



 本文介绍Pandas库中的Series对象,包括声明、元素选择与赋值、运算及数学函数应用等核心功能。同时探讨如何筛选元素、了解元素构成,并提供实用示例。
本文介绍Pandas库中的Series对象,包括声明、元素选择与赋值、运算及数学函数应用等核心功能。同时探讨如何筛选元素、了解元素构成,并提供实用示例。
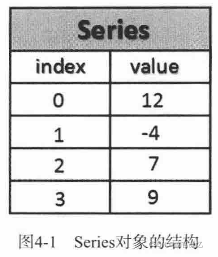
pandas库的Scries对象用来表示一维数据结构,由两个相互关联的数组组成。主数组用来存放数据,主数组的每个元素都有一个与之相关联的标签,这些标签存储在另外一个叫作Index的数组中。
1、声明Series对象
调用Series()构造函数,把要存放在Series对象中的数据以数组形式传入。

Series的输出:左侧Index是一列标签,右侧是标签对应的元素。
声明Series时,若不指定标签,pandas默认使用从0开始依次递增的数值作为标签。
然而,最好使用有意义的标签,用以区分和识别每个元素,因此,调用构造函数时,可以指定index选项,把存放有标签的数组赋给它,其中标签为字符串类型。

如果想分别查看组成Series对象的两个数组,可像下面这样调用它的两个属性:index(索引)和values(元素)。

2、选择内部元素
指定键或者指定位于索引位置处的标签。
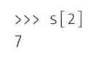
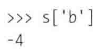
选择多个元素的方法与NumPy相同

或者,使用元素对应的标签(放到数组中)

3、为元素赋值
用索引或标签选取元素后进行赋值

4、用NumPy数组或其他Series对象定义新Series对象


新Series对象中的元素不是原NumPy数组或Series对象元素的副本,而是对它们的引用。如改变原有对象元素的值,新Series对象中这些元素也会发生改变。
5、筛选元素
如要获取Series对象中所有大于8的元素,可使用以下代码:

6、Series对象运算和数学函数
适用于NumPy数组的运算符(+、-、*、/)或其他数学函数,也适用于Series对象

至于NumPy库的数学函数,必须指定它们的出处np,并把Series实例作为参数传入

7、Series对象的组成元素
Series对象往往包含重复的元素,你很可能想知道里面都包含哪些元素,统计元素重复出现的次数或判断一个元素是否在Series中。
首先,声明一个包含多个重复元素的Series对象。

unique()函数:帮助弄清楚Series对象包含多少个不同的元素,其返回Series去重后的元素,顺序比较随意。

value_counts()函数:不仅返回各个不同的元素,还计算每个元素在Series中的出现次数。

isin()函数:判断给定的一列元素是否包含在数据结构之中,其返回结果是布尔值,可用于筛选Series或DataFrame列中的数据。


















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









