






一、tf.data简介
从读取数据到数据传入加速设备(GPU或TPU)的流程被称为输入管道(Input Pipeline)。TensorFlow提供tf.data API,可以帮助使用者打造灵活有效的输入管道,轻松处理大量数据、不同数据格式及复杂的转换。
输入管道可以分为以下3个步骤:
1、提取(Extraction)
从存储的地方(可以是SSD、HDD或远程存储位置)读取数据。
2、转换(Transformation)
使用CPU进行数据预处理,例如对图像进行翻转、裁剪、缩放和正则化等。
3、载入(Loading)
将转换后的数据加载到机器学习模型的加速设备。
上面这3个步骤主要是设备读取数据和CPU预处理在消耗时间,如果没有妥善地分工处理,就会造成当CPU在准备数据时,GPU在等待训练数据的产生(GPU处于空闲状态);反之,当GPU在训练时,CPU则处于空闲状态,如图2-16所示。如此,训练时间就会增加很多。

TensorFlow提供tf.data API,通过使用tf.data.Dataset.prefetch,行指令就可以让生成数据与训练数据同时进行,进而提升训练效率,如图2-17所示。

倘若输入管道的执行时间远比训练时间久,将发生如图2-18所示的情况,造成GPU或TPU加速器无法发挥全部的运算力,通常这种情况可能是读取文件太大或数据预处理太久造成的。

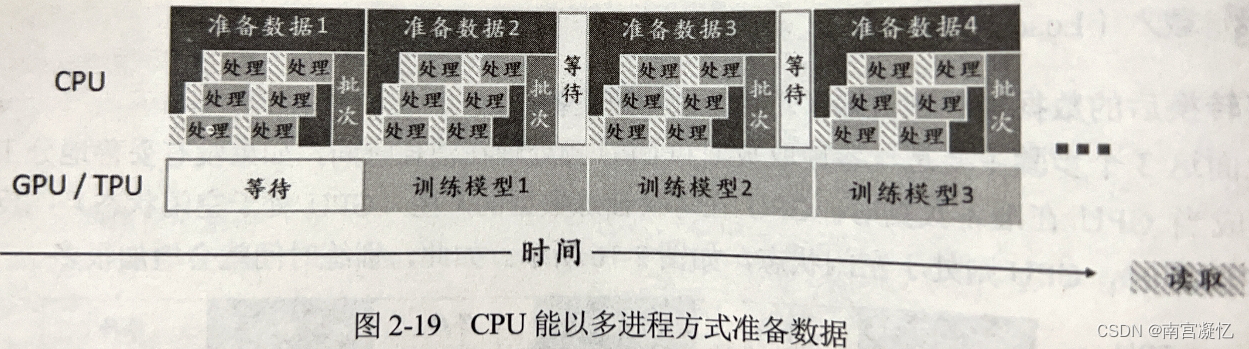
上述问题可以使用CPU多线程来解决,只需在调用map方法时加入 num parallel_calls 设置,即可启用并行处理数据的功能。通常num parallel_calls 会设置成计算机的核心数,图2-19所示为改善后的工作情况。
二、基本操作
import tensorflow as tf
import os
def _parse_function(filename, label):
image_string = tf.compat.v1.read_file(filename)
# 将图像使用JPEG的格式解码从而得到图像对应的三维矩阵。
image_decoded = tf.image.decode_jpeg(image_string,channels=3)
# 通过tf.image.resize_images函数调整图像的大小。
image_resized = tf.compat.v1.image.resize_images(image_decoded, [224, 224])
return image_resized, label
file_path = r'E:\修图作品\2022-6-16'
data = [os.path.join(file_path,i) for i in os.listdir(file_path)]
label = [0]*len(data)
dataset = tf.data.Dataset.from_tensor_slices((data,label))
dataset = dataset.map(_parse_function) #map对数据集应用自定义函数
dataset = dataset.batch(40) #设置每一批读取的数据量
dataset = dataset.repeat(2) #设置可以重复读取dataset n次
iterator = iter(dataset)
while 1:
try:
image, _ = next(iterator)
print(image.shape)
except StopIteration: # python内置的迭代器越界错误类型
print("iterator done")
break;
'''
len(data) = 93
40+40+13=93
'''















 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









