







目录
tf.data这个是处理数据用的
首先我们导入库
![]()
1 创建数据集
1.1 一维数据
我们现在使用from_tensor_slices把[1,2,3,4,5,6,7]这个列表作为数据集
![]()
然后我们显示出来看一下
![]()
我们可以发现这个没有办法直接显示出来,其中的shapes是代表每一个元素的shape,由于我们每一个元素是数字,所以shape是()
![]()
这个对象是可以遍历的,我们遍历一下

我们发现每一个对象都是tf,Tensor类型的

我们可以将其转换为numpy类型


1.2 二维数据
我们现在再将一个二维的列表作为数据集,这个时候我们就不能加7了,因为tf.data.Dataset要求每一个元素的形状与属性相同
![]()
如果是下面这样的话会报错
![]()
我们看一下dataset
![]()
由于我现在的元素长度为2,所以现在的shaps显示为(2,),如果里面都有三个元素,那么shapes就为(3,)
![]()
然后再遍历dataset


1.3 字典建立dataset
每个元素的形状要相同,不然会报错

我们看一下刚刚创建的数据集
![]()
我们看一下它的shapes,shapes是一个字典,括号的意思是字典的值只有单一数字
![]()
我们遍历一遍dataset_dic
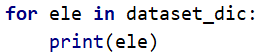
dataset_dic中一共有四个元素,每一个大括号算一个元素,每一个尖括号中的numpy是该键所对应的值

1.4 np.array建立dataset
效果与直接使用列表相同
首先导入numpy
![]()
![]()
看一下dataset整体
![]()
![]()
遍历


我们可以使用take的方法取出前指定个数的数据,比如我现在想取出前4个数据


2 数据集变化
2.1 乱序数据集 shuffle()
将数据集乱序后在训练过程中,数据集中的数据顺序对结果的影响会大大降低
我们使用shuffle()进行乱序,参数是我们要乱序的个数,我们现在想将其所有内容都乱序

此时dataset的类型变为了ShuffleDataset
![]()
遍历结果

2.2 循环数据集 repeat()
2.2.1 无限循环

现在我们的数据集类型变为RepearDataset
![]()
我们的效果是先乱序,后循环

由于我们使用for循环没有设置终止条件,所以它会无限的循环下去,也就是说dataset此时是无限长的数据集,我通过pycharm的暂停使它停止

2.2.2 有限循环
在repeat()中输入循环次数就可以达到有限循环的效果,我们现在想让其循环3次,也就是说我们现在dataset的长度是21

![]()


- 只截取了一头一尾
2.3 设置批次 batch()
当我们的数据集中的数据较多时,我们的内存无法将所有数据集中的数据一次都传进来,这个时候我们要定义批次
我们使用batch()定义批次,现在我们让3个数据在一个批次中

![]()
由于只循环了三次所以到这里就停止了

2.4 数值处理map()
我们可以对数据集中的数据进行同一的处理,比如说我下面对数据集中的所有数据进行平方运算

![]()

map()中的参数为要进行的算法,在tf中内置了,需要什么算法可以用的时候去网上查一下
















 215
215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











