







文章目录
基础铺垫:
pandas简介:
pandas是一种Python数据分析的利器,是一个开源的数据分析包。此文讲述常用(关键)部分,其余请查阅官方文档
使用pandas需要引入约定:(文中将不再赘述)
from pandas import Series, DataFrame
import pandas as pd
pandas基本数据结构:
1. pandas中主要有两种数据结构,分别是:Series和DataFrame。
2. Series:一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。注意:Series中的索引值是可以重复的。
3. DataFrame:一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
Series:
Series创建:
创建方式有两种:
1. 通过以为数组方式创建
2. 通过字典的方式创建(此时key变成索引,value变成了值)
如图:


Series索引:
添加索引的方式有两种:一是创建series后再添加index,二是创建series的同时添加index属性(index最好是规律性的,之后好切片取值),如图:

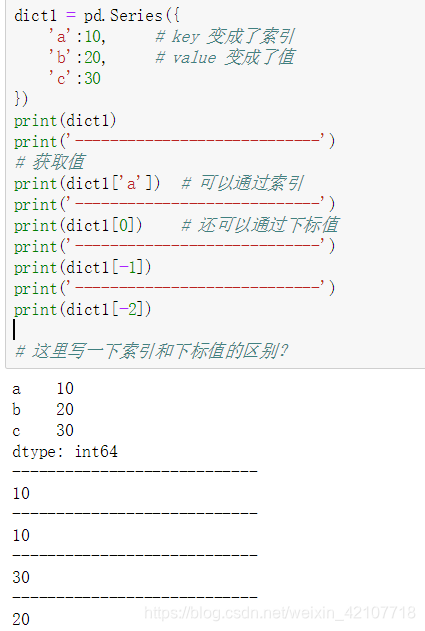
Series值的获取:
1. 通过方括号+索引的方式读取对应索引的数据,有可能返回多条数据
2. 通过方括号+下标值的方式读取对应下标值的数据,下标值的取值范围为:[0,len(Series.values));另外下标值也可以是负数,表示从右往左获取数据
说明:Series的索引是可以重新定义的,下标是不变的(0开始),固是两种方法。如图:
3. Series获取多个值的方式类似NumPy中的ndarray的切片操作,通过方括号+下标值/索引值+冒号(:)的形式来截取series对象中的一部分数据。(索引和下标切片的时候,区间取得是不同的!)如图:

Series运算:
NumPy中的数组运算,在Series中都保留了,均可以使用,并且Series进行数组运算的时候,索引与值之间的映射关系不会发生改变。
注意:其实在操作Series的时候,基本上可以把Series看成NumPy中的ndarray数组来进行操作。ndarray数组的绝大多数操作都可以应用到Series上。如图:

Series 缺失值检测:
什么是缺失值?缺失值的产生?
简单来说,Pandas中的NaN(not a number)就表示一个缺失值,通常因计算时候索引不对应 或 没有为其赋值 产生,如图:

缺失值如何检测?如何处理?
pandas中的isnull和notnull两个函数可以用于在Series中检测缺失值,这两个函数的返回时一个布尔类型的Series,如图(继续上图操作):

Series自动对齐:
当多个series对象之间进行运算的时候,如果不同series之间具有不同的索引值,那么运算会自动对齐不同索引值的数据,如果某个series没有某个索引值,那么最终结果会赋值为NaN。如图:

Series及其索引的name属性:
Series对象本身以及索引都具有一个name属性,默认为空,根据需要可以进行赋值操作。如图:

至此,Series部分基本讲解完毕,请到下节DataFrame篇















 3411
3411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









