own_stack (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
28a061 do_softirq.part.18 (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
28a0ed __local_bh_enable_ip (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9b8ff3 ip_finish_output2 (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9b9f43 ip_finish_output (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9ba9f6 ip_output (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9ba155 ip_local_out (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9ba48a ip_queue_xmit (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9d3823 tcp_transmit_skb (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9d3e24 tcp_write_xmit (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9d4c31 __tcp_push_pending_frames (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9d6881 tcp_send_fin (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9c70b7 tcp_close (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
9f161c inet_release (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
95181f sock_release (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
951892 sock_close (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
43b2f7 __fput (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
43b46e ____fput (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
2a3cfe task_work_run (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
2032ba exit_to_usermode_loop (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
203b29 syscall_return_slowpath (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
a8ba88 entry_SYSCALL_64_fastpath (/lib/modules/4.10.0-rc8-virtual/build/vmlinux)
105cd __GI___libc_close (/lib/x86_64-linux-gnu/libpthread-2.23.so)
BPF output: 0000: fe dc 7d 81 ff ff ff ff ..}.....
0008: 00 00 00 00 ....
This confirms the parent functions that were matched by the range.
More Examples
XXX fill me in.
7. Visualizations
perf_events有一个内置的可视化:时间图表,以及通过其文本用户界面(TUI)和树状报告的文本风格可视化。下面两个部分展示了我自己的可视化:火焰图和热图。我使用的软件是github上的开源软件,从perf_events收集的数据中生成这些。
7.1. Flame Graphs(https://www.brendangregg.com/flamegraphs.html)
使用FlameGraph工具软件(https://github.com/brendangregg/FlameGraph)可以从perf_events profiling数据生成火焰图。这将可视化您在perf报告中看到的相同数据,并且可以使用任何perf。用堆栈跟踪捕获的数据文件(-g)。
Example
This example CPU flame graph shows a network workload for the 3.2.9-1 Linux kernel, running as a KVM instance (SVG, PNG):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IFLfzL3c-1682324813018)(perf examples.assets/image-20230424161053855.png)]
火焰图在x轴上显示样本总体,在y轴上显示堆栈深度。每个函数(栈帧)被绘制为一个矩形,其宽度与样本数量相关。请参阅CPU火焰图(CPU Flame Graphs)页面以获取这些工作原理的完整描述。
您可以使用鼠标来探索内核CPU时间花费的位置,快速量化代码路径并确定性能调优工作的最佳位置。这个例子显示,大部分时间花费在vp_notify()代码路径上,花费70.52%的cpu示例执行iowrite16(),这是由KVM管理程序处理的。这些信息对于指导KVM性能工作非常有用。
在裸机Linux系统上类似的网络工作负载看起来很不一样,因为首先网络工作不是通过virtio-net驱动程序处理的。
Generation
The example flame graph was generated using perf_events and the FlameGraph tools (this is the old-fashioned method for Linux 2.6.X onwards; see the later Newer perf section):
# git clone https://github.com/brendangregg/FlameGraph # or download it from github
# cd FlameGraph
# perf record -F 99 -ag -- sleep 60
# perf script | ./stackcollapse-perf.pl > out.perf-folded
# cat out.perf-folded | ./flamegraph.pl > perf-kernel.svg
第一个perf命令描述CPU堆栈,如前所述。我把频率调到99赫兹;我实际上是根据1000赫兹的剖面生成火焰图的,但我只会在你有理由加快速度的情况下使用它,因为这样会增加开销。这些示例保存在perf.data文件中,可以使用perf report查看:
# perf report --stdio
[...]
# Overhead Command Shared Object Symbol
# ........ ............... ..................... ...................................
#
72.18% iperf [kernel.kallsyms] [k] iowrite16
|
--- iowrite16
|
|--99.53%-- vp_notify
| virtqueue_kick
| start_xmit
| dev_hard_start_xmit
| sch_direct_xmit
| dev_queue_xmit
| ip_finish_output
| ip_output
| ip_local_out
| ip_queue_xmit
| tcp_transmit_skb
| tcp_write_xmit
| |
| |--98.16%-- tcp_push_one
| | tcp_sendmsg
| | inet_sendmsg
| | sock_aio_write
| | do_sync_write
| | vfs_write
| | sys_write
| | system_call
| | 0x369e40e5cd
| |
| --1.84%-- __tcp_push_pending_frames
[...]
从上到下阅读时,这棵树遵循火焰图。当使用-g/–call-graph(用于“caller”,而不是默认的“callee”)时,它会在自底向上读取时生成一个跟随火焰图的树。火焰图中最热的堆栈跟踪(@70.52%)可以在这个性能调用图中看到,它是前三个节点的乘积(72.18% x 99.53% x 98.16%)。
perf报告树(和ncurses导航器)在以文本形式显示这些信息方面做得很好。然而,文本也有局限性。输出通常不能放在一个屏幕中(如果在第一页中已经确定了大部分样本,你可以说它不需要放在一个屏幕中)。此外,识别最热门的代码路径需要读取百分比。有了火焰图,所有数据都会同时显示在屏幕上,最热门的代码路径作为最广泛的函数一目了然。
为了生成火焰图,perf脚本命令转储堆栈样本,然后通过stackcollapse-perf.pl聚合这些样本,并将每个堆栈折叠成单行。然后,该输出被flamegraph.pl转换为SVG。我添加了一个免费的“cat”命令,以明确flamegraph.pl可以处理管道的输出,其中可能包括用于过滤或预处理的Unix命令(grep、sed、awk)。
Piping
A flame graph can be generated directly by piping all the steps:
# perf script | ./stackcollapse-perf.pl | ./flamegraph.pl > perf-kernel.svg
实际上我不会这样做,因为我经常重新运行多次flamegraph.pl,这个单行代码会将所有内容执行多次。perf脚本的输出可能有几十mb,需要花费数秒来处理。通过向文件写入stackcollapse-perf.pl,您已经缓存了最慢的步骤,并且还可以编辑该文件(vi)以删除不重要的堆栈,例如CPU空闲线程。
Filtering
对于grep(1)来说,stackcollapse-perf.pl的每栈一行输出也很方便。例如:
# perf script | ./stackcollapse-perf.pl > out.perf-folded
# grep -v cpu_idle out.perf-folded | ./flamegraph.pl > nonidle.svg
# grep ext4 out.perf-folded | ./flamegraph.pl > ext4internals.svg
# egrep 'system_call.*sys_(read|write)' out.perf-folded | ./flamegraph.pl > rw.svg
我经常以这种方式省略cpu_idle线程,专注于消耗CPU资源的真正线程。如果我错过了这一步,cpu_idle线程通常会支配火焰图,挤压有趣的代码路径。
请注意,处理perf报告的输出比处理perf脚本更有效;更好的是,perf报告可以有一个报告样式(例如,“-g fold”),直接输出折叠的堆栈,避免了堆栈折叠-perf.pl的需要。甚至可以有一个perf模式直接输出SVG(这不是第一个;请参阅perf-timechart),尽管,这将错过能够grep折叠堆栈的价值(这是我经常使用的)。
在CPU火焰图页面中有更多perf_events CPU火焰图(https://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html#Examples)的例子,包括这些说明的摘要(https://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html#perf)。我还分享了一个使用perf处理块设备I/O火焰图的例子(https://www.brendangregg.com/FlameGraphs/offcpuflamegraphs.html#BlockIO)。
7.2. Heat Maps
由于perf_events可以为事件记录高分辨率的时间戳(微秒),因此可以从跟踪数据中获得一些延迟测量结果。
Example
The following heat map visualizes disk I/O latency data collected from perf_events (SVG, PNG):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oPovtU1f-1682324813019)(perf examples.assets/image-20230424162014297.png)]
将鼠标悬停在块上,以查看延迟随时间的分布。x轴是时间的推移,y轴是延迟,z轴(颜色)是在该时间和延迟范围内的I/O数量。分布是双峰的,底部的黑线表示许多磁盘I/O以亚毫秒的延迟完成:缓存命中。随机磁盘I/O(和排队)导致的磁盘I/O云大约在3 ms到25 ms之间。这两种模式的平均时间为9 ms。
在收集热图数据的同时,还收集了以下iostat输出(显示了一个典型的1秒摘要):
# iostat -x 1
[...]
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 0.00 334.00 0.00 2672.00 0.00 16.00 2.97 9.01 9.01 0.00 2.99 100.00
此工作负载的平均I/O时间(await)为9毫秒,这听起来像是在7200 RPM磁盘上相当随机的工作负载。问题是我们不知道iostat输出的分布,也不知道任何类似的平均延迟。可能存在延迟异常值,这在平均值中是不可见的,但会导致问题。热图显示I/O时间长达50毫秒,这可能是iostat输出所没有预料到的。也可以有多种模式,正如我们在热图中看到的那样,这些模式在平均值上也不可见。
Gathering
我使用perf_events来记录块请求(磁盘I/O)的发出和完成静态跟踪点:
# perf record -e block:block_rq_issue -e block:block_rq_complete -a sleep 120
[ perf record: Woken up 36 times to write data ]
[ perf record: Captured and wrote 8.885 MB perf.data (~388174 samples) ]
# perf script
[...]
randread.pl 2522 [000] 6011.824759: block:block_rq_issue: 254,16 R 0 () 7322849 + 16 [randread.pl]
randread.pl 2520 [000] 6011.824866: block:block_rq_issue: 254,16 R 0 () 26144801 + 16 [randread.pl]
swapper 0 [000] 6011.828913: block:block_rq_complete: 254,16 R () 31262577 + 16 [0]
randread.pl 2521 [000] 6011.828970: block:block_rq_issue: 254,16 R 0 () 70295937 + 16 [randread.pl]
swapper 0 [000] 6011.835862: block:block_rq_complete: 254,16 R () 26144801 + 16 [0]
randread.pl 2520 [000] 6011.835932: block:block_rq_issue: 254,16 R 0 () 5495681 + 16 [randread.pl]
swapper 0 [000] 6011.837988: block:block_rq_complete: 254,16 R () 7322849 + 16 [0]
randread.pl 2522 [000] 6011.838051: block:block_rq_issue: 254,16 R 0 () 108589633 + 16 [randread.pl]
swapper 0 [000] 6011.850615: block:block_rq_complete: 254,16 R () 108589633 + 16 [0]
[...]
perf脚本的完整输出约为70,000行。我在这里包含了一些,以便您可以看到可用的数据类型。
Processing
为了计算每个I/O的延迟,我需要将issue和completion事件配对,这样我就可以计算时间戳增量。这些列看起来很直观(在include/trace/events/block.h中),第4个字段是以秒为单位的时间戳(微秒分辨率),第6个字段是磁盘设备ID (major, minor),后一个字段(根据跟踪点变化)有磁盘偏移量。我将使用磁盘设备ID和偏移量作为唯一标识符,假设内核不会向完全相同的位置发出并发I/O。
我将使用awk进行这些计算,并打印出完成时间和延迟:
# perf script | awk '{ gsub(/:/, "") } $5 ~ /issue/ { ts[$6, $10] = $4 }
$5 ~ /complete/ { if (l = ts[$6, $9]) { printf "%.f %.f\n", $4 * 1000000,
($4 - l) * 1000000; ts[$6, $10] = 0 } }' > out.lat_us
# more out.lat_us
6011793689 8437
6011797306 3488
6011798851 1283
6011806422 11248
6011824680 18210
6011824693 21908
[...]
为了让下一步更容易,我将这两列都转换为微秒数。
Generation
Now I can use my trace2heatmap.pl program (github), to generate the interactive SVG heatmap from the trace data (and uses microseconds by default):
# ./trace2heatmap.pl --unitstime=us --unitslat=us --maxlat=50000 out.lat_us > out.svg
When I generated the heatmap, I truncated the y scale to 50 ms. You can adjust it to suit your investigation, increasing it to see more of the latency outliers, or decreasing it to reveal more resolution for the lower latencies: for example, with a 250 us limit.
Overheads
虽然这样做很有用,但要注意开销。在我的例子中,我有一个低速率的磁盘I/O(大约300 IOPS),它在2分钟后生成一个8 mb的跟踪文件。如果磁盘的IOPS是它的100倍,跟踪文件也会是它的100倍,收集和处理的开销就会增加。
有关延迟热图的更多信息,请参阅我的LISA 2010演示幻灯片(http://www.slideshare.net/brendangregg/lisa2010-visualizations)和我的CACM 2010文章(http://cacm.acm.org/magazines/2010/7/95062-visualizing-system-latency/fulltext),它们都是关于热图的。请参阅我的性能热图博客文章(https://www.brendangregg.com/blog/2014-07-01/perf-heat-maps.html)。

















 2297
2297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}